
Sigmoid and Softmax Are Not Implemented the Way Most People Think
Avoid numerical instability with manipulations.

Sigmoid, as you may already know, is popularly used in binary classification problems to generate probabilistic estimates.

It maps any real-valued number z∈R to a value between 0 and 1.
The most common way one would write a custom implementation for Sigmoid is as follows:

However, there is a big problem with this specific implementation, which is why most frameworks don’t implement it this way.
More specifically, if the input to this function is a large negative value, it can raise overflow errors/warnings:

The issue is quite obvious to identify as for large negative inputs, the exponent term in the function (e^(-z)) becomes increasingly large.

That is why in all popular Sigmoid implementations (say, in PyTorch), Sigmoid is not implemented this way.
Instead, they use a smart technique that manipulates the Sigmoid implementation as follows:

As shown above, we transfer the exponent term to the numerator instead.
This solves the overflow issue we noticed earlier:

Of course, manipulating the Sigmoid this way introduces another pitfall when we use it for large positive values:

That is why typical implementations use both versions of Sigmoid, one for positive values and another for negative values, as demonstrated below:

Using the standard Sigmoid prevents overflow that may occur for negative inputs.
Using the rearranged Sigmoid prevents overflow that may occur for positive inputs.
Plotting the exponent values that appear in this various of Sigmoid (the variable “a” above), we get the following:

The exponent term is always constrained between 0 and 1, which helps us prevent overflow errors and maintain numerical stability.
In fact, a similar technique is also used in the implementation of the Softmax function.
We know that Softmax for a particular label (i) is computed using the activations as follows:
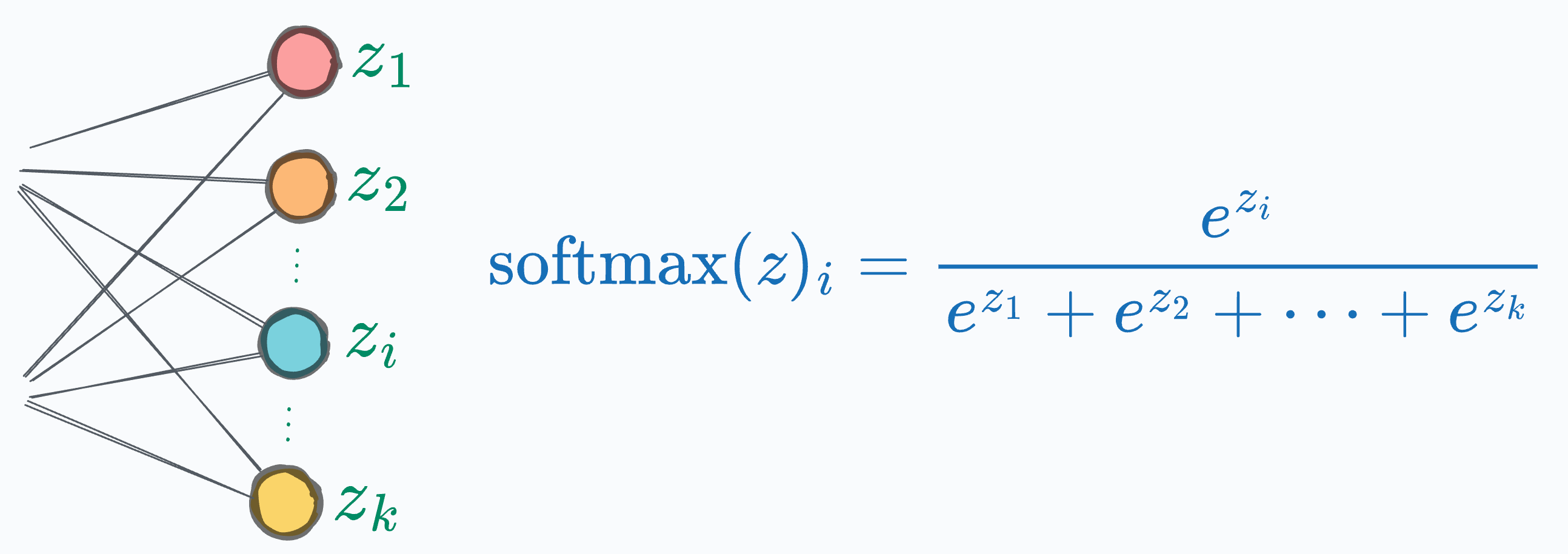
As you may have already guessed, if any of the output activations happen to be a large positive number, its exponent computations can lead to overflow errors.

Here’s what we do to avoid this.
Find the maximum input activation and subtract it from all activations:

This does not alter the output probabilities at all because it’s like dividing the numerator and denominator of the Sigmoid function with the same factor:

This prevents the numerical instability that could have appeared otherwise.
That said, please note that the commonly used frameworks, like Pytorch, already take care of these things, so you don’t have to worry.
However, if you have written a custom implementation somewhere, consider rectifying it.
👉 Over to you: What are some ways numerical instability may arise in training neural networks?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
I'm doing 3rd year engineering where I'm studying data science... I'm learning things here that they would never teach in college... Daily dose of Data Science is awesome ❤️
What about underflow? Could exp(-1000) be too small to represent?