
TabM: A Powerful Alternative to MLP Ensemble
32x parameter reduction without accuracy loss.

KitOps: Package and version ML models, data, and code [Open-source]
Git is best suited for versioning a codebase. But ML projects also involve data, model weights, and more.
KitOps is an open-source framework that lets you package, version, and share AI/ML projects. It uses open standards, so it works with the AI/ML, development, and DevOps tools you are already using.

Works across all types of AI/ML projects:
Predictive models
Large language models
Computer vision models
Multi-modal models
Audio models
GitHub repo → (don’t forget to star the repo)
TabM: A Powerful Alternative to MLP Ensemble
In the realm of tabular ML:
MLPs are simple and fast but underperform on tabular data.
Deep ensembles are accurate but bloated and slow.
Transformers are powerful but rarely practical on tables.
So for years, the go-to method for tabular learning has stayed the same: gradient-boosted decision trees.
But what if a single model could behave like an ensemble, all with the speed of an MLP and the accuracy of GBDT?
A paper about TabM (short for Tabular multiple prediction) does exactly that.
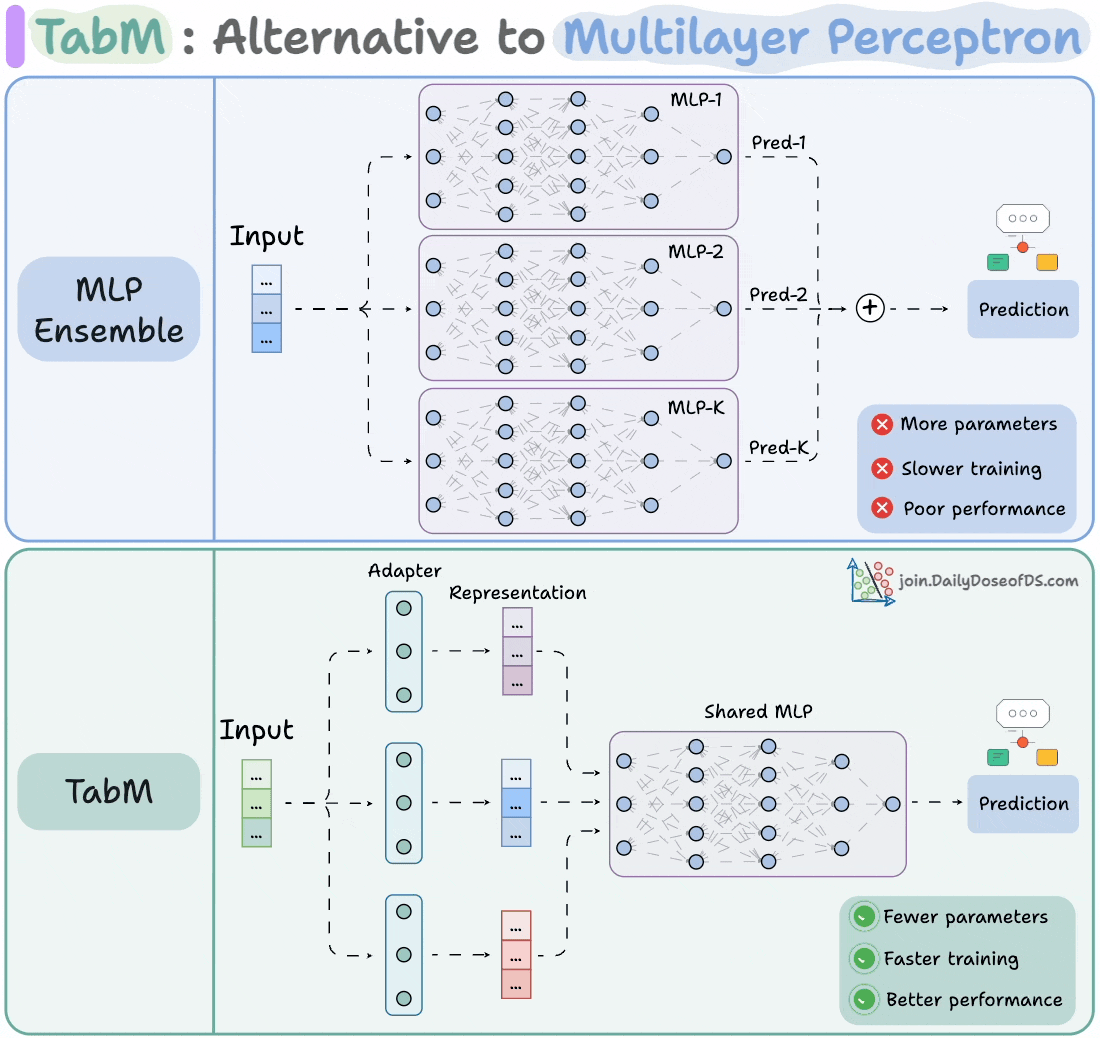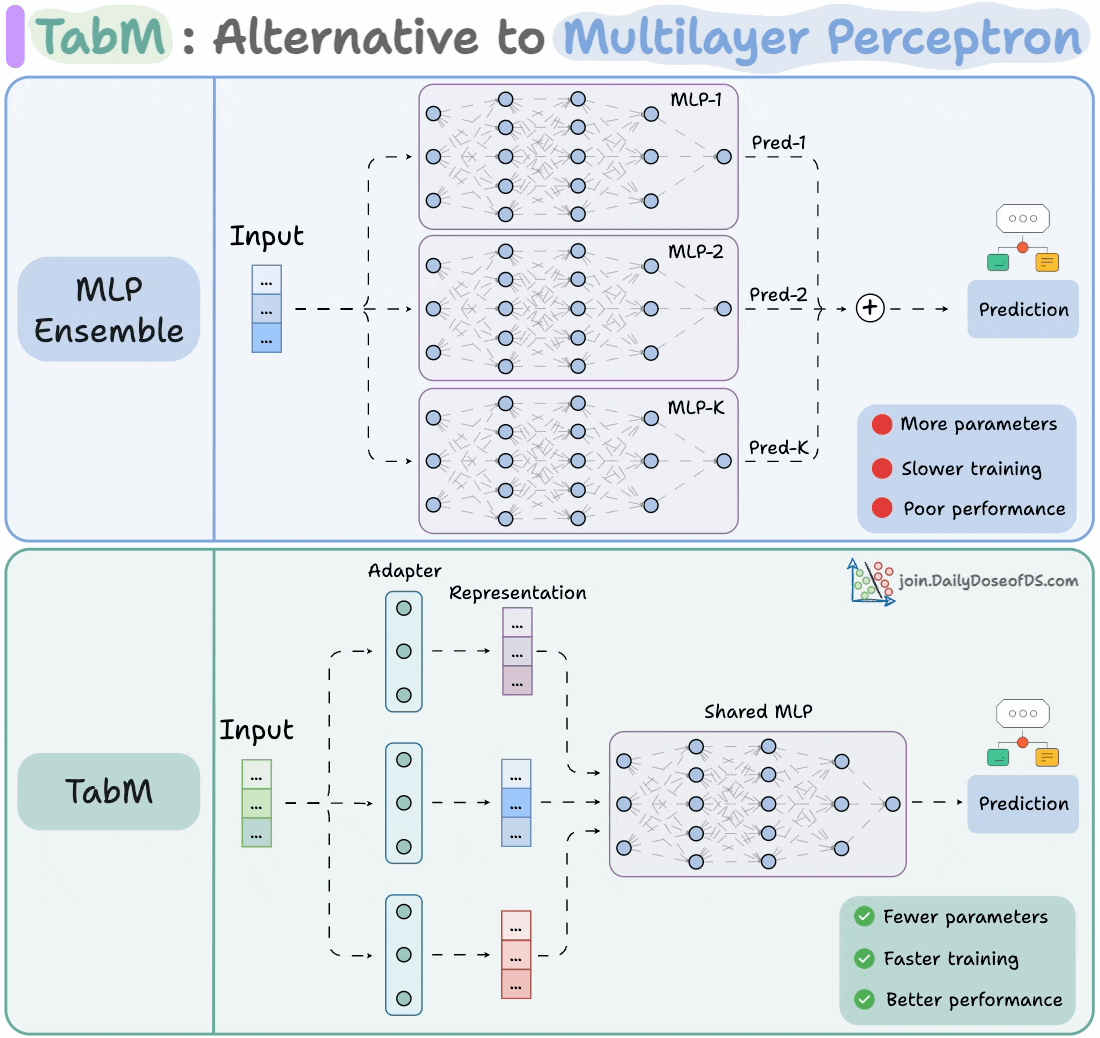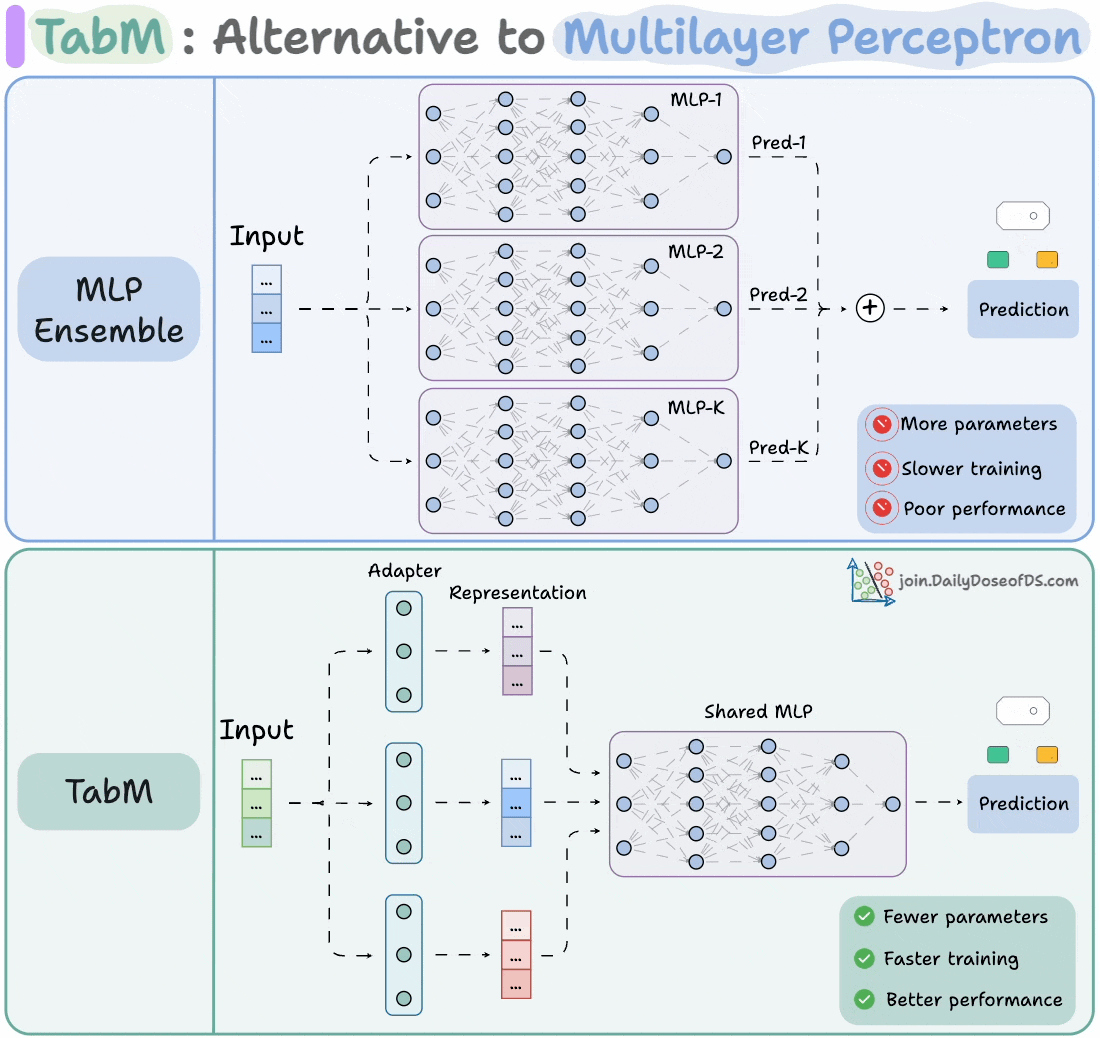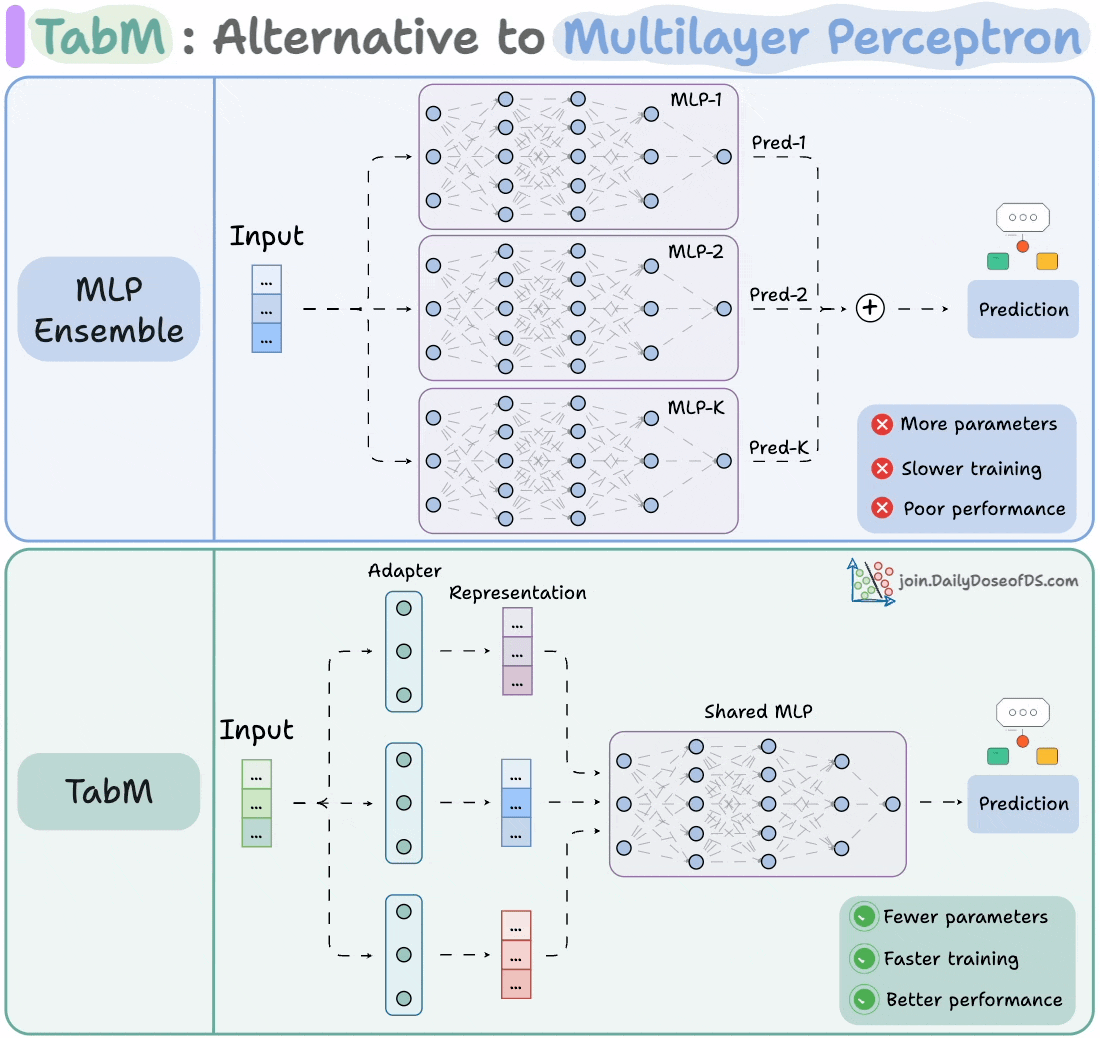
The visual shows how it differs from an MLP ensemble:
It was proposed at ICLR 2025, and it is a new architecture for tabular deep learning.
At its core, TabM is a parameter-efficient ensemble of MLPs.
The image below depicts an MLP ensemble:
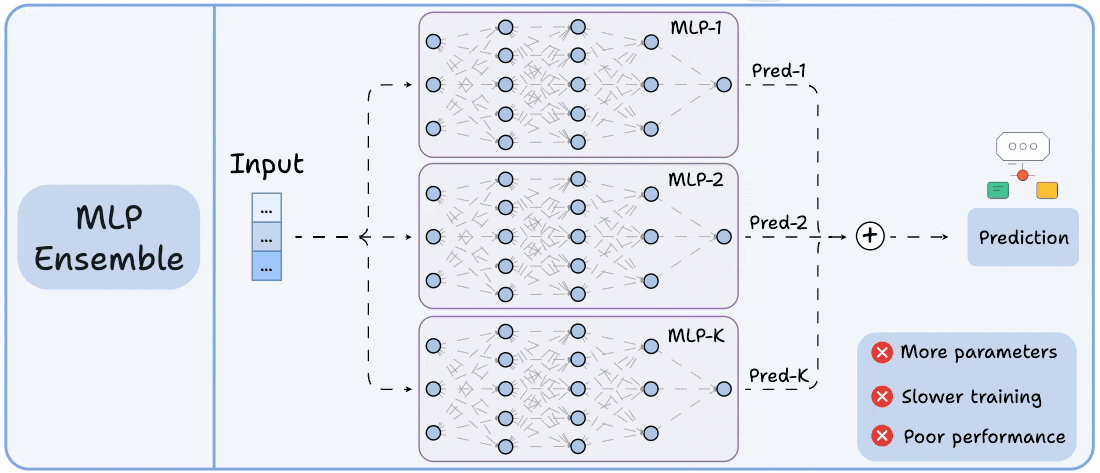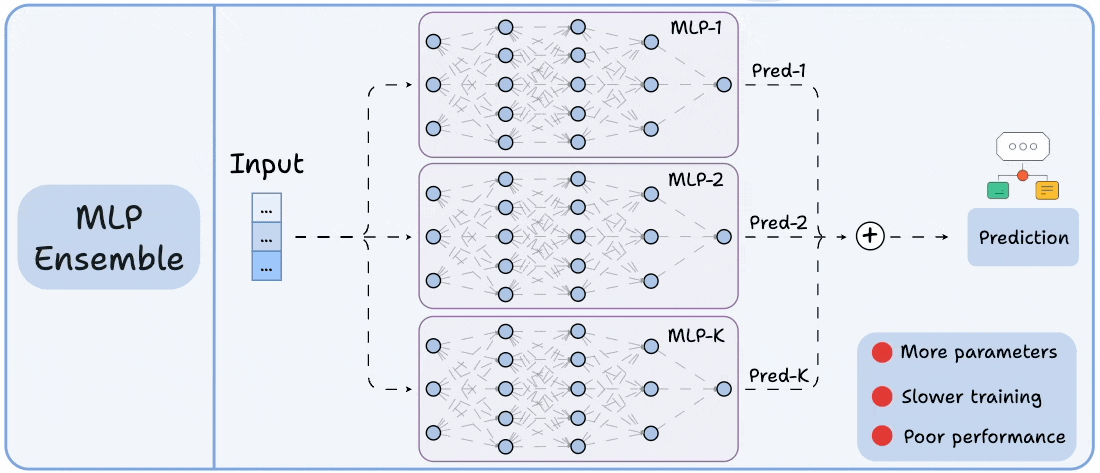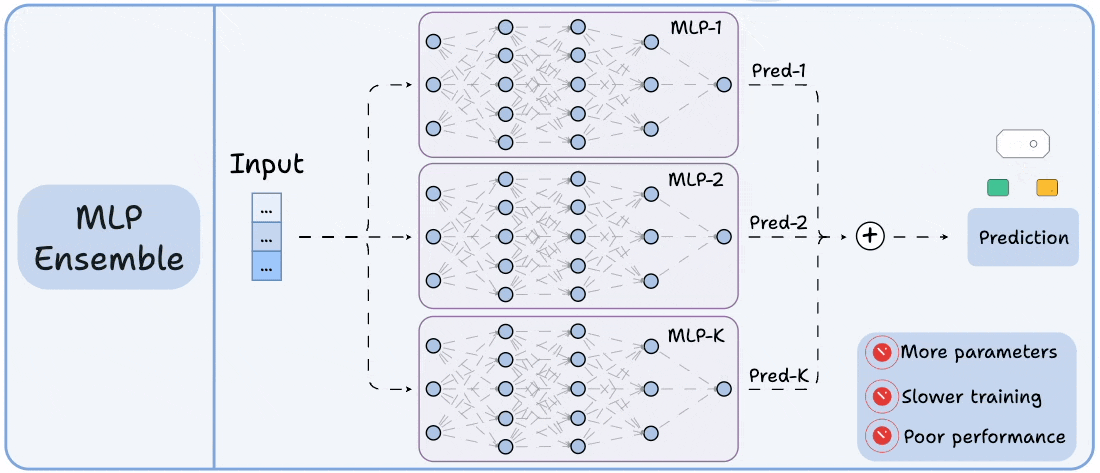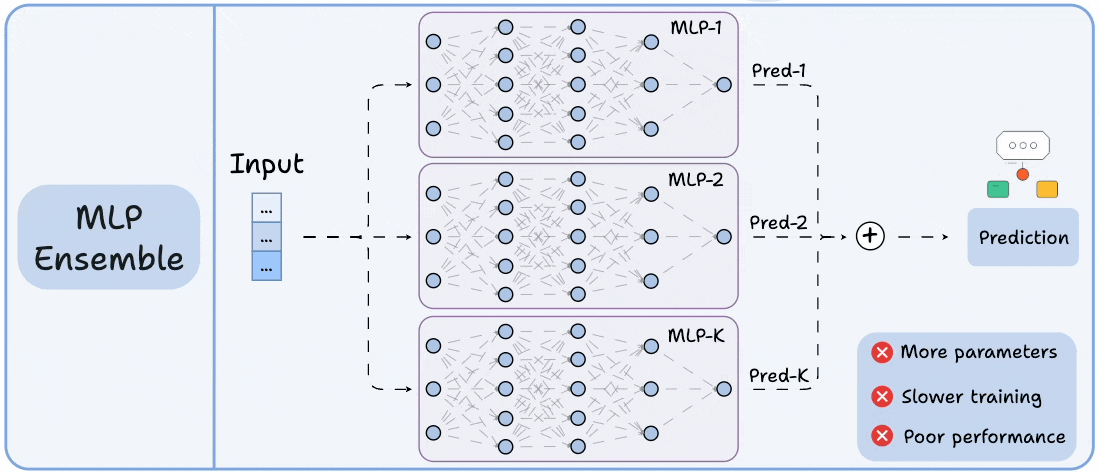
As you can tell, it is heavily parameterized.
Thus, in TabM, instead of training 32 (or K) separate MLPs, it uses one shared model and a lightweight adapter layer, as shown below.

This way, you get the benefits of ensembling (diversity, generalization, and robustness) without the cost of training multiple networks.
This tweak is powerful.
The chart below compares TabM against 15+ models across 46 benchmark datasets. This includes everything from basic MLPs to complex attention and retrieval-based architectures.

TabM-mini takes the top spot (rank 1.7), followed closely by TabM (rank 2.8). They are ahead of traditional models like XGBoost, CatBoost, and LightGBM. Transformers and retrieval-heavy models like FT-Transformer and SAINT rank much lower, despite being more complex.
In column 2, TabM models consistently outperform most baselines, even tree-based models. Transformers often show high variance (some datasets great, others poor), while TabM is more stable.
In column 3, TabM-mini and TabM again stand out, outperforming XGBoost and CatBoost here too.
The model trained faster than transformers, and in some cases, faster than MLP ensembles, especially with
torch.compileand mixed precision.
And as discussed earlier, TabM kept its parameter count low, making it scalable to large datasets and practical for real-world applications.
Thanks for reading!