
Simplify ML/GenAI Workflows with Simplismart
The fastest inference engine for ML/GenAI workloads.

TL;DR: 90% ML models don’t reach production. Simplismart flips that statistic.
Discover how it helps you avoid deployment hurdles and reduces costs, all while delivering world’s fastest ML/GenAI inference (400 tokens/second), outperforming giants like AWS and Azure. Book a demo →
Let’s dive in!
ML model deployment is tedious.
Several enterprises have specialized teams whose ONLY job is to take models from the ML team, productionize, scale, and deploy them.
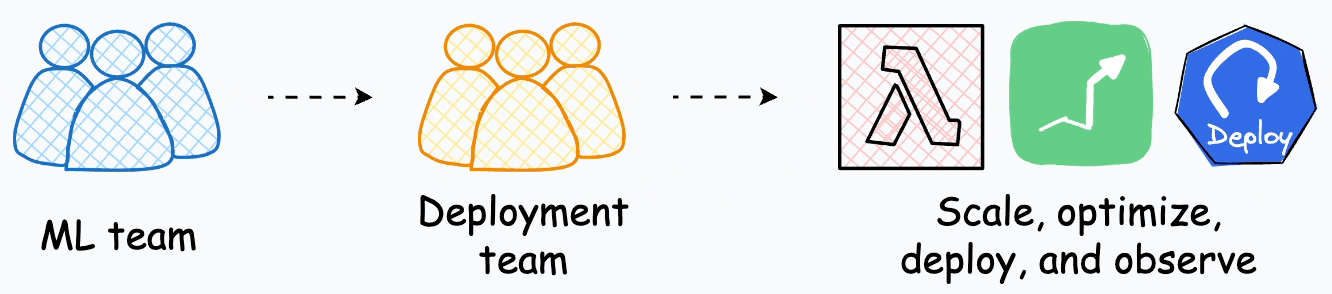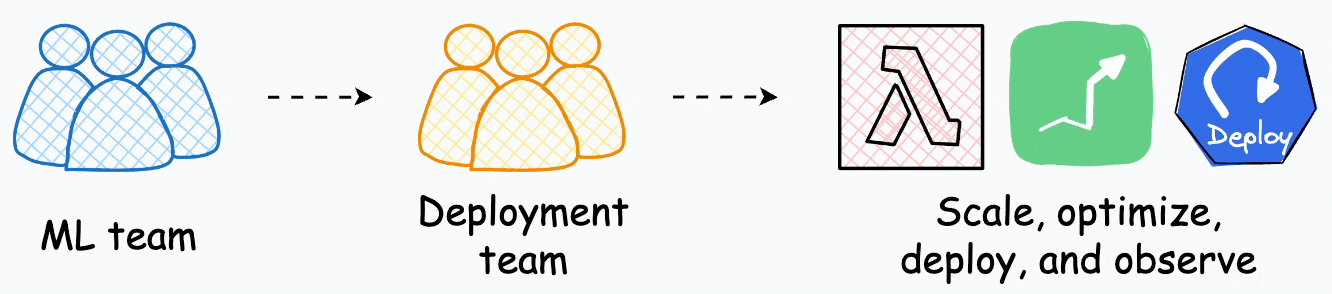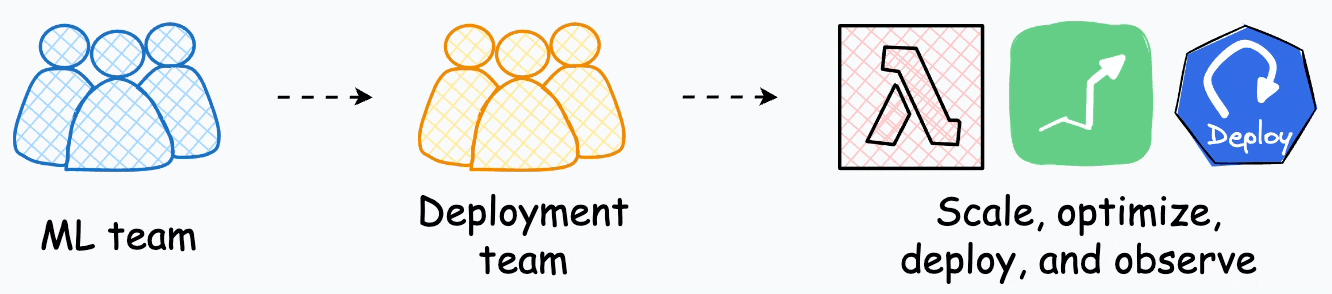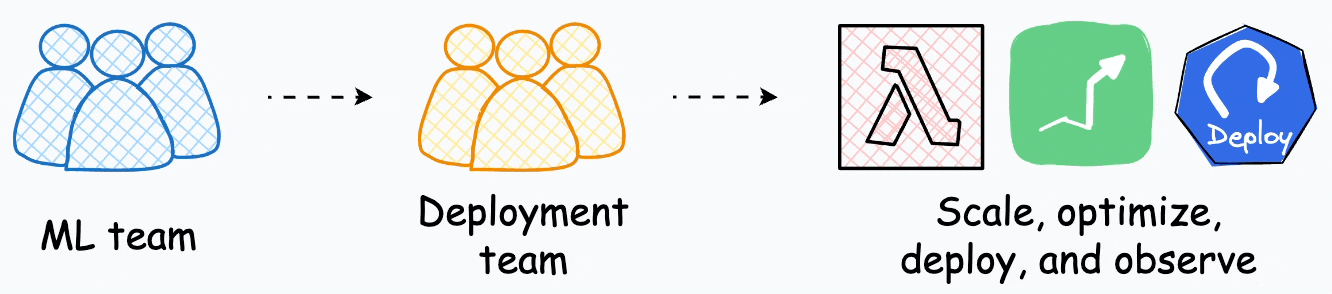
This shows the amount of effort that goes into deployment, and it feels justified to have specialized teams who just handle deployments.
Thankfully, this is changing, and taking models to production is becoming simpler, faster, cheaper, and most importantly, without needing specialized teams.

Today, I want to tell you about Simplismart, an end-to-end MLOps workflow orchestration platform that allows you to:
Train (or fine-tune) ANY model (LLMs, traditional NNs, etc.)
Deploy it across any cloud provider and hardware
And observe the model’s performance…
…without worrying about operational overheads, that too at increased inference speeds and much lower costs.
As per public benchmarks, Simplismart is the fastest inference engine in the world for ML/GenAI workloads running on NVIDIA chips:

Let’s learn more about Simplismart today.
The problem
A big reason why deployments tend to be tedious is that these processes are hardly standardized.
In other words, very few enterprises have well-defined orchestration layers that start from fine-tuning to optimally deploying a model and then observing it in production.
There’s another problem.
Imagine your team is currently reliant on Azure as a cloud provider.
But you have been asked to migrate to AWS.

Now you must adapt your whole deployment process specific to the new cloud provider and its ecosystem.
This is especially concerning for people in AI/ML because, typically, their core work does not revolve around managing cloud infrastructure.
One solution is to outsource the AI to API providers.
However, most enterprises prefer to “own” their AI since they don’t want their data to leave their cloud.
What is Simplismart?
Simplismart is an end-to-end MLOps workflow orchestration platform that solves the above problems by streamlining the entire deployment lifecycle of an ML project.
It does this by standardizing the deployment workflows using a declarative language similar to Terraform.

To simplify a bit, it’s like bringing ANY model of your choice trained using ANY framework and deploying it across ANY cloud provider or hardware, as depicted below:

Simplismart handles everything beyond that.
This way, ML teams can do the only thing they are supposed to do—build AI applications and develop solutions without caring about deployment overheads, which reduces the time to production.
Isn’t that cool?
A practical example
Let’s consider a real-life example to understand how Simplismart streamlines the end-to-end process:
#1) Traditional Fine-tuning vs. SimpliTune
Consider you want to fine-tune a pre-trained model to your dataset.
Traditionally, you would do the following:
Launch a cluster.
Prepare the dataset.
Load a pre-trained model.
Implement multi-GPU training.
Implement LoRA/QLoRA for efficient fine-tuning, etc.
With Simplismart, you can fine-tune multiple models simultaneously on your own datasets with the click of a few buttons:

#2) Traditional Deployment vs. SimpliDeploy
Now consider you want to deploy the model above.
Traditionally, you would do the following:
Launch a cloud instance.
Configure the environment, including dependencies and libraries.
Set up autoscaling to handle varying traffic.
Optimize the model for inference (using quantization, etc.)
With Simplismart, select the model (the one we fine-tuned above or any open-source model like Llama, Mistral, Whisper, etc.), the hardware you want to run it on, apply quantization during inference, select the cloud provider, and deploy!

#3) Traditional Observability vs. SimpliObserve
Next, you need observability procedures to understand how the model is performing in production, its resource utilization, etc.
Traditionally, one would manually integrate tools like Weights & Biases into their training scripts.
With Simplismart, every deployed model has an observability dashboard for tracking model responses, inference speed, and quality issues.

Pretty handy and incredible, isn’t it?
A departing note
I have always believed that ML deserves the rigor of any software engineering field.
If you have deployed an ML model before, you might know the amount of effort that goes into debugging pipelines, scaling infrastructure, and optimizing models for performance.
The thing I love about Simplismart is that it eases out the repetitive tasks for ML teams so they can focus on what they are supposed to do—develop and train models.
This reduces the time to scale and deploy machine learning from weeks to just a few minutes (or hours).
Everything is built into the platform, which can either be hosted on-premise or available as dedicated or shared endpoints, as per your requirements.
The team is launching an SDK, which you can use to test the quality of multiple GenAI models and push your deployments into production.
Also, to reiterate, as per public benchmarks, Simplismart is now offering the fastest inference engine in the world for ML/GenAI workloads, which means lesser compute costs—saving money for enterprises:

So not only does it abstract the tedious workflows, but it also ensures that your models are heavily optimized for inference, which dramatically reduces the operational costs, as depicted below:

I love Simplismart’s mission of supporting machine learning and data science teams in simplifying their end-to-end machine learning deployment workflows without worrying about any challenges.
They are solving a big problem in existing GenAI/ML workflows, and I’m eager to see how they continue!
Schedule a demo with the team here: Simplismart demo call.
🙌 Also, a big thanks to Simplismart, who very kindly partnered with me on this post and let me share my thoughts openly.
👉 Over to you: What are other pain points in machine learning deployments?
SPONSOR US
Get your product in front of 105,000+ data scientists and machine learning professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience