


Spark != Pandas + Big Data Support
Extend your learnings from Pandas to Spark with caution.

Pandas and Spark operate on the same kind of data — tables. However, the way they interact with it differs significantly.

Yet, many programmers often extend their learnings from Pandas to Spark assuming similar design, which leads to performance bottlenecks.
Let me show you an example today.
Note: If you want a beginner-friendly resource to learn PySpark, I covered it here: Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
Background
One can perform two types of operations in Spark:
Transformations: Creating a new DataFrame from an existing DataFrame.

Actions: These trigger the execution of transformations on DataFrames.

To give you more context, Spark utilizes actions because, unlike common DataFrame libraries like Pandas, Spark transformations follow lazy evaluation.
Lazy evaluation means that transformations do not produce immediate results.
Instead, the computations are deferred until an action is triggered, such as:
Viewing/printing the data.
Writing the data to a storage source.
Converting the data to Python lists, etc.
By lazily evaluating Spark transformations and executing them ONLY WHEN THEY ARE NEEDED, Spark can build a logical execution plan and apply any possible optimizations.
However, there is also an overlooked caveat here that can lead to redundant computations. As a result, it can drastically slow down the execution workflow of our Spark program, if not handled appropriately.
Let’s understand in more detail.
Issue with lazy evaluation
Consider reading a Spark DataFrame (A) from storage and performing a transformation on it, which produces another DataFrame (B).
Next, we perform two actions (count rows and view data) on DataFrame B, as depicted below:

This can be translated into the following code in PySpark:
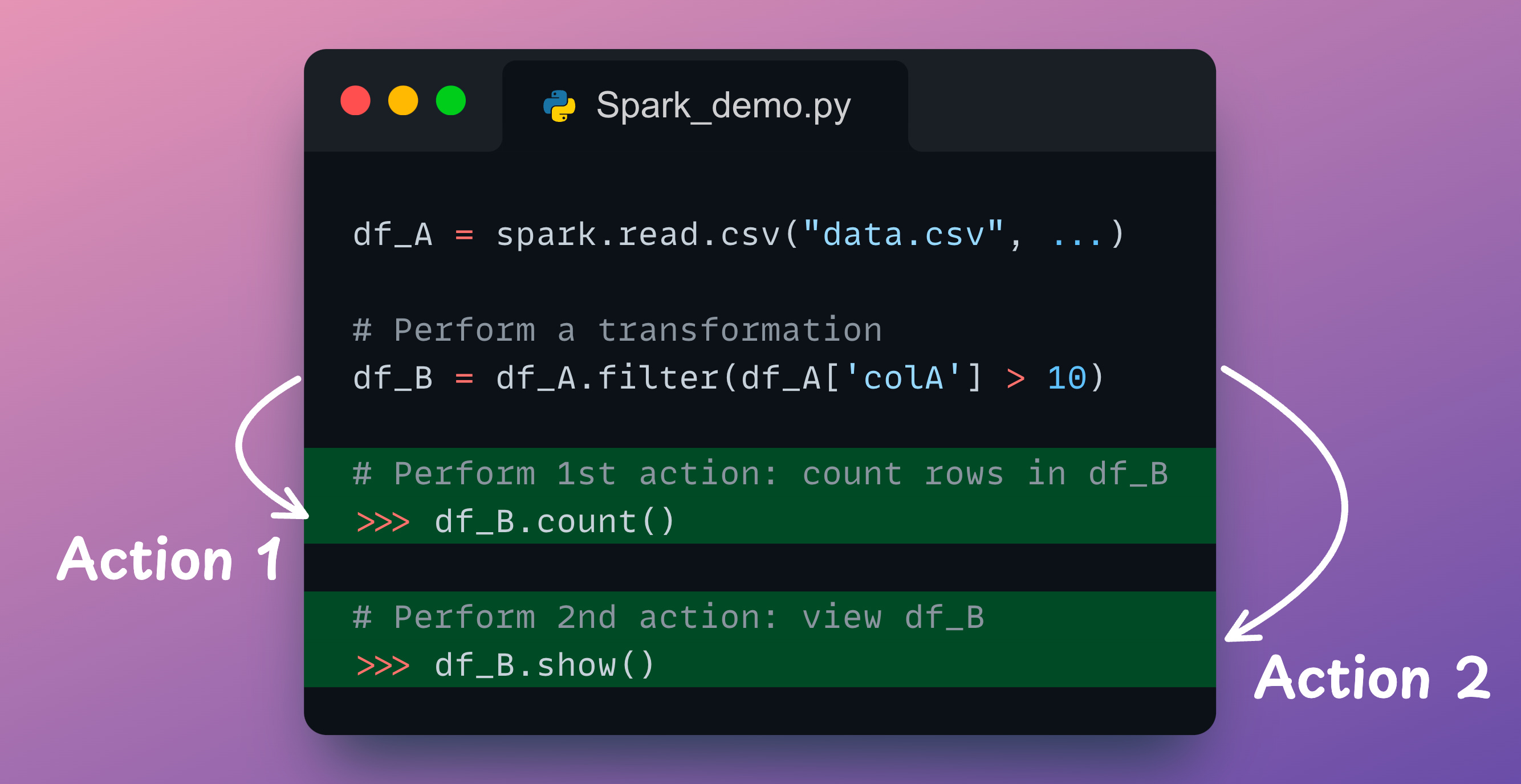
Now, recall what we discussed above: Actions trigger the execution of Spark transformations.
In the above code, the first action is df_B.count(), which triggers the CSV read operation and the filter transformation.
On a side note, as you may have already noticed, the execution methodology is quite different from how Pandas works. It does not provide lazy evaluation. Thus, every operation is executed right away.

Moving on, we have another action: df_B.show(). This action again triggers the CSV read operation and the filter transformation.
Do you see the problem?
We are reading the CSV file and performing the same transformation twice.
It is evident that when dealing with large datasets, this can lead to substantial performance bottlenecks.
Solution
One common way to address this is by using caching.
As the name suggests, it allows us to cache the results of Spark transformations in memory for later use.
The df.cache() method lets you do this.
Note: In addition to
df.cache(), there’sdf.persist()method as well, which provides more flexibility for caching. But today we shall only discussdf.cache().
We can use the df.cache() method as follows:
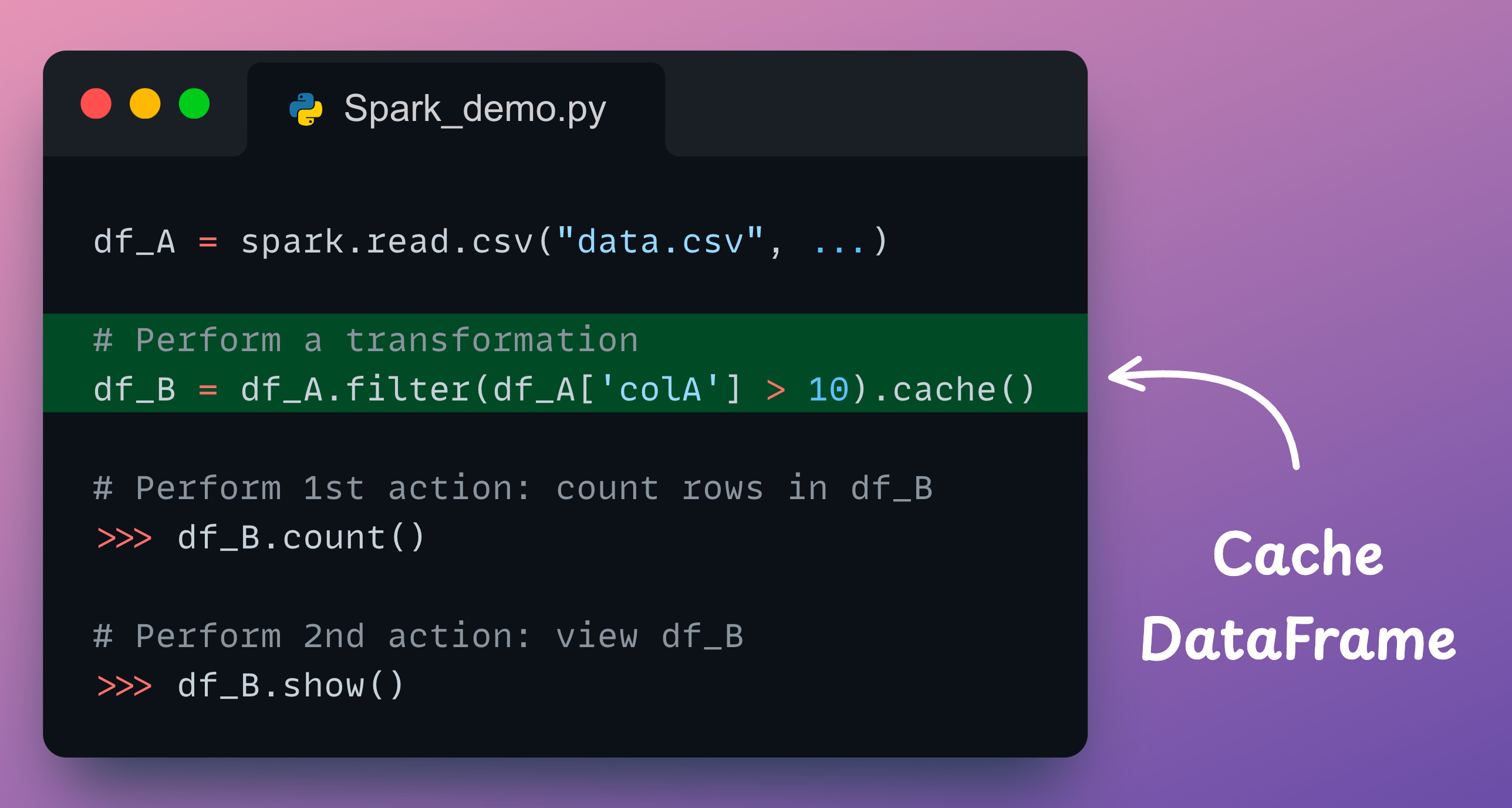
In this code, the first action (df_B.count()) triggers the CSV read operation and the filter transformation.
However, in contrast to the non-cached demonstration we discussed earlier, the results of the filter transformation get cached this time.
Moving on, the second action (df_B.show()) uses these cached results to show the contents of df_B.
It is easy to understand that caching eliminates redundant operations, which drastically improves the run-time.
Do note that the df.cache() method caches the DataFrame in memory.
Thus, it is advised to release the cached memory once it is no longer needed. We can use the df.unpersist() method for this:

That said, Spark is among the most sought-after skills by data science employers. Adding Spark to your skillset will be extremely valuable in your data science career ahead.

I wrote a complete beginner-friendly deep dive (102 mins read) on PySpark: Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
If you are a complete beginner and have never used Spark before, it’s okay. The article covers everything.
👉 Over to you: What are some other overlooked Spark optimization techniques?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 84,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.