
Speculative Decoding in LLMs
...explained with code and tradeoffs.

Fine-tune any LLM directly from Claude!
We built a Hugging Face fine-tuning studio that lets you fine-tune any LLM directly from Claude:
The app connects to the HF Hub for model and dataset search. It handles chat template formatting for the training data, and lets you configure LoRA rank, quantization, batch size, and learning rate directly from Claude.
Training runs on HF’s GPU infra via AutoTrain.
Once training finishes, you can also chat with your fine-tuned model (or any other LLM on HF) directly from Claude
The studio’s built with the mcp-use SDK, an open-source full-stack framework to build MCP Apps for Agents.

In mcp-use, any MCP tool can be associated with a UI.
You define a tool handler, create a React component, and the mcp-use framework handles the tool registration, prop mapping between server and widget, bundling, and hot reload during development.
The widgets follow the MCP Apps standard, inspired by OpenAI’s Apps SDK.
You can find the mcp-use GitHub repo here →
And you can find the code for this fine-tuning studio here →
Speculative decoding in LLMs
Google uses speculative decoding in AI Overviews to serve over a billion Search users.
It’s also how Anthropic, Meta, and most major inference providers reduce latency at scale and get 2-3x more tokens per second, with mathematically identical outputs.
The loop has three steps and the diagram below depicts how speculative decoding differs from standard decoding:
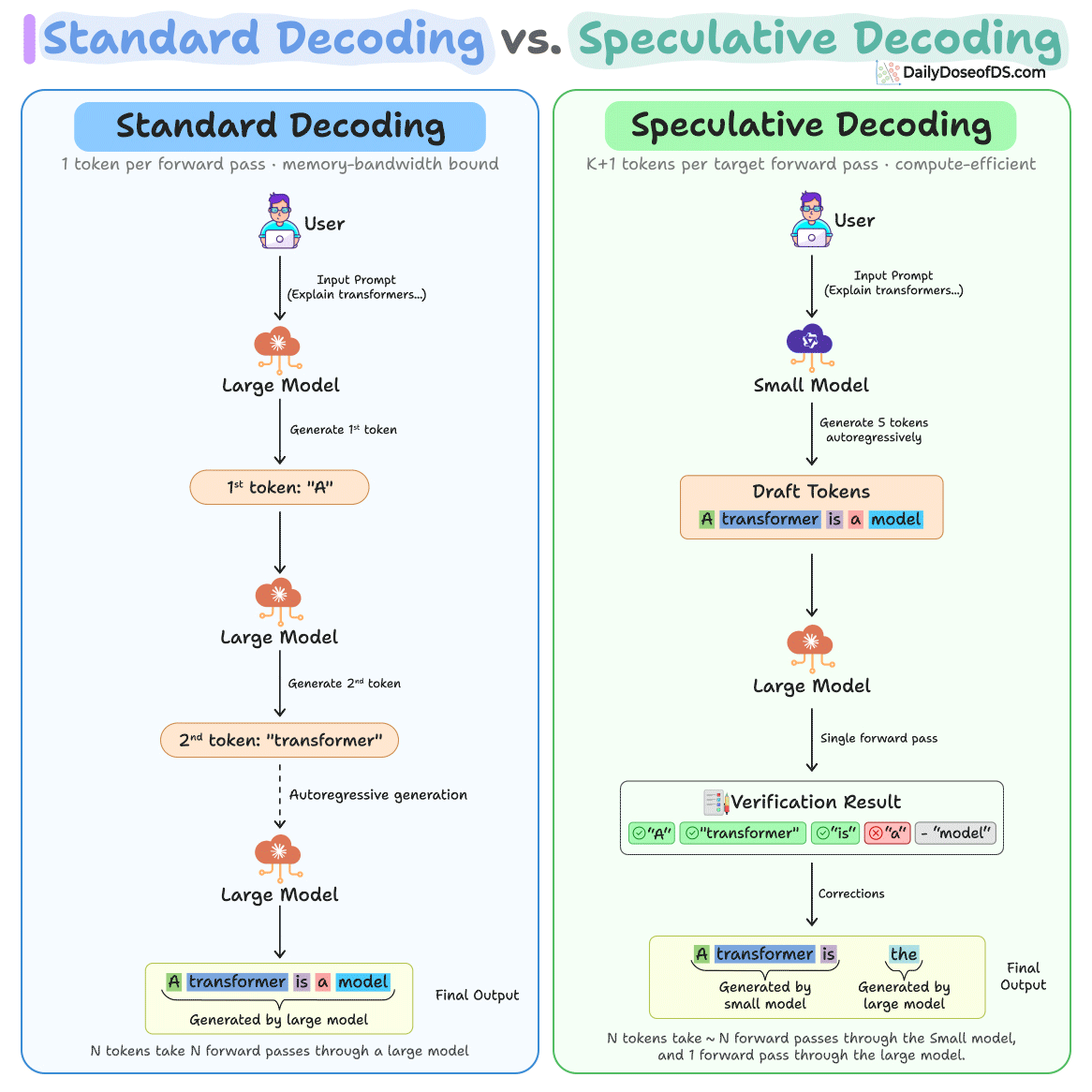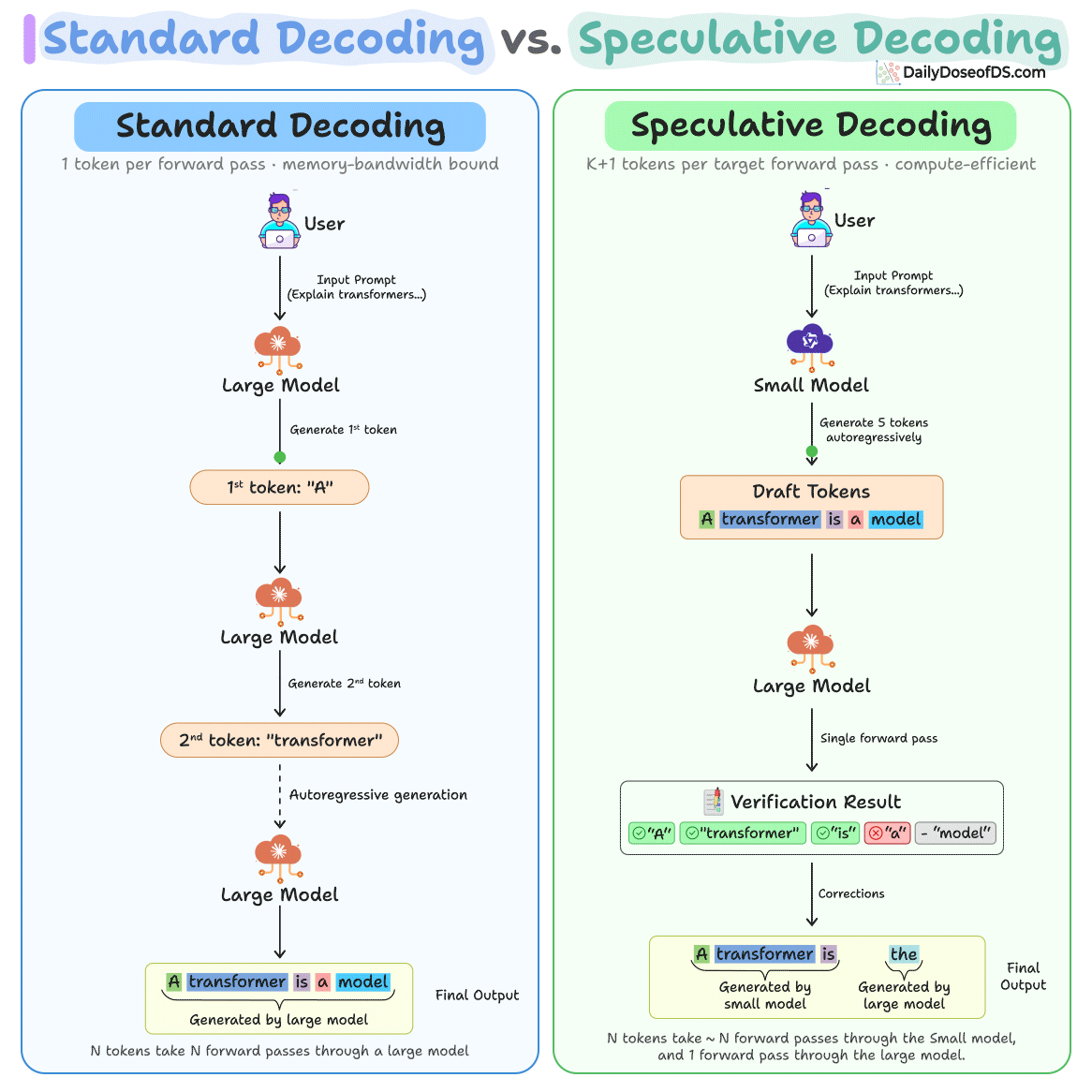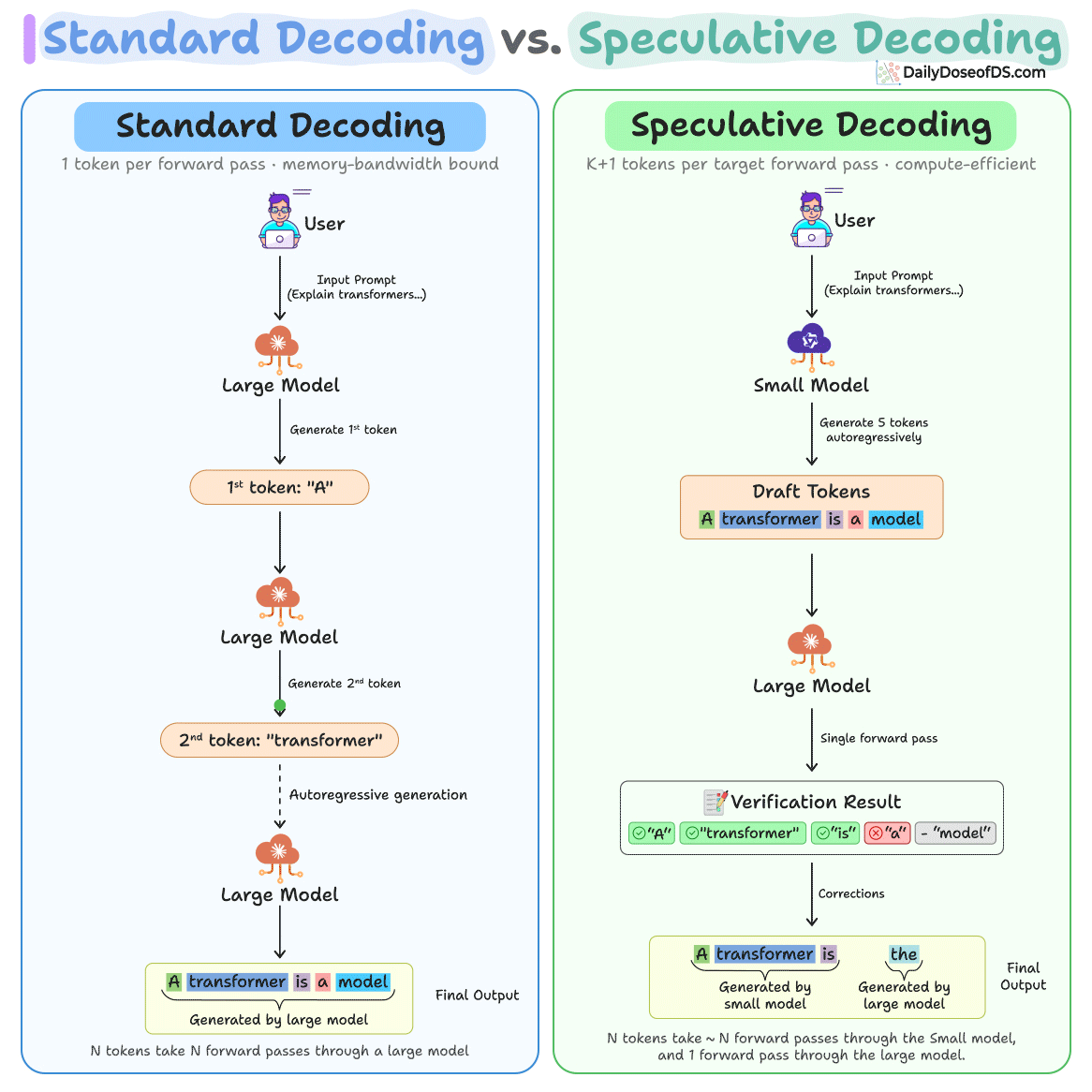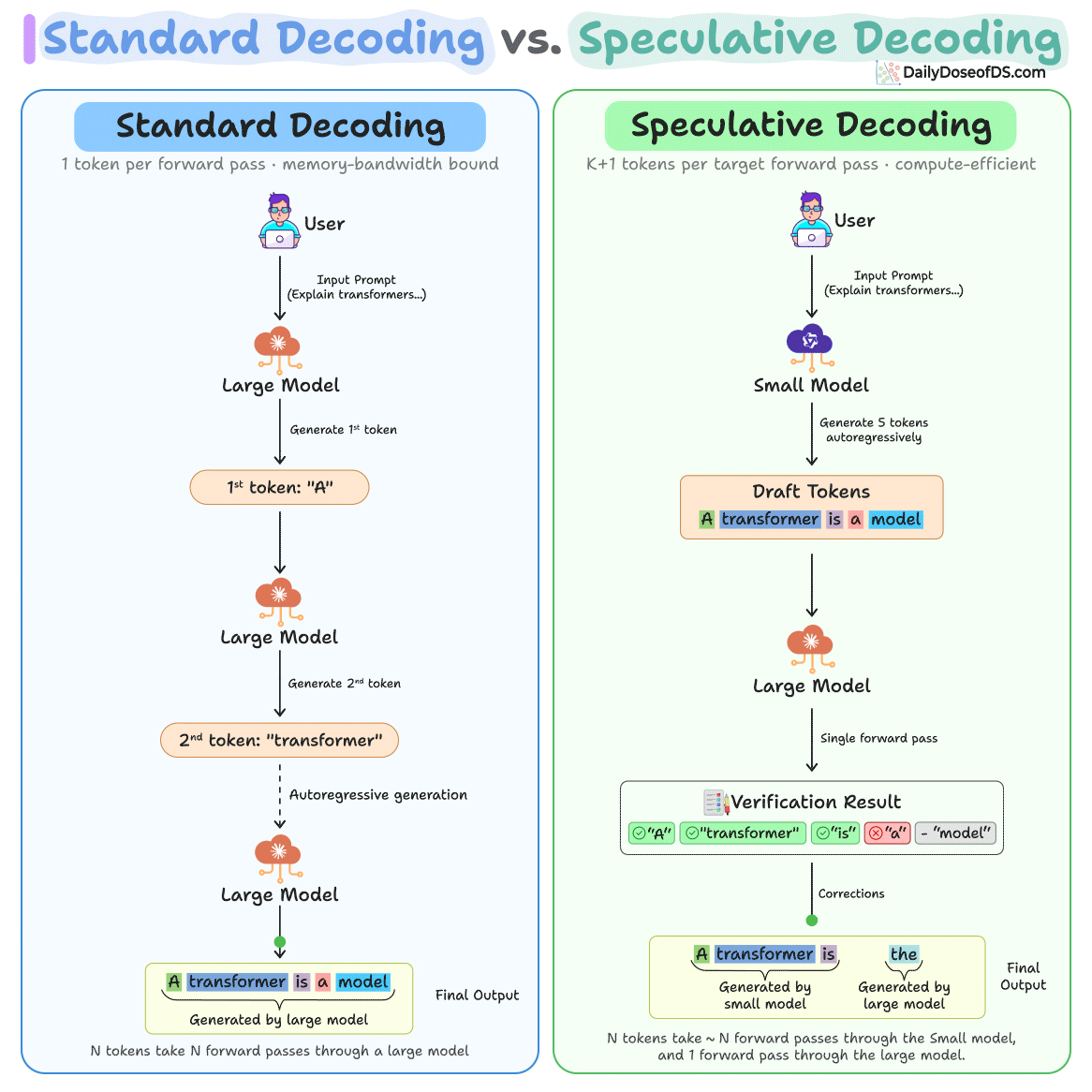
A small model generates K candidate tokens autoregressively. Because it’s 10-100x smaller than the target, this costs roughly 1-2% of a target forward pass.
Then a large model processes all
Kdraft tokens in a single forward pass, computing its distributionp(x)at each position. This parallel verification is structurally identical to prefill, so it saturates GPU compute instead of being memory-bandwidth bottlenecked like single-token decoding.Finally, each draft token is accepted or rejected by comparing the probability distributions of the small and large models. The algorithm walks through tokens sequentially. If token 3 is the first rejection, tokens 1-2 are accepted as-is (the small model got them right), the large model replaces token 3 with its own prediction (which it already computed during the verification pass), and tokens 4-5 are discarded without evaluation.
Note: Traditionally, both models must share the same tokenizer since verification compares probability distributions token-by-token. Universal Assisted Generation (UAG, Transformers 4.46+) relaxes this via text-level re-encoding, but same-tokenizer pairs remain faster because they skip that overhead.
In the best case, you get K+1 tokens from just one large model call.
And in the worst case, where every draft token is rejected, you still get 1 token from the large model, which is the same as standard decoding.
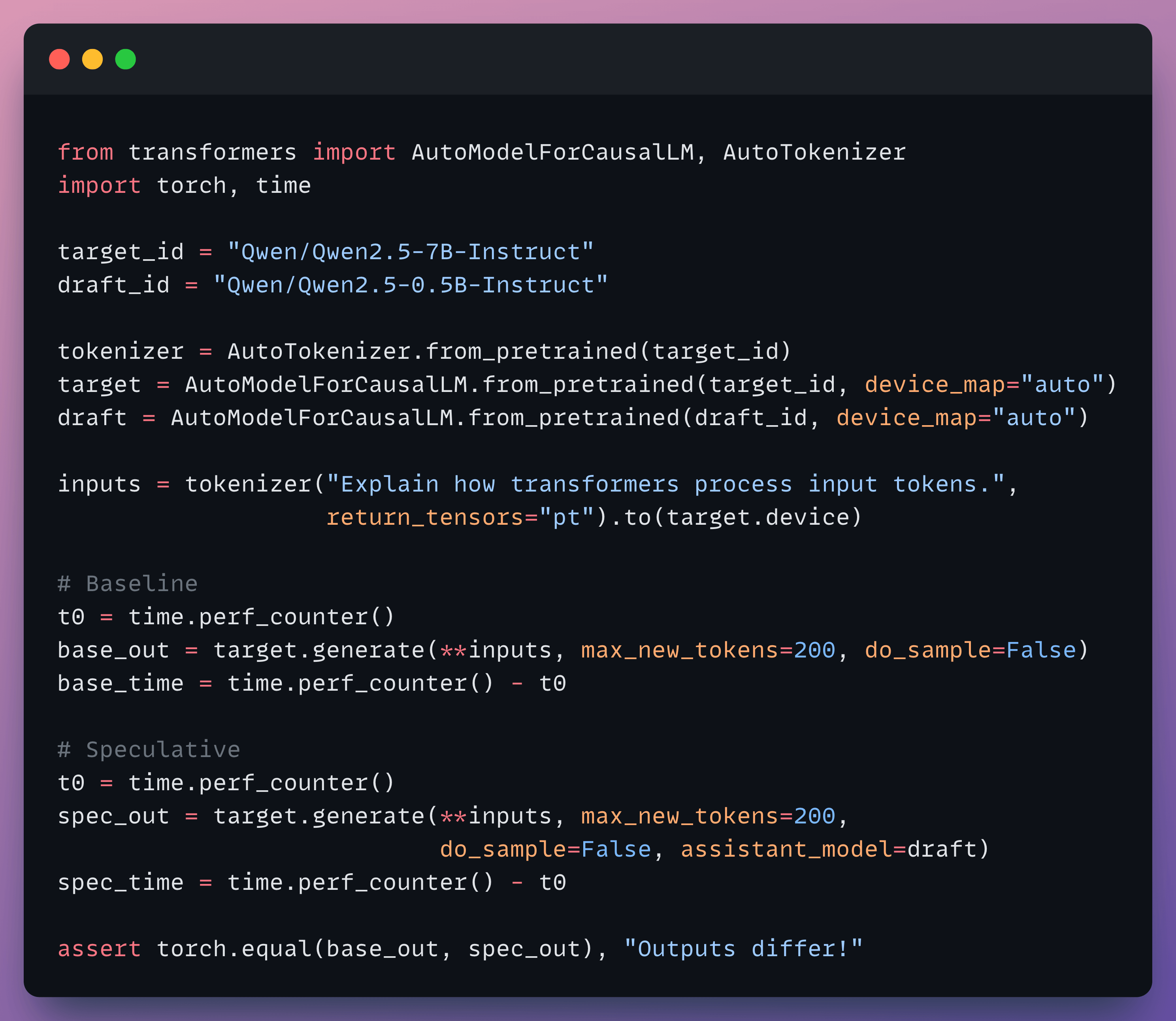
Implementation-wise, Hugging Face Transformers already exposes this as assistant_model in the generate() call:
For production serving, vLLM also supports this.
Here are some production tradeoffs:
The same tokenizer gives the best speedups. This is because when draft and target share a tokenizer, verification happens directly at the token ID level with zero overhead. Cross-tokenizer speculation also works, but it’s slow.
Cross-tokenizer pairs → 1.5-1.9x speedup
Same-tokenizer pairs → 1.5-3x speedup
A larger draft model will have a higher acceptance rate, but the drafting overheads themselves get expensive and eat the gains. For instance:
Llama 3.2 1B as the drafter achieved 2.31x.
The larger Llama 3.1 8B only hit 2.08x despite higher acceptance.
Eliminating the second model
The classic setup has three practical pain points.
You need a matched draft model from the same family.
The model consumes extra GPU memory.
Several variants have emerged to eliminate one or more of these.
EAGLE removes the separate-model problem entirely. Instead of a standalone drafter, it trains a lightweight head (< 1B params) directly on the larger model’s hidden states.
Medusa solves the same problem differently. It adds multiple prediction heads to the larger model, each predicting tokens at different future positions simultaneously.
Self-speculative decoding (LayerSkip, SWIFT) eliminates both the extra model and the training requirement. It uses the target model’s own early layers as the drafter, then the full model for verification.
The direction is that speculative decoding is converging toward single-model solutions where the draft capability is built into the target model itself, either through trained heads or layer skipping.
For most production setups today, though, the two-model approach with a same-family drafter remains the simplest path to 2-3x speedups.
As further reading:
And we covered 72 techniques to optimize LLMs in production here →
Here’s the visual again for your reference:
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.