
Speculation Is All You Need!
New technique delivers 4x faster LLM inference in production.

Free Claude Code Course with Lydia Hallie, Anthropic & Master.dev
.png")
Master.dev partnered with Anthropic and made their Claude Code course free for everyone. You can just dive in without any subscription or trial.
It’s taught by Lydia Hallie, who’s been an instructor with Master.dev for years and now works on the Claude Code team at Anthropic.
When she taught Claude Code live, it broke every platform record they have, with over 10,000 people tuning in.
Lydia has a knack for visualizing how tools work under the hood, which is exactly the mental model you need to stop guessing with AI and start directing it.
Thanks to Master.dev for partnering today!
Speculation is all you need!
Speculative decoding speeds up LLM inference, but the gain usually stalls around 2-3x. The cap comes from the drafter, the small model that proposes tokens for the large target model to verify, because it still generates one token at a time.
Modal recently released a new set of DFlash draft models for several Qwen models that move past this cap.
Running Qwen 3.5 122B-A10B with one of them reached over 1000 tokens/sec, up from 250 without speculation, and the output stays identical to normal decoding.
Let’s break down how speculative decoding works, why acceptance length decides the speedup, and what these new drafters changed to push it higher.
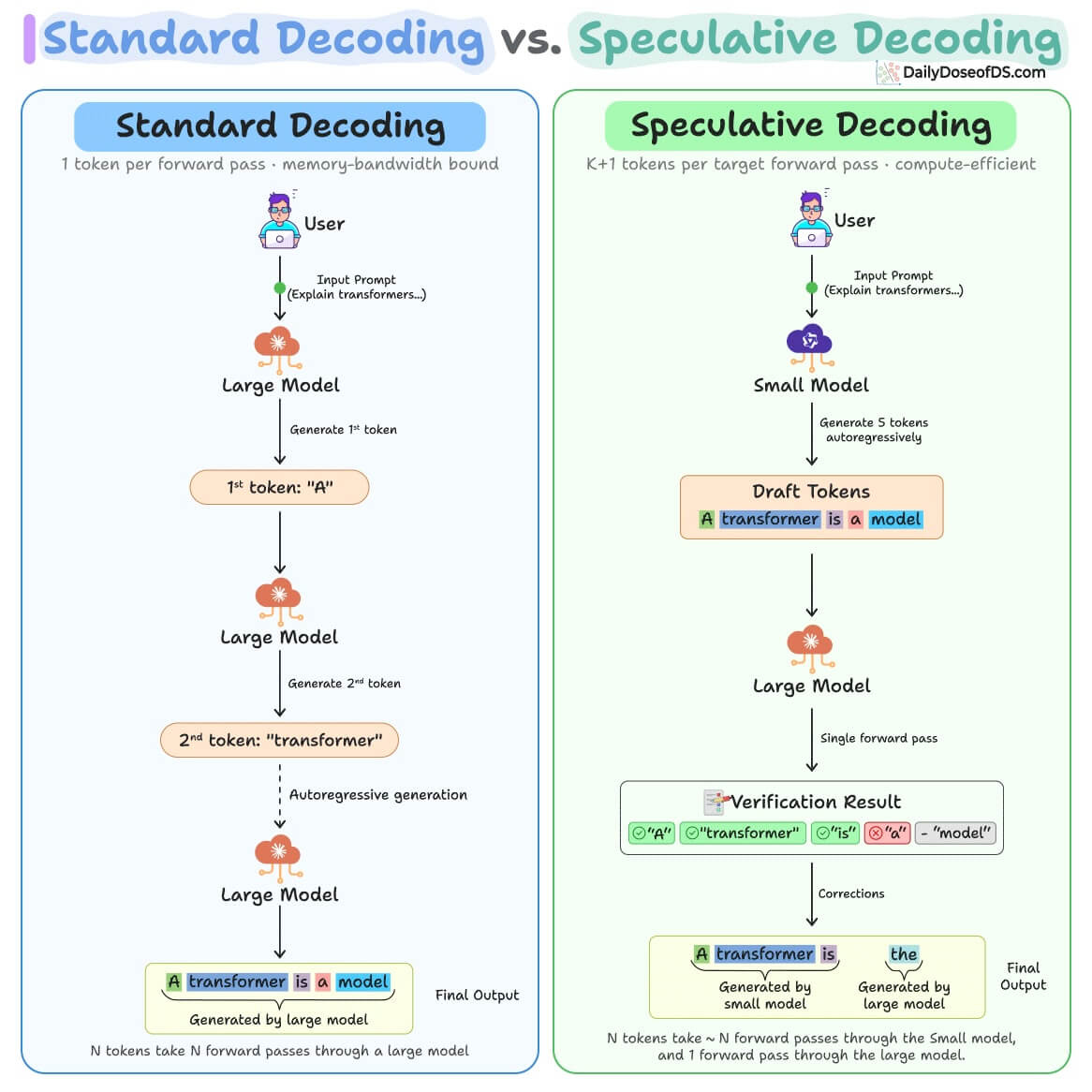
How speculative decoding works
A small draft model generates the next several tokens, and the large target model verifies all of them at once in a single forward pass.
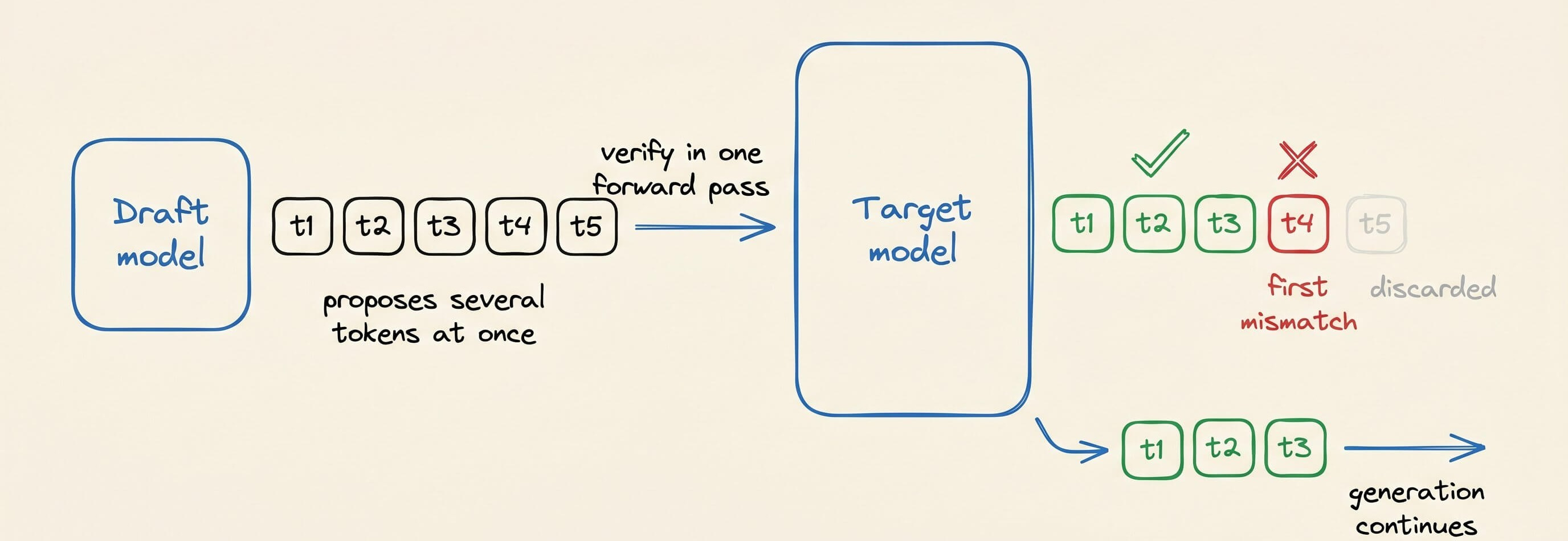
Every token the target agrees with is kept. At the first mismatch, the target replaces that token with its own prediction, discards everything after it, and generation continues from the last accepted token.
The kept tokens are exactly what the target would have produced on its own, so the output matches standard decoding with no quality loss.
Why the drafter caps the speedup
A standard drafter is autoregressive, generating one token at a time, so the drafting step becomes the bottleneck and holds real speedups near 2-3x.
DFlash replaces that autoregressive drafter with a block diffusion model that denoises a full block of tokens in one parallel pass rather than left to right.
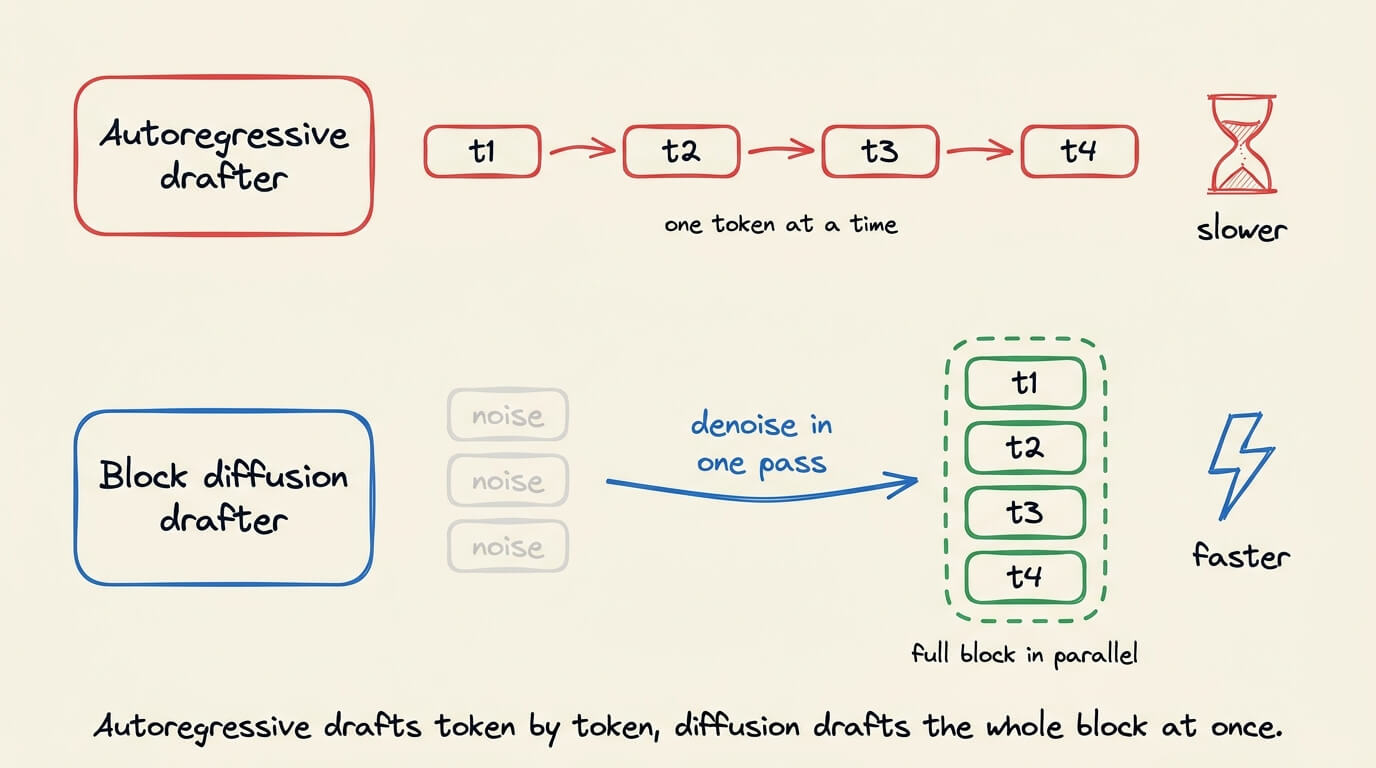
The drafting cost then stays flat, no matter how many tokens it proposes ahead.
The drafter also does not work from the token sequence alone. As the target model reads the context, each of its layers produces hidden states, and DFlash pulls those representations from several layers and feeds them into the draft model.
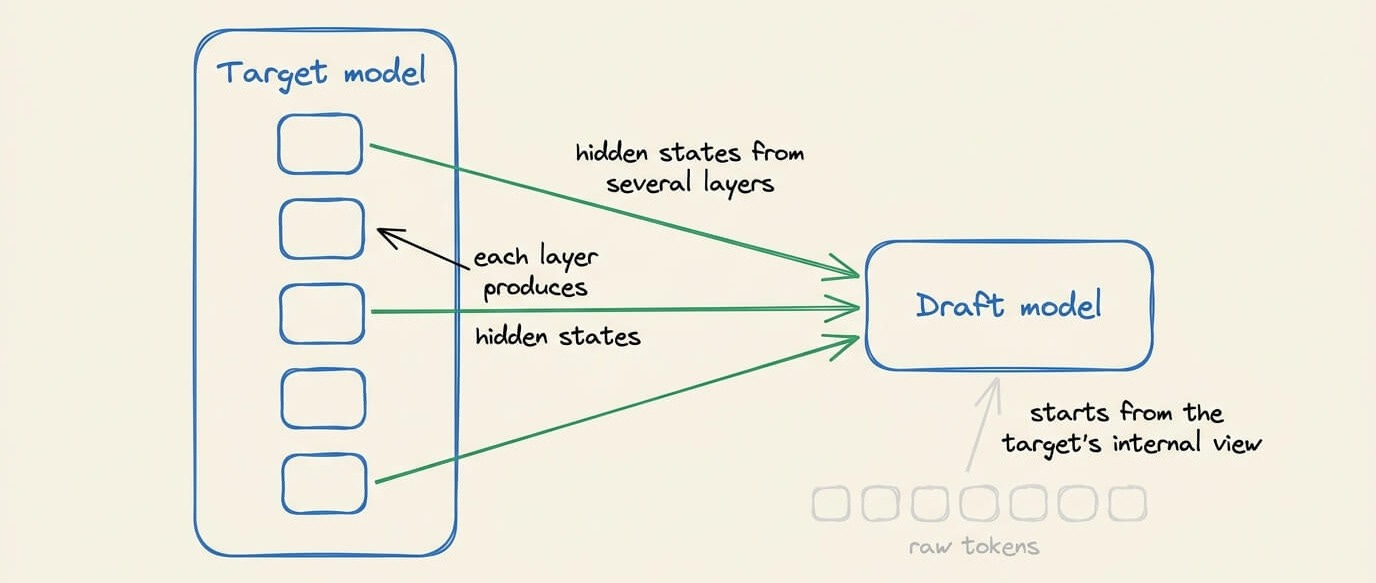
So the drafter starts from the target’s own internal view of the context instead of guessing from raw tokens, which makes its proposed tokens line up with the target more often.
What decides the speedup?
How often those proposals get accepted is captured by the acceptance length, the count of drafted tokens the target accepts per forward pass.
Acceptance length maps almost linearly to the speedup, because decode is memory-bound rather than compute-bound.
Each step spends most of its time moving model weights from GPU memory into the compute units, not on the matmuls, and a model above 100B parameters means reading tens of gigabytes every step.
Reading those weights takes the same time whether the pass checks one token or a full block. So every token accepted in a pass is nearly free throughput, while every rejected token still costs time to draft.
This is also why drafting a thousand tokens at once does not help. The target keeps the run only up to its first mismatch, so a 1000-token block that misses on the 5th token throws away the other 995, along with the compute spent drafting them.
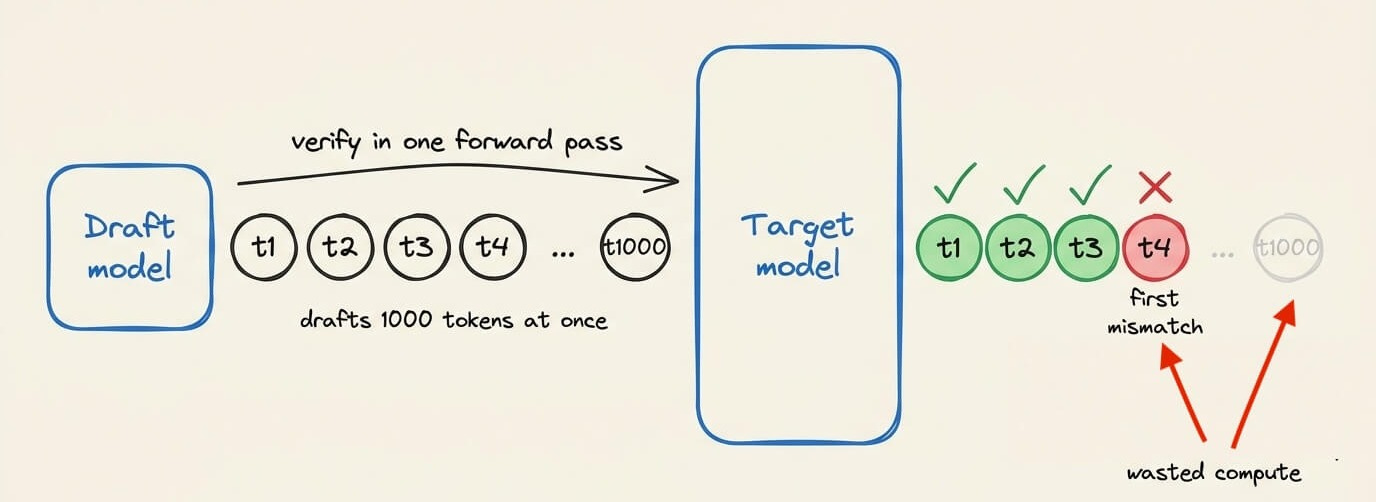
Draft length must be balanced:
Too few draft tokens per pass barely move throughput
And too many draft tokens likely waste compute on tokens discarded past the first miss.
This is why real production gains not only depend on how tokens get drafted, but also on how many survive verification.
Modal’s new strategy for DFlash
Modal recently released a new set of DFlash draft models for several Qwen models on HuggingFace.
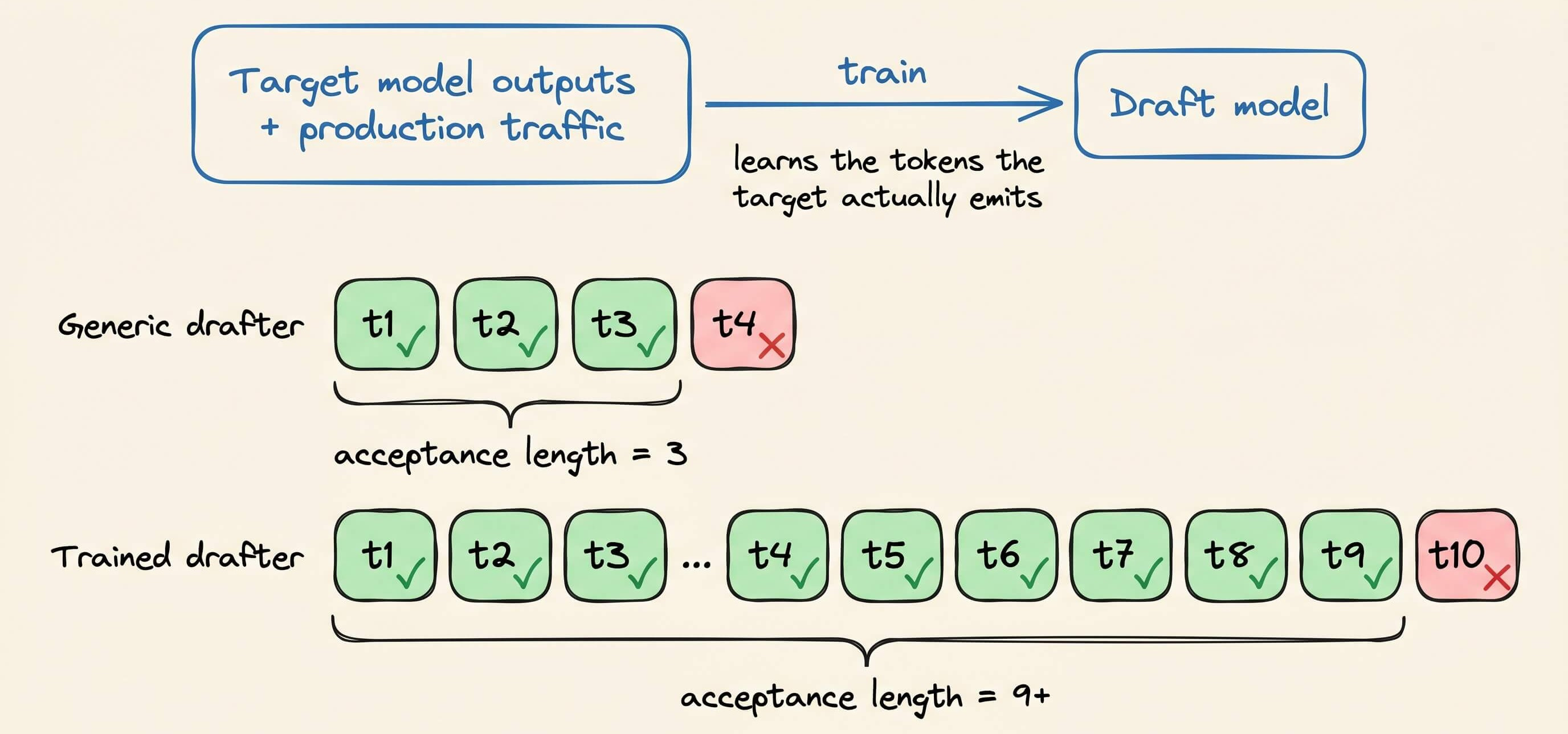
They trained the drafters on the target’s own outputs and on real production traffic, so they propose tokens the target actually emits.
The run then survives longer before the first miss, which pushed acceptance length from a baseline of 3 to over 9.
They benchmarked Qwen 3.5 27B on one B200.
An acceptance length of:
2 gave 1.86x speedup.
4 gave 3.57x speedup.
8 gave 5.62x speedup.
Running Qwen 3.5 122B-A10B with one of these tuned drafters reached over 1000 tokens/sec at concurrency 1 on a B200, against 250 without speculation.
If you are running speculative decoding in production, the quality of the drafter will always decide how high the acceptance length can reach.
Training the drafter on the workload is a practical way to get there. The DFlash drafters are already integrated with vLLM, SGLang, and Transformers, with draft models on HuggingFace for Qwen and several other model families.
DFlash draft models on HuggingFace →
Our full breakdown on speculative decoding covering drafting, verification, rejection sampling, and several other techniques to optimize it →
👉 Over to you: If you’re self-hosting inference, would you train a custom drafter on your own production traffic, or run a generic one off the shelf?
Build Agents that can learn like humans
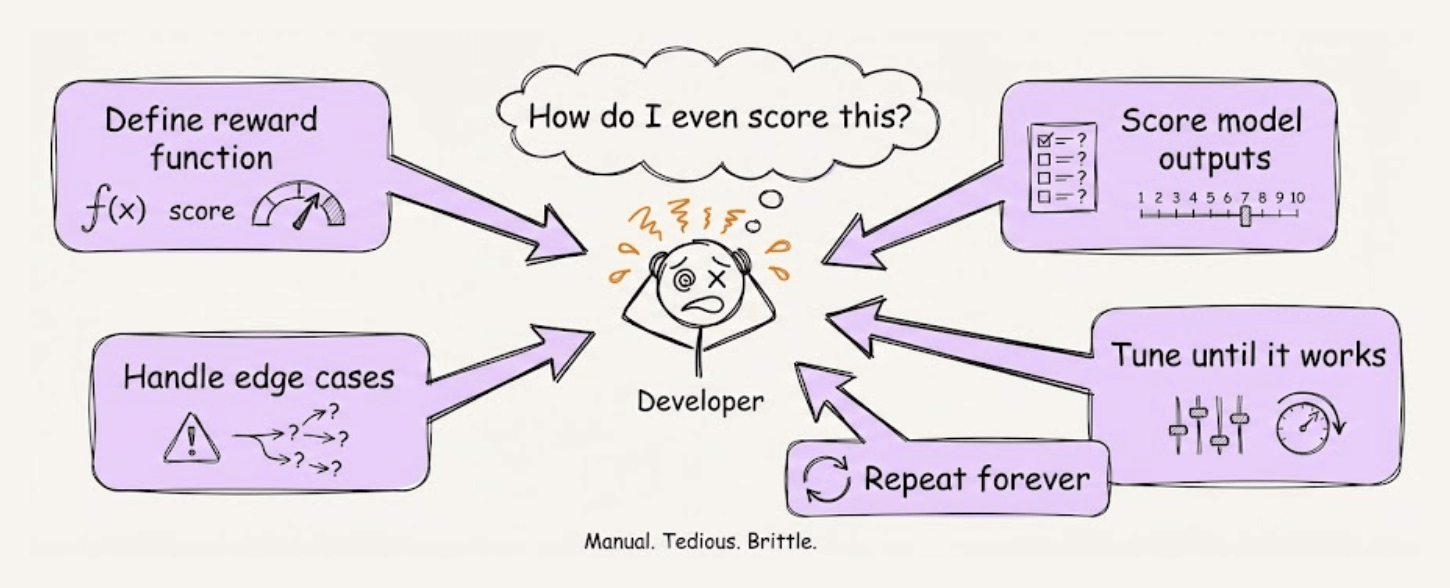
Reinforcement learning for LLMs always had one major problem: manually defining reward functions.
You have to figure out how to score model outputs, handle edge cases, and tune everything until training works.
ART (Agent Reinforcement Trainer) is an open-source framework that solves this with a simple approach:

Let the agent attempt tasks multiple times
An LLM judge relatively grades each attempt
The model learns from what worked vs what didn’t
Notice that it needs no manual reward engineering. You don’t have to manually score output or tune penalties. You just need to know which attempt was better, and LLM judges are naturally great at that comparison.
If this sounds familiar, it’s because it’s the core idea behind GRPO (Group Relative Policy Optimization), the algorithm that made DeepSeek R1 so effective.
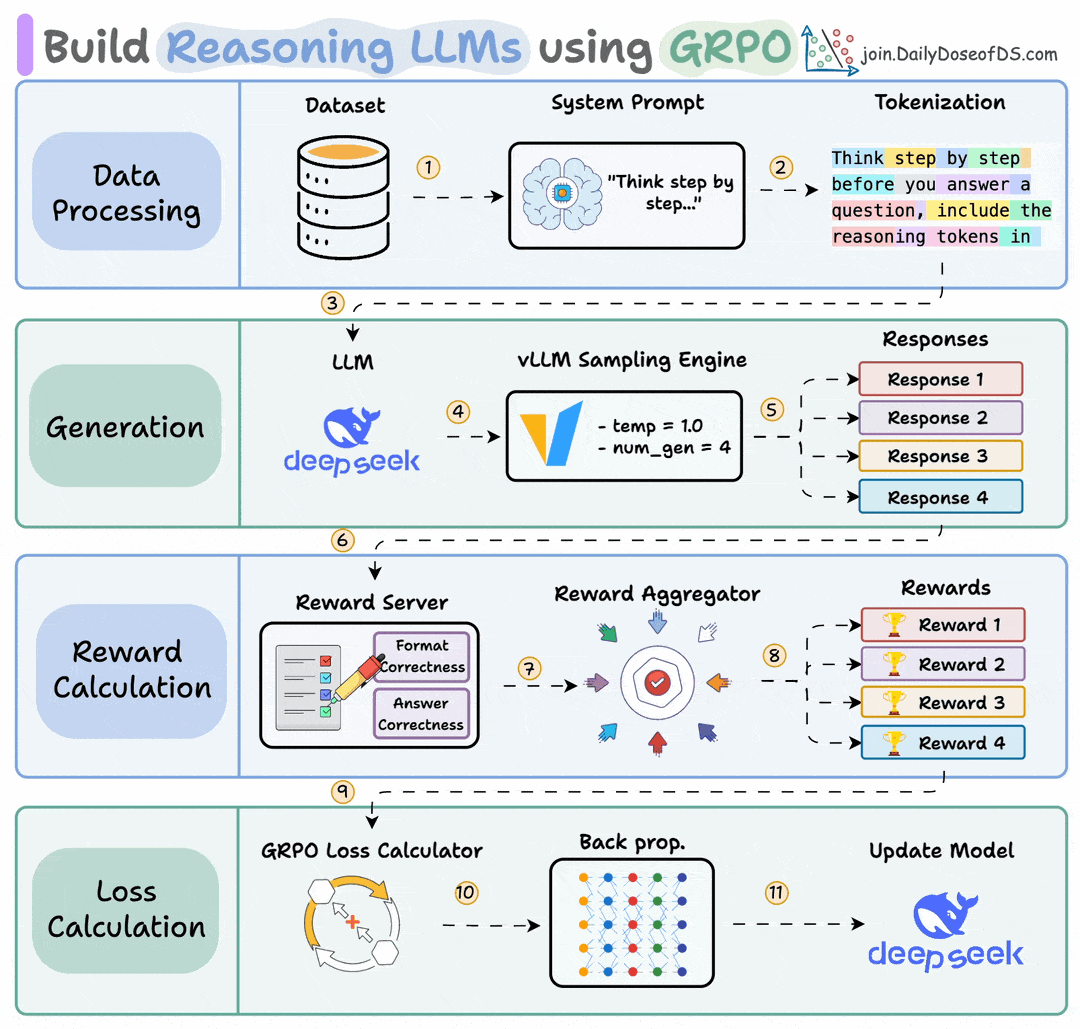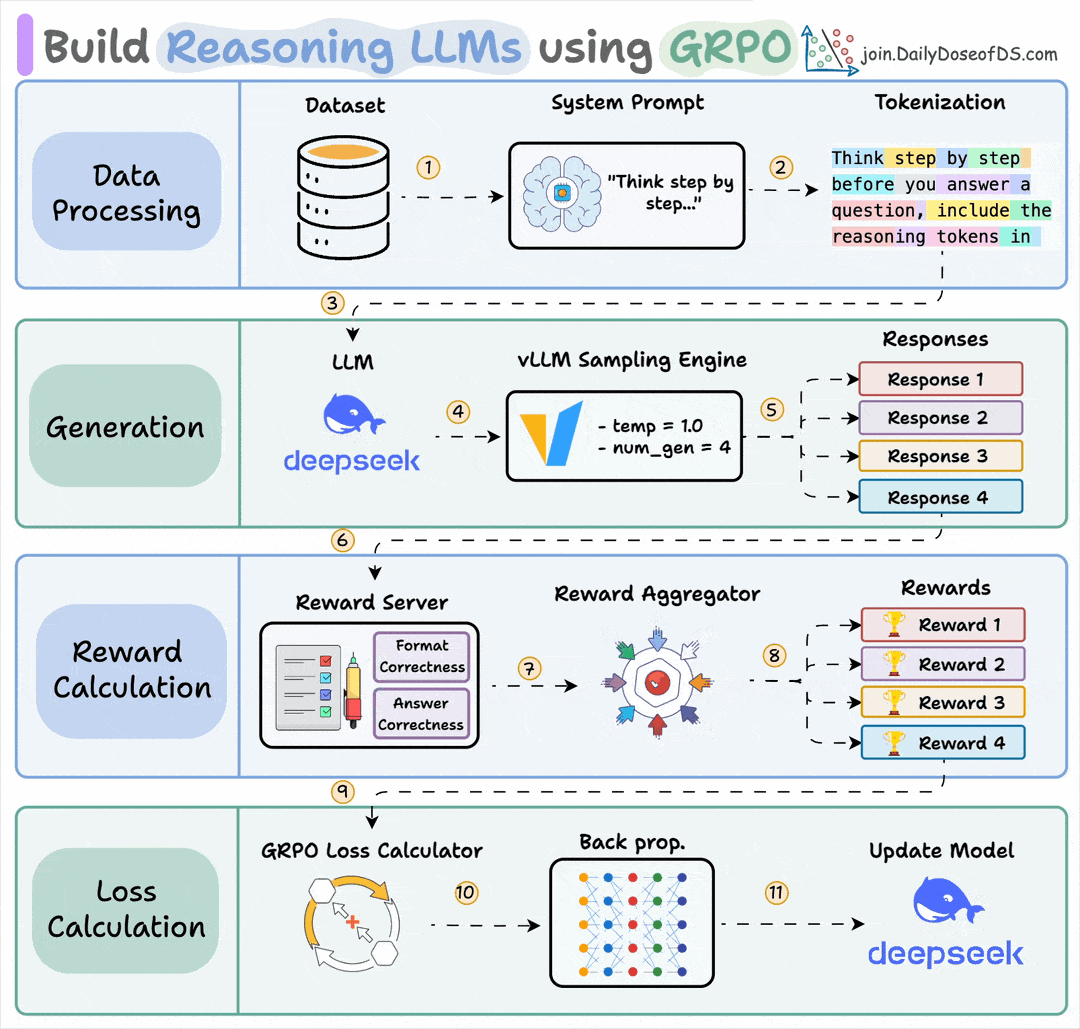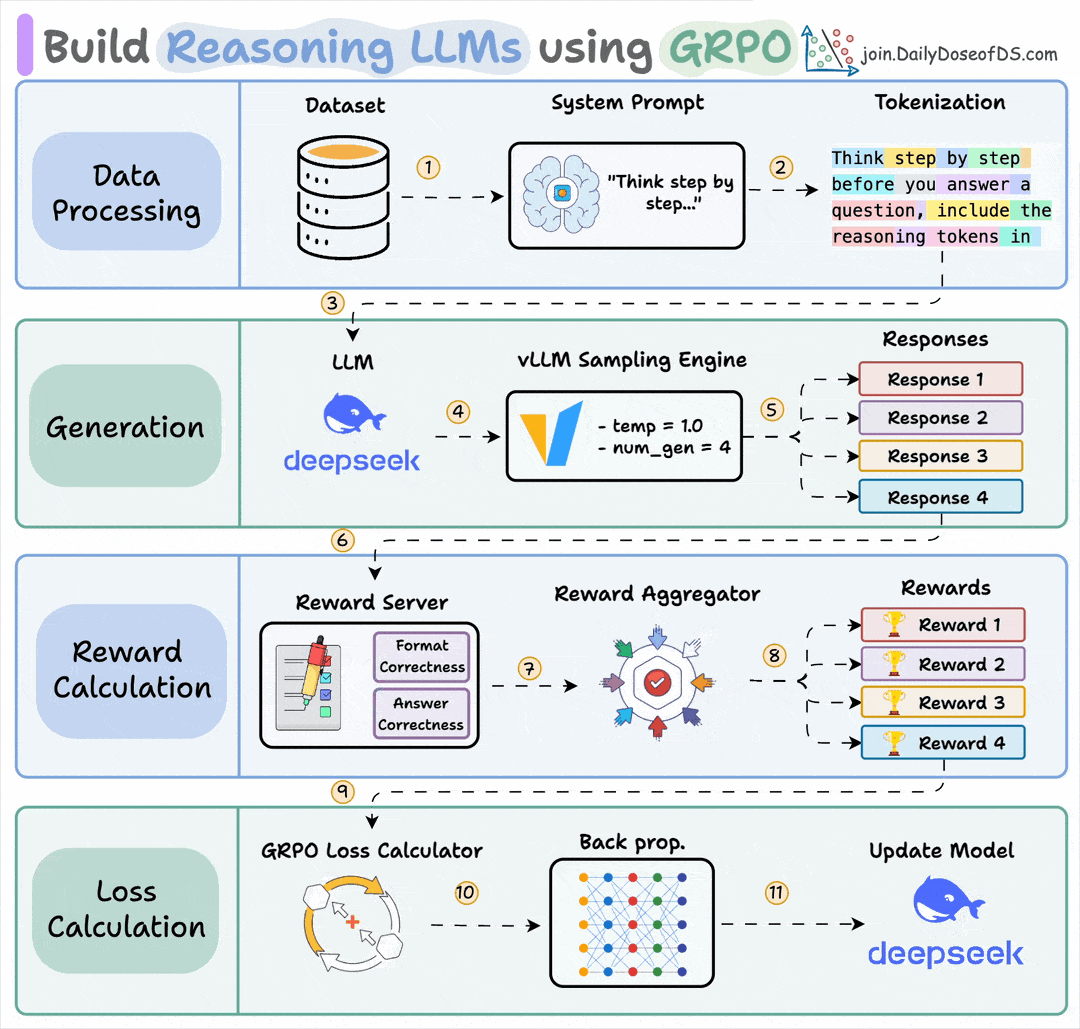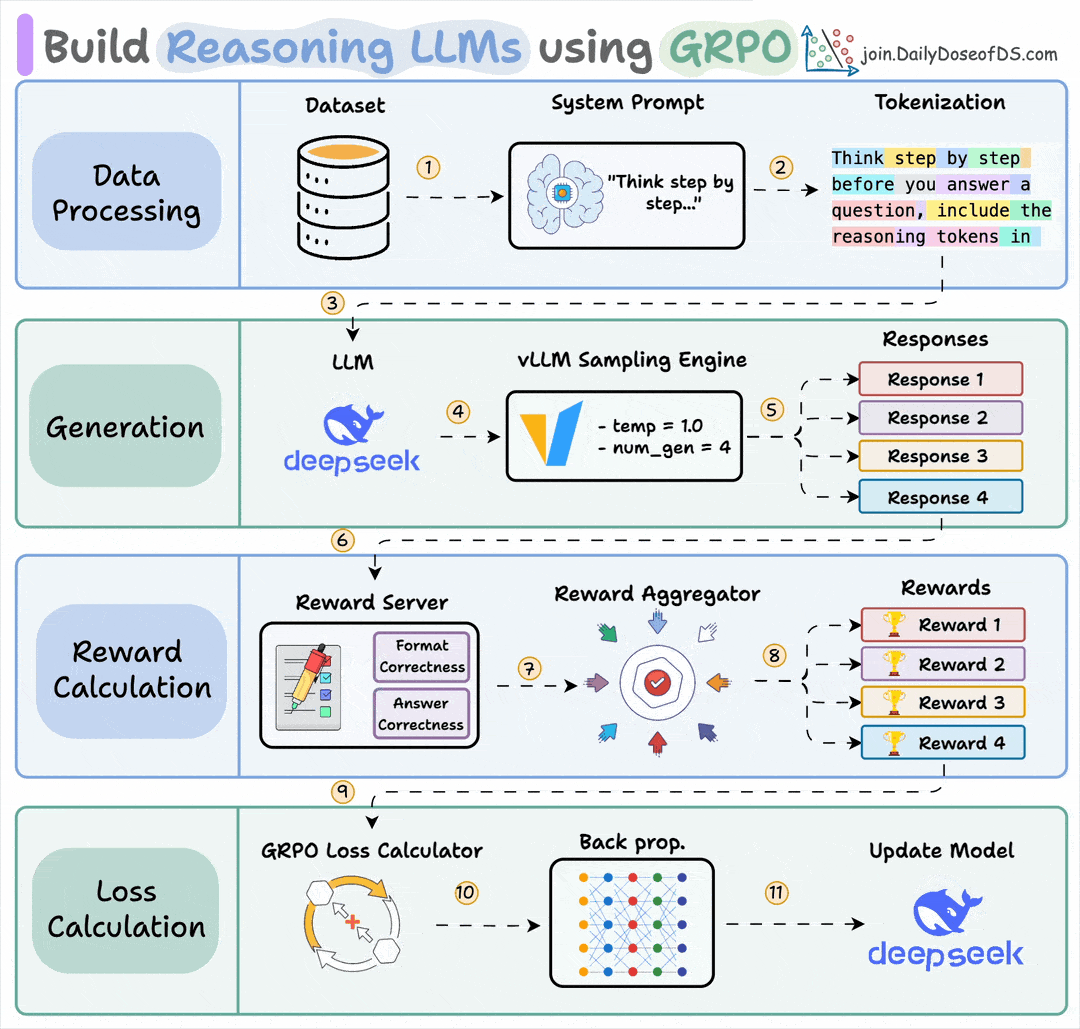
But here’s what makes ART different.
Most RL frameworks are built for simple chatbot interactions.
One input, one output, and done. But real-world agents search through documents, invoke APIs, and reason across multiple steps before completing a task.
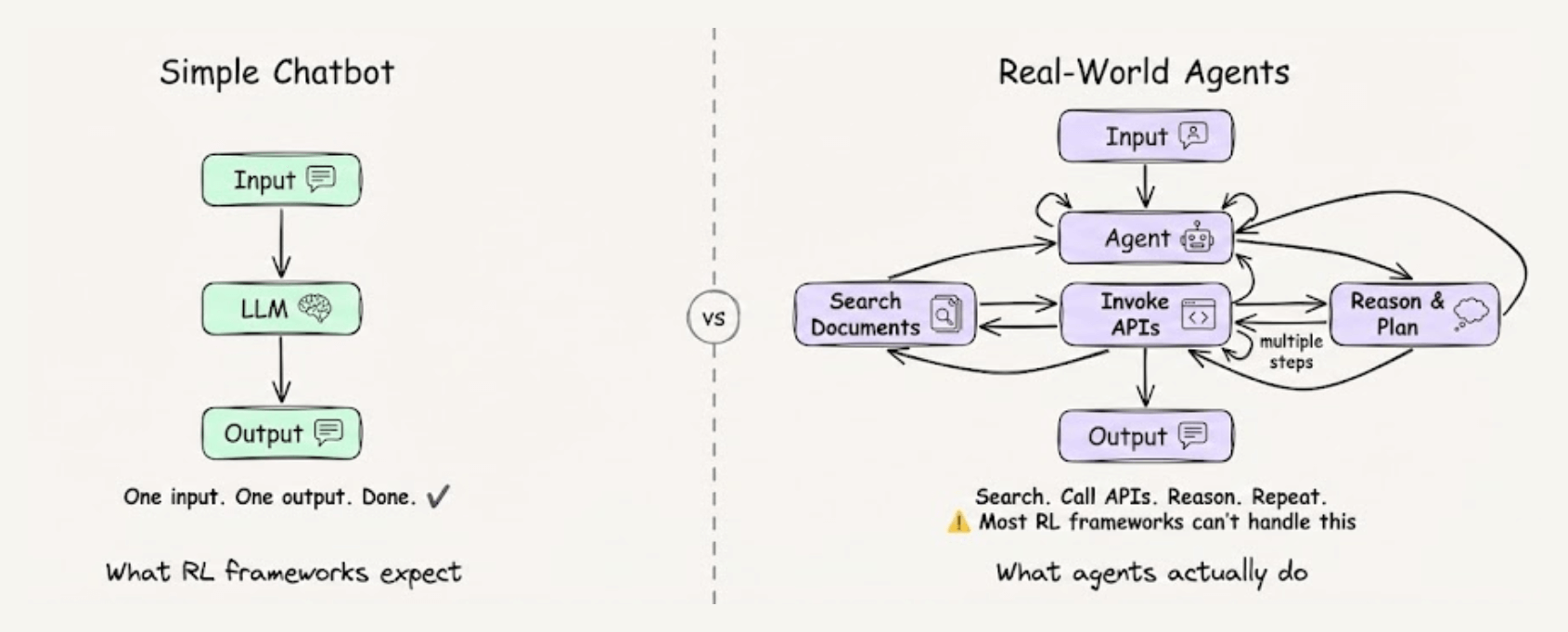
Most RL frameworks can’t handle this complexity, but ART can.
It provides:
Native support for tool calls and multi-turn conversations.
Integrations with LangGraph, CrewAI, and ADK.
Efficient GPU utilization during training.
It handles the entire infrastructure using vLLM to serve models and generate trajectories, and Unsloth to apply GRPO and run training.
These are two of the most popular open-source LLM frameworks, stitched together into one seamless workflow.
This means you can easily fine-tune a small open-source model to outperform sophisticated closed-source models on your specific task.
In the video below, we walk through the entire process:
setting up ART,
understanding how the GRPO training loop works,
and fine-tuning Qwen to intelligently search through emails.
Everything runs locally. 100% open-source.
What you learn here can be applied to any problem.
You can find the ART GitHub repo here → (don’t forget to star it)
It has the notebook from the video, plus additional examples!
Thanks for watching!