
Solving the Engineering Productivity Paradox!
...and how to make production-grade vibe-coding actually work for you!

Black Friday came early. Access every LLM for up to 70% less!
Lightning AI’s unified Model API makes it simple to switch between 20+ LLMs in one line of code.
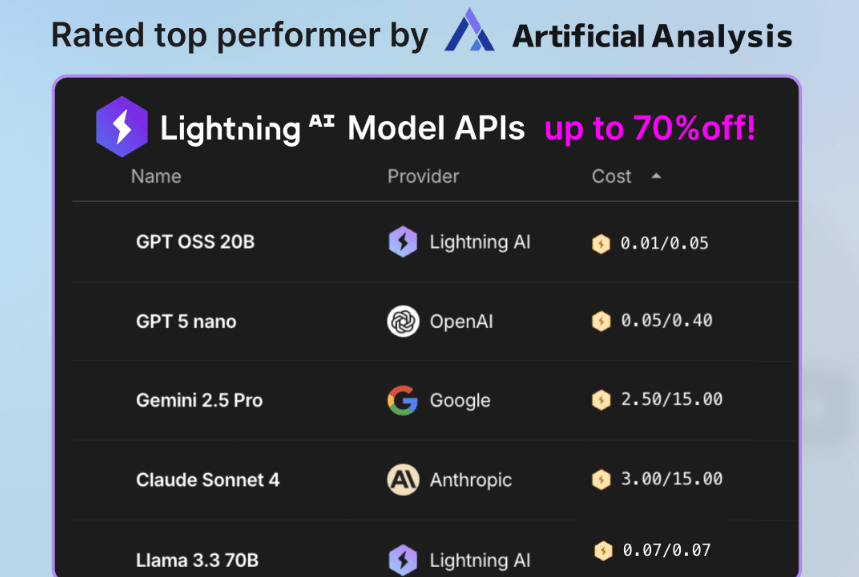
With unified billing, built-in fallbacks, and transparent usage tracking.
For a limited time, you can build, test, and deploy with any model for 70% less. No lock-in. No hidden costs. Just faster experimentation.
Thanks to Lightning for partnering today!
A serious bottleneck in production-grade vibe-coding!
You’re in a tech lead interview at Google.
The interviewer asks:
“AI generates 30% of our code now.
But our engineering velocity has only increased by 10%.
How would you fill this gap?”
You: “Using AI code reviewers will solve this.”
Interview over!
Here’s what you missed:
Many engineers think the solution to AI bugs is more AI.
Their mental model is simple: “If AI can write it, AI can review it.”
But if AI could catch these issues, why didn’t it write correct code in the first place?
There’s enough evidence to suggest that both AI reviewers and AI generators share the same fundamental blind spots:
They pattern match, not proof check.
They validate syntax, not system behavior.
They review code, not consequences.
This is because they’re both trained on the same Stack Overflow answers, the same GitHub repos, the same patterns that look right but fail in production.
So even though AI is now generating code at light speed, the bottleneck has just moved from writing to reviewing, and now devs spend 90% of their debugging time on AI-generated code.
So how are companies actually closing this gap?
They stop treating verification as pattern matching and instead, build workflows that look like this:
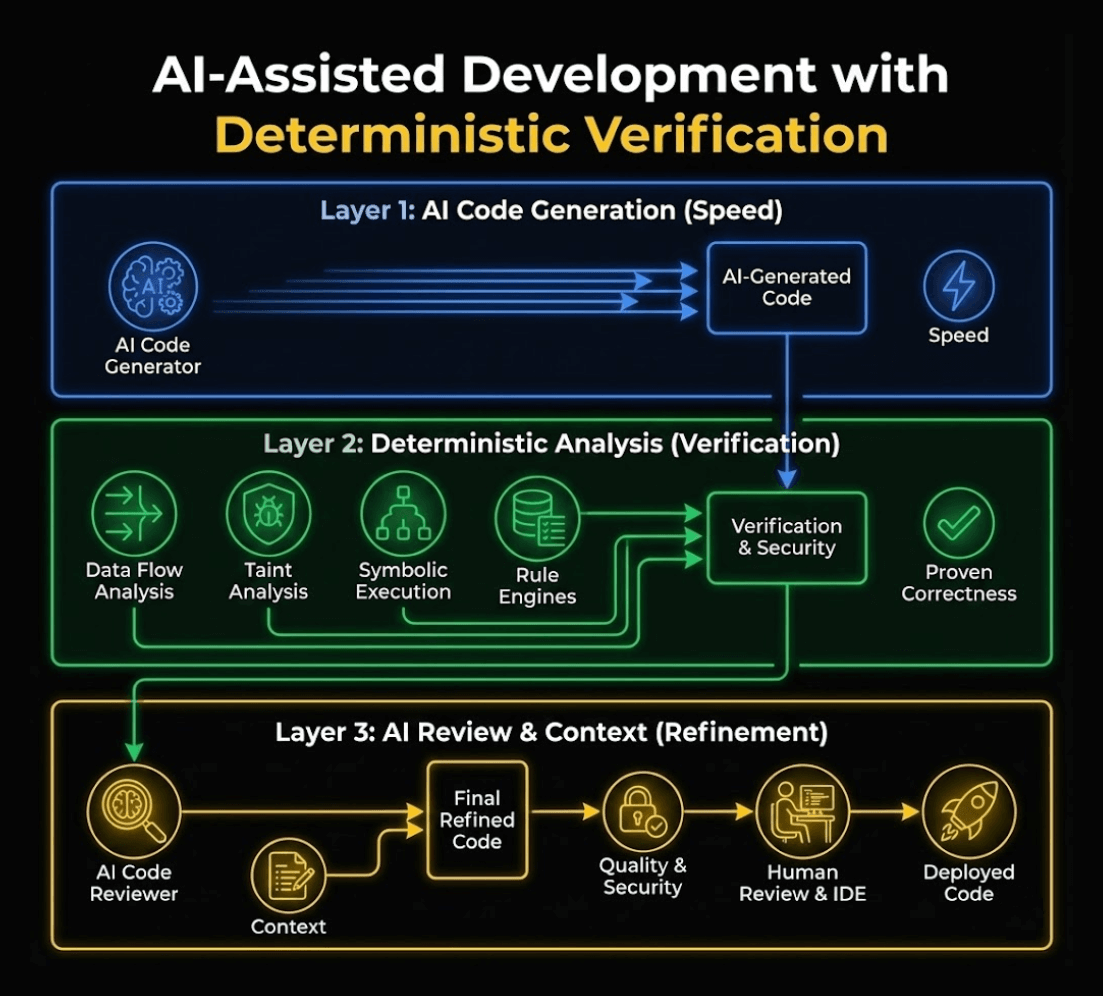
Layer 1: AI generates at speed (as usual).
Layer 2: Deterministic analysis based on:
Data flow analysis tracks every variable’s journey
Taint analysis proves security vulnerabilities
Symbolic execution finds edge cases AI never imagined
Rule engines built from millions of production failures
Layer 3: AI review adds context
All three layers are scalable, and this is exactly what’s closing the productivity gap.
If you want to see it in practice, this full approach is actually implemented by Sonar in SonarQube, a popular tool that solves quality and security issues of your code, long before AI made it critical.
Its capabilities have emerged from the 750B+ lines of code SonarQube processes daily, so it has seen every bug pattern that exists.
Essentially, instead of AI guessing what might be wrong, SonarQube proves what is wrong by detecting the exact vulnerabilities in your code using the techniques mentioned in Layer 2.
These insights are then directly streamed as real-time feedback in your AI-powered IDEs.
Here’s how we use it:
Claude Code and Cursor for speed
and SonarQube for guardrails
That said, you can also integrate Sonar into your CI/CD pipeline.
Here’s a resource that explains the AI coding bottlenecks →
P.S. Huge thank you to Sonar for showing us what they have built and partnering today! We will cover this in more detail in a follow-up post next week!
NVIDIA’s approach merges Autoregression and Diffusion
NVIDIA just dropped a paper that might solve the biggest trade-off in LLMs.
Speed vs. Quality.
Autoregressive models (like GPT) are smart but slow - they generate one token at a time, leaving most of your GPU sitting idle.
Diffusion models are fast but often produce incoherent outputs.
TiDAR gets you both in a single forward pass.

Here’s the genius part:
Modern GPUs can process way more tokens than we actually use. TiDAR exploits these “free slots” by:
Drafting multiple tokens at once using diffusion (the “thinking” phase)
Verifying them using autoregression (the “talking” phase)
Both happen simultaneously using smart attention masks - bidirectional for drafting, causal for verification.
This results in:
↳ 4.71x faster at 1.5B parameters with zero quality loss
↳ Nearly 6x faster at 8B parameters
↳ First architecture to outperform speculative decoding (EAGLE-3)
↳ Works with standard KV caching, unlike pure diffusion models
The training trick is clever too - instead of randomly masking tokens, they mask everything. This gives stronger learning signals and enables efficient single-step drafting.
If you’re building real-time AI agents where latency kills the experience, this architecture is worth paying attention to.
You can read the paper here →
Thanks for reading!
still need to try out vibe coding