
The 8 Layer Engineering Behind Production AI Systems
The full map of what the role now spans, and where to go deep on each layer.

Building inside the lines with Claude Fable 5
We spent a morning with Claude Fable 5, and it left us thinking about one thing, i.e., what an agent is allowed to do while it runs on its own.
Fable 5 runs for hours, holds a goal for days, and takes action without checking in. So the question stopped being what an agent can build. It became what it can touch while it runs.
We tested this with a plain internal tool.
Fable 5 wrote the SQL, pulled real records, and added a button that issued a refund straight to the database, all in one pass.
The build was easy, but deciding who can open it, who can run that refund, and keeping a record of what happened was the part the model could not handle on its own.
That part lives in the runtime, not the model.
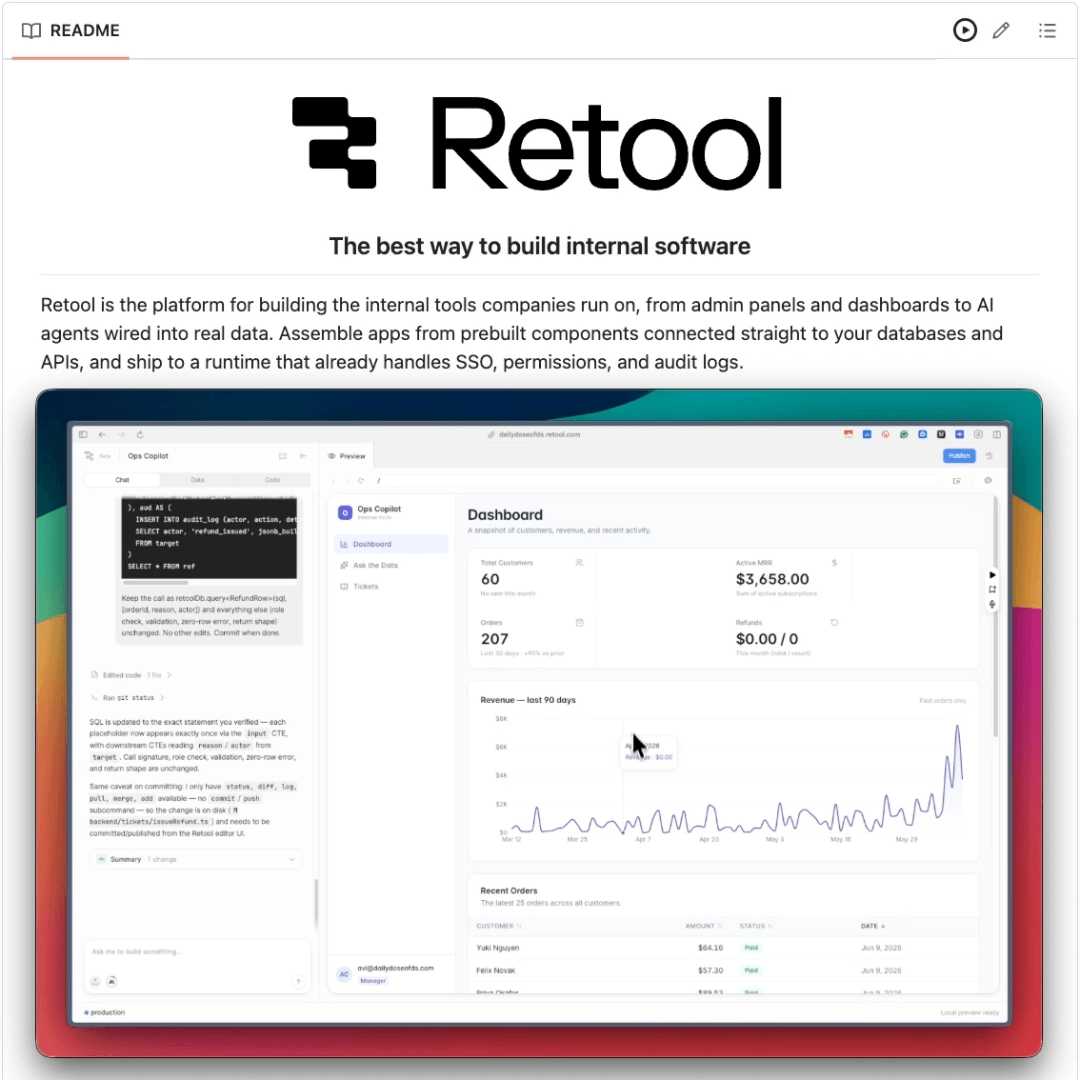
We deployed the same agent into Retool, and it picked up company SSO, a role check on the refund, and an audit log of every query and action. The app didn’t change, but where it ran did.
Retool calls this building inside the lines, and you’ll notice the difference once you watch the same agent run both ways.
You can try it out yourself here →
Thanks to Retool for partnering today!
AI concepts every AI engineer should know
Two teams can build on the same base model and ship completely different products.
The model is a fixed input. What differs is the eight layers of engineering wrapped around it, from how tokens get served to how the agent loop is controlled.
We mapped the full set into a single diagram:
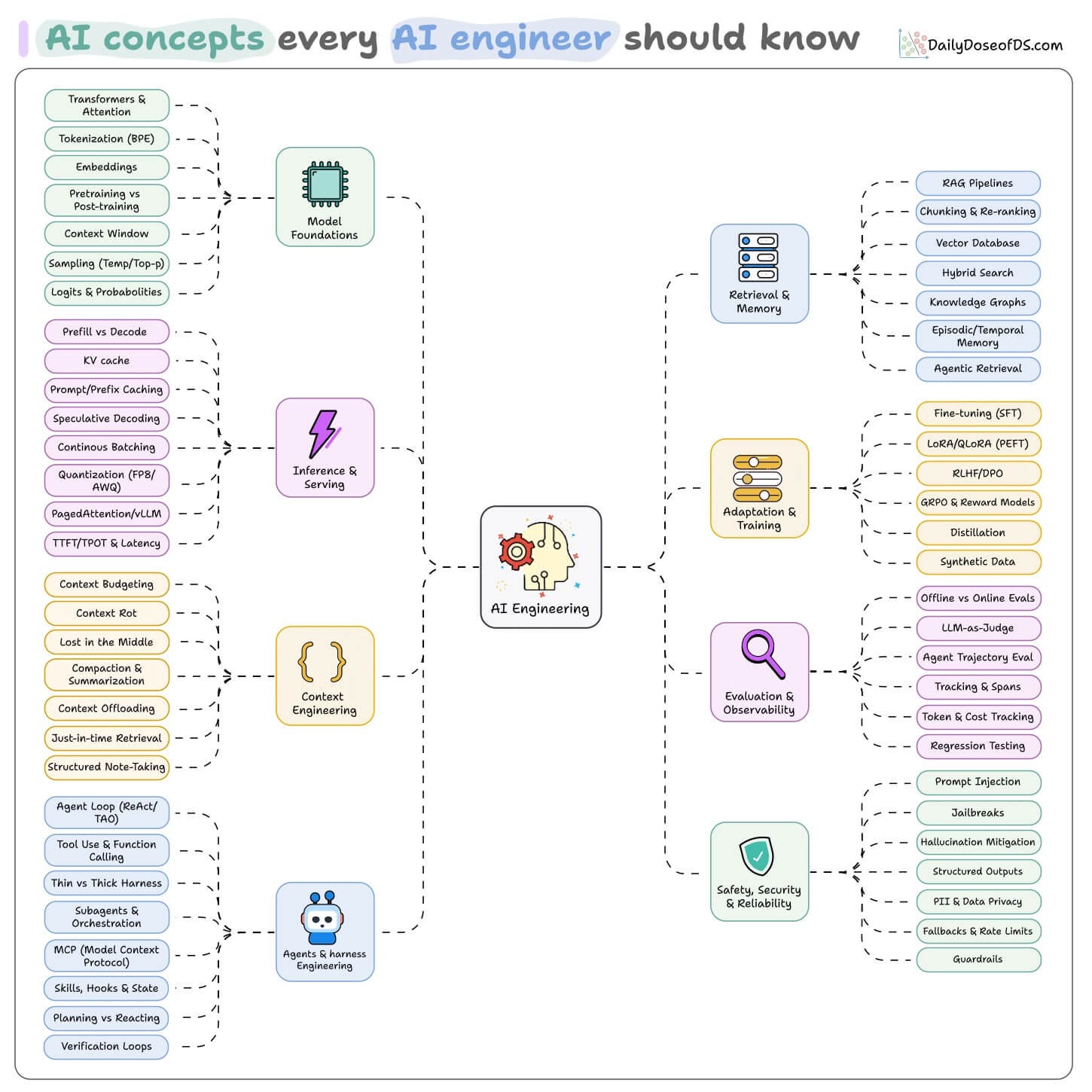
Model foundations cover how a model turns text into probabilities:
Tokenization splits text into subword unit before the model ever sees it, and token count drives both cost and context limits.
Embeddings map those tokens to high-dimensional vectors where similar meanings sit close together.
Pretraining learns language from raw text while post-training (SFT, RLHF) shapes behavior and alignment.
The context window is the fixed token budget the model attends to at once, shared across prompt, history, and output.
Logits are the raw scores over the vocabulary that sampling (explained below) turns into the actual output token.
Sampling controls how the next token is drawn from the distribution, with temperature and top-p trading determinism for diversity.
We covered this layer in depth (with code) here →
Inference and serving cover the stack that turns weights into cheap/fast tokens:
Prefill processes the whole prompt in parallel and is compute-bound, while decode generates one token at a time and is memory-bound.
The KV cache stores attention keys and values for past tokens so they aren’t recomputed at every step.
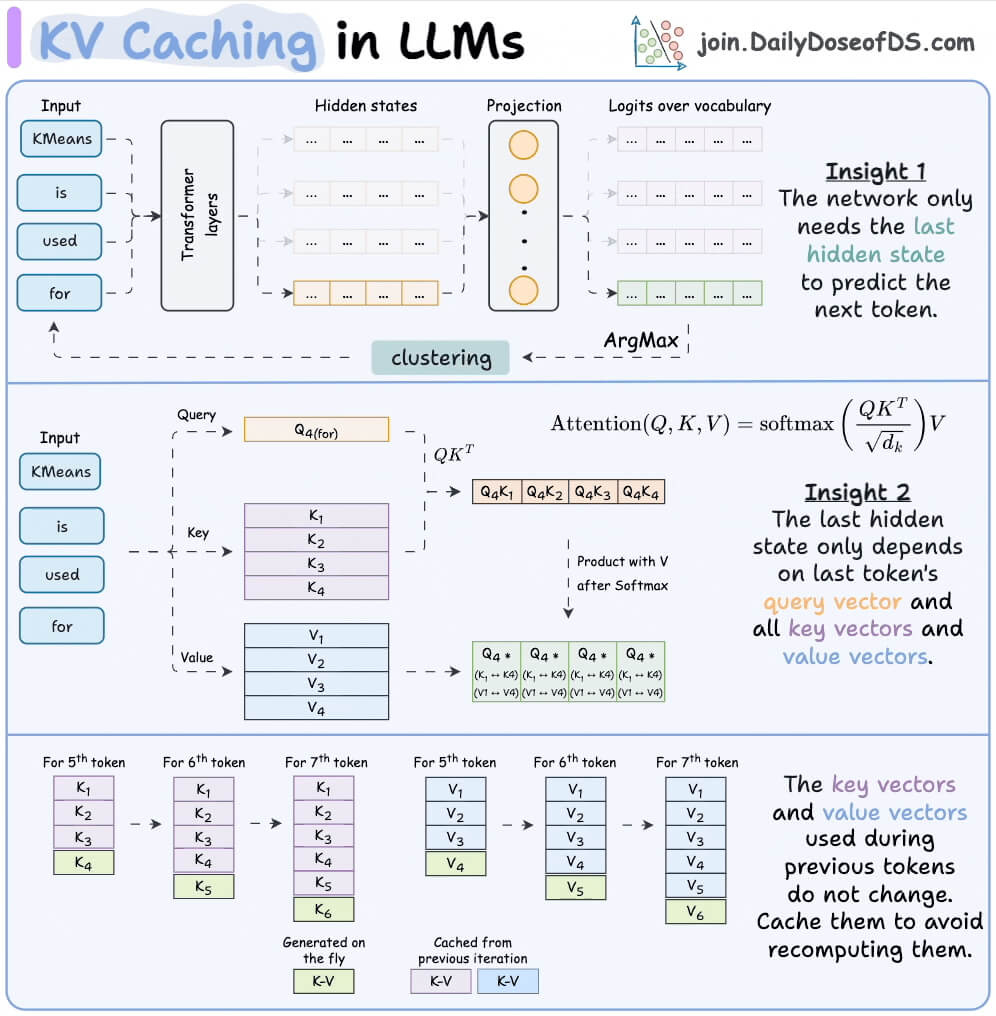
Prompt and prefix caching reuses the KV state of a shared prefix, which makes fixed system prompts effectively free after the first call.
Speculative decoding uses a small draft model to propose several tokens that the main model verifies in parallel for a net speedup.
Continuous batching fills GPU slots with new requests the moment others finish, instead of waiting for a whole batch to complete.
Quantization stores weights in fewer bits (FP8, AWQ) to cut memory and speed up compute, with FP8 running natively on recent GPUs.
Paged Attention applies OS-style paging to the KV cache to remove fragmentation, and it’s the core trick behind vLLM.
TTFT and TPOT measure prefill and decode speed respectively, and both trade against raw throughput.
We covered this layer in depth (with code) here →
Context engineering involves managing what the model sees at the moment it acts:
Context budgeting treats the window as a finite resource and spends tokens only on what raises answer quality.
Context rot is the way output quality degrades as the window fills, often well before the hard limit.
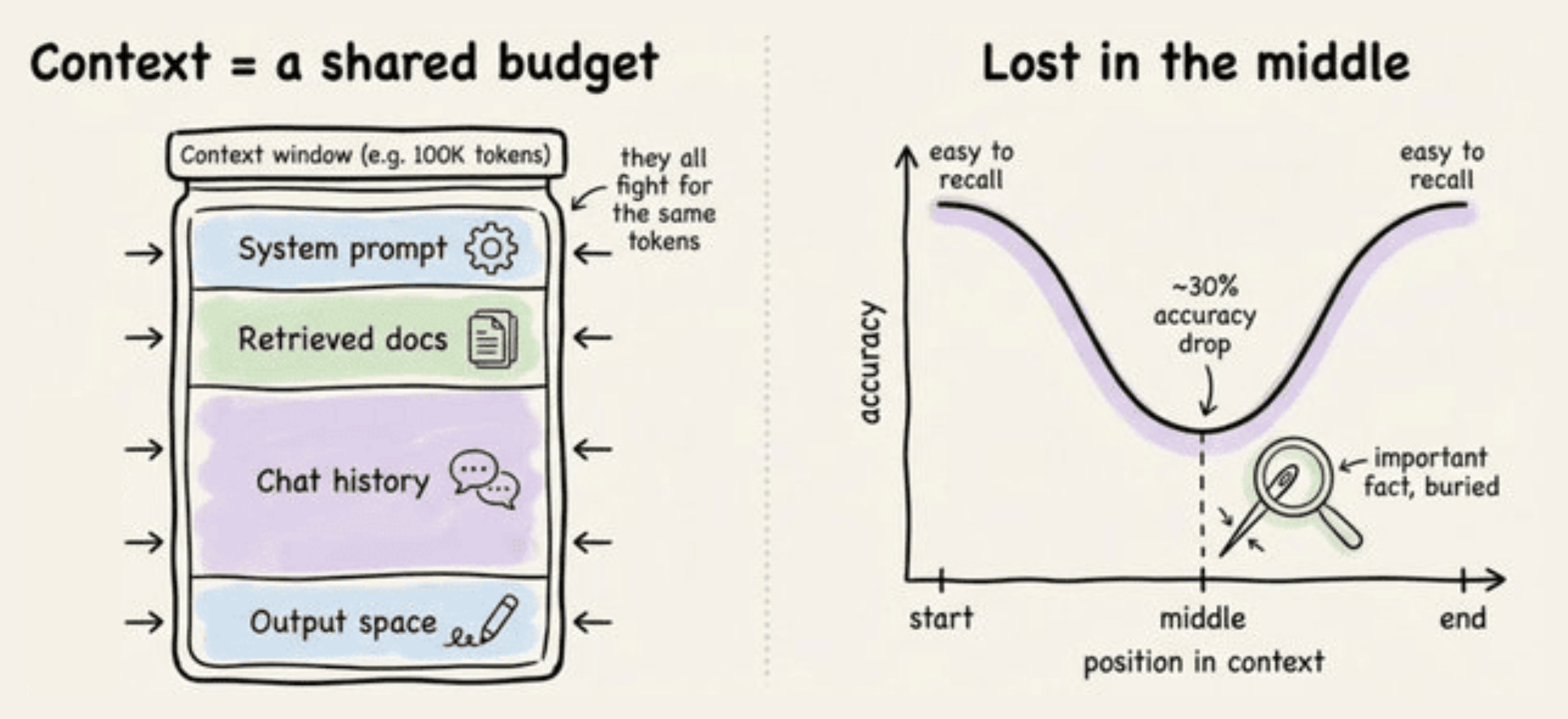
Lost in the middle describes how models attend most to the start and end of the context, so details buried in the middle get underweighted.
Compaction and summarization condense old history into a high-fidelity summary so the agent can continue in a fresh window.
Context offloading pushes large details to external files or stores and keeps only a reference in the window.
Just-in-time retrieval loads data at the step that needs it rather than front-loading everything upfront.
Structured note-taking lets the agent write persistent notes outside the window and read them back as needed.
We covered this layer in depth (with code) here →
Agents and harness engineering a stateless model into something that finishes tasks.
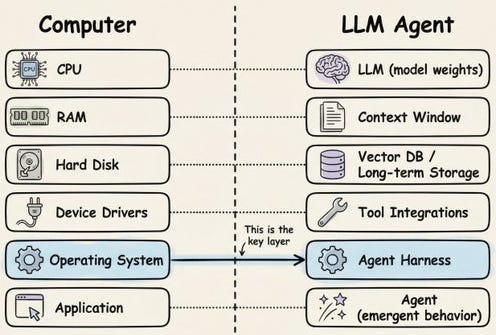
The agent loop runs the think, act, observe cycle (ReAct or TAO) until the task is done.
Tool use and function calling let the model emit structured calls that the harness executes, feeding the results back to the model.
A thin harness trusts the model and keeps infrastructure minimal, while a thick harness encodes control in code and leaves less to the model.
Subagents and orchestration spin off focused agents with their own context so the main agent stays lean.
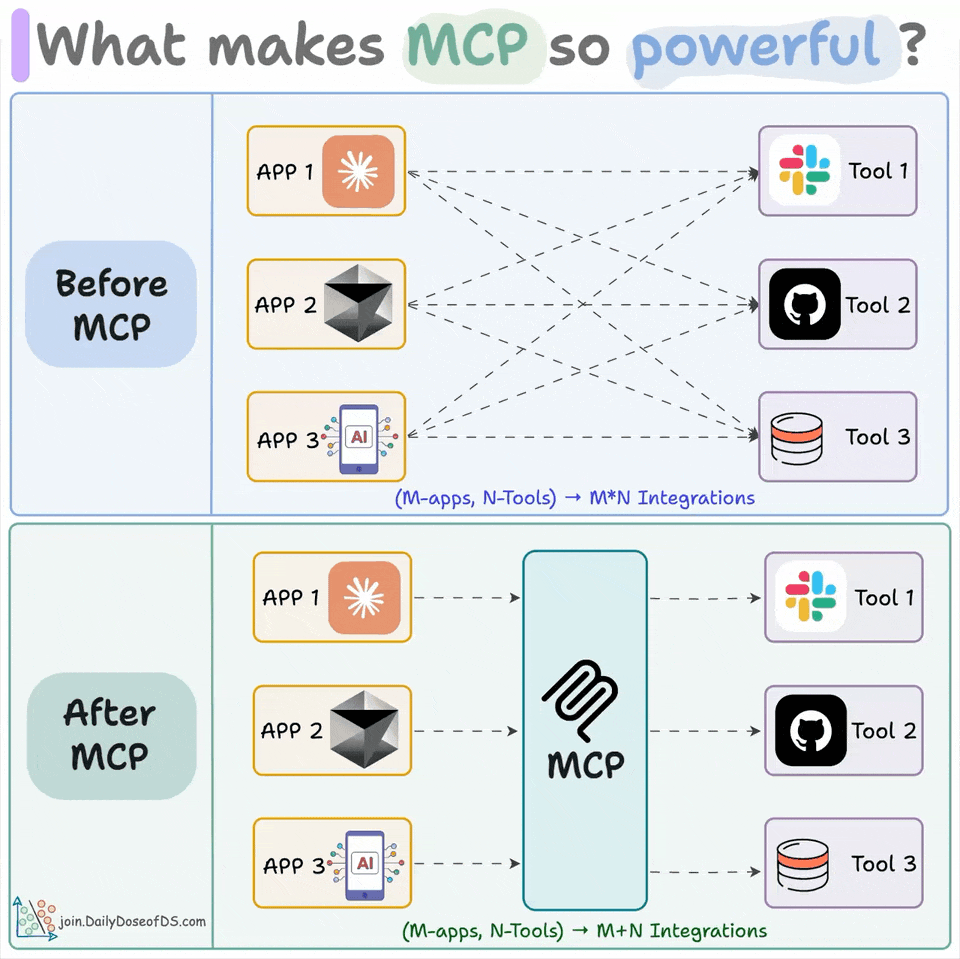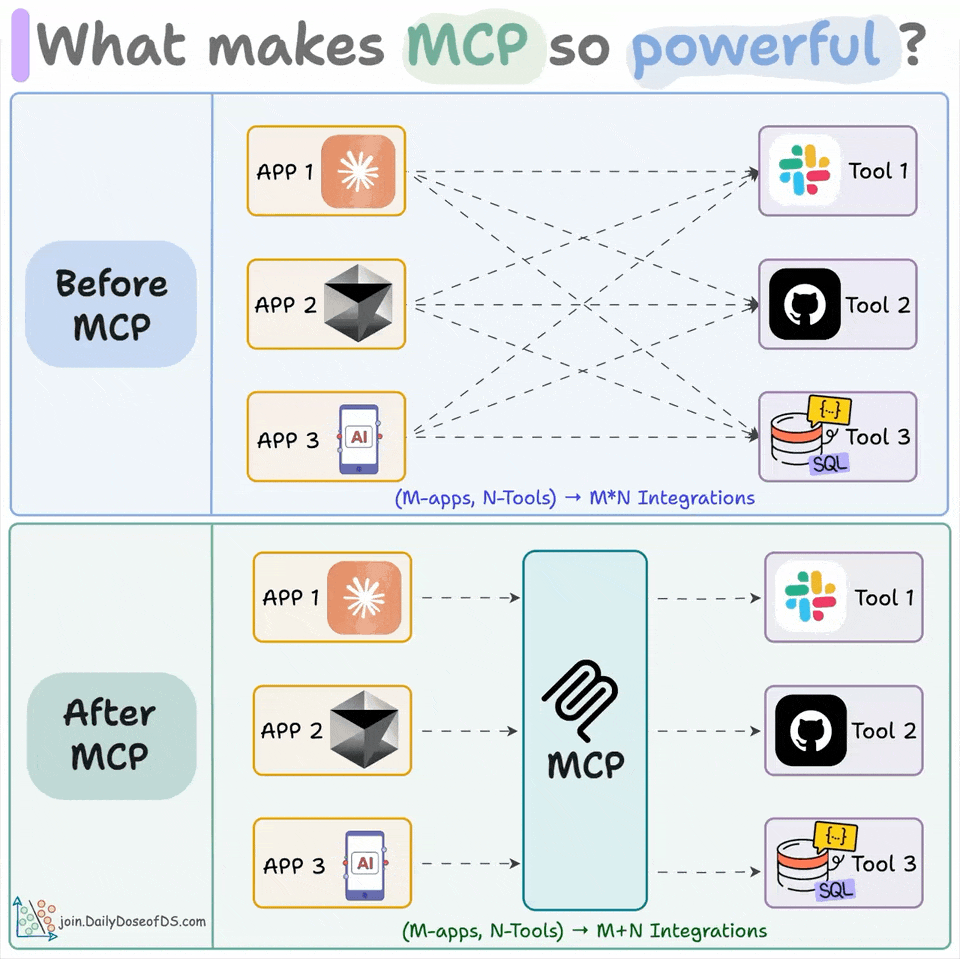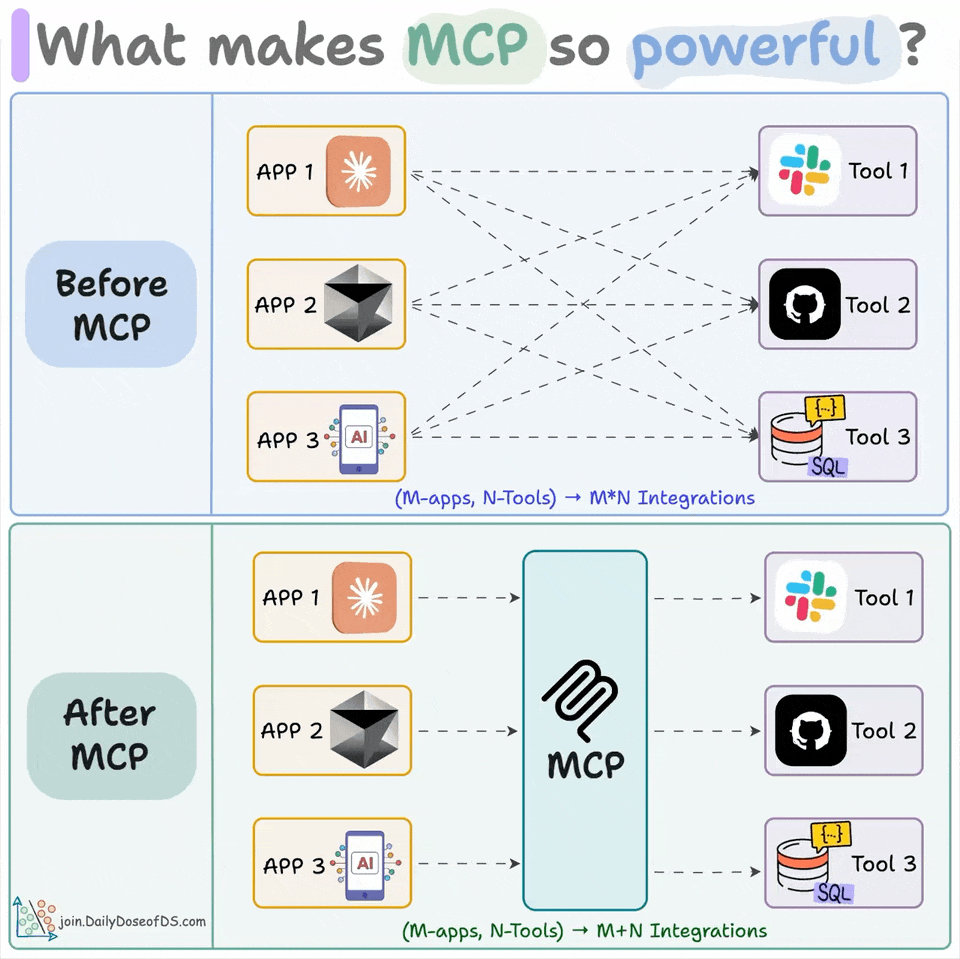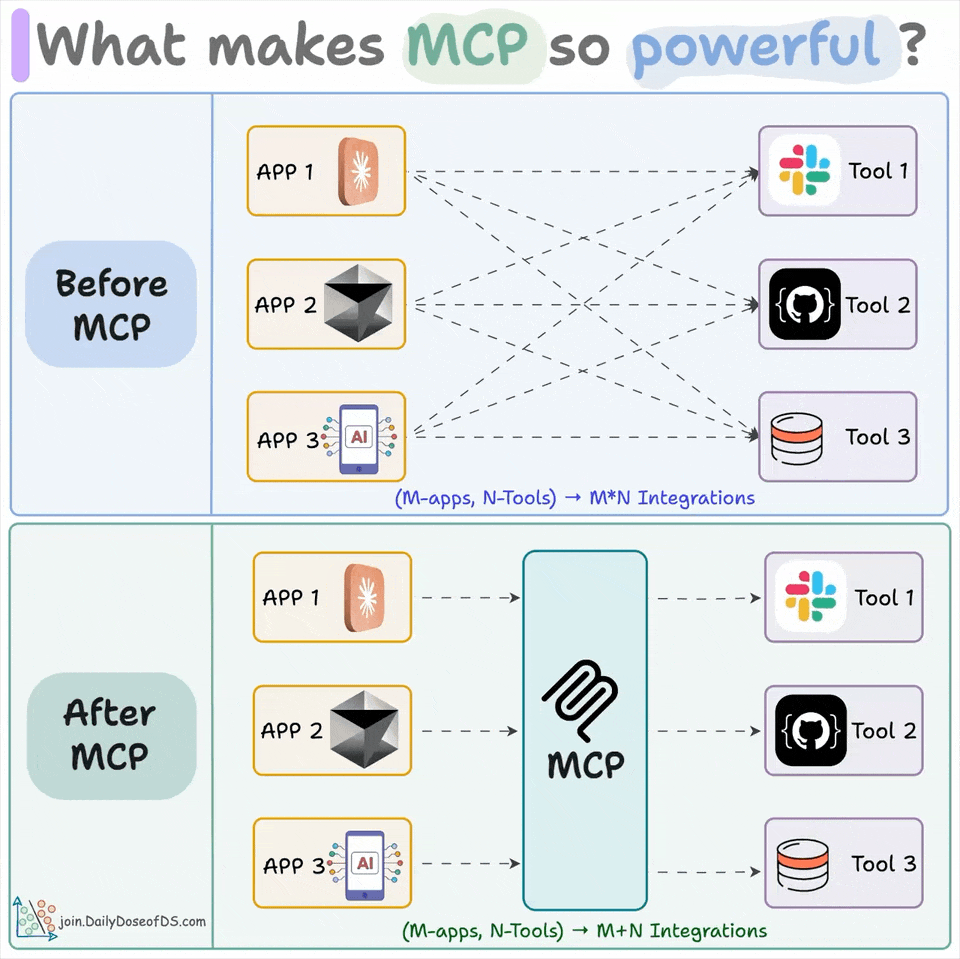
MCP is a standard interface connecting models to tools and data, replacing N×M custom integrations.
Skills, hooks, and state add reusable capabilities, lifecycle triggers, and persisted memory that survive across steps.
Planning versus reacting is the choice between committing to a plan upfront and deciding each step live, with different speed and cost.
Verification loops use rules, tests, or an LLM judge to gate the agent’s output before it counts as done.
We covered the Anatomy of Agent Harness here →
Retrieval and memory feed the model facts it was never trained on.
RAG pipelines retrieve relevant chunks at query time and add them to the prompt before generation.
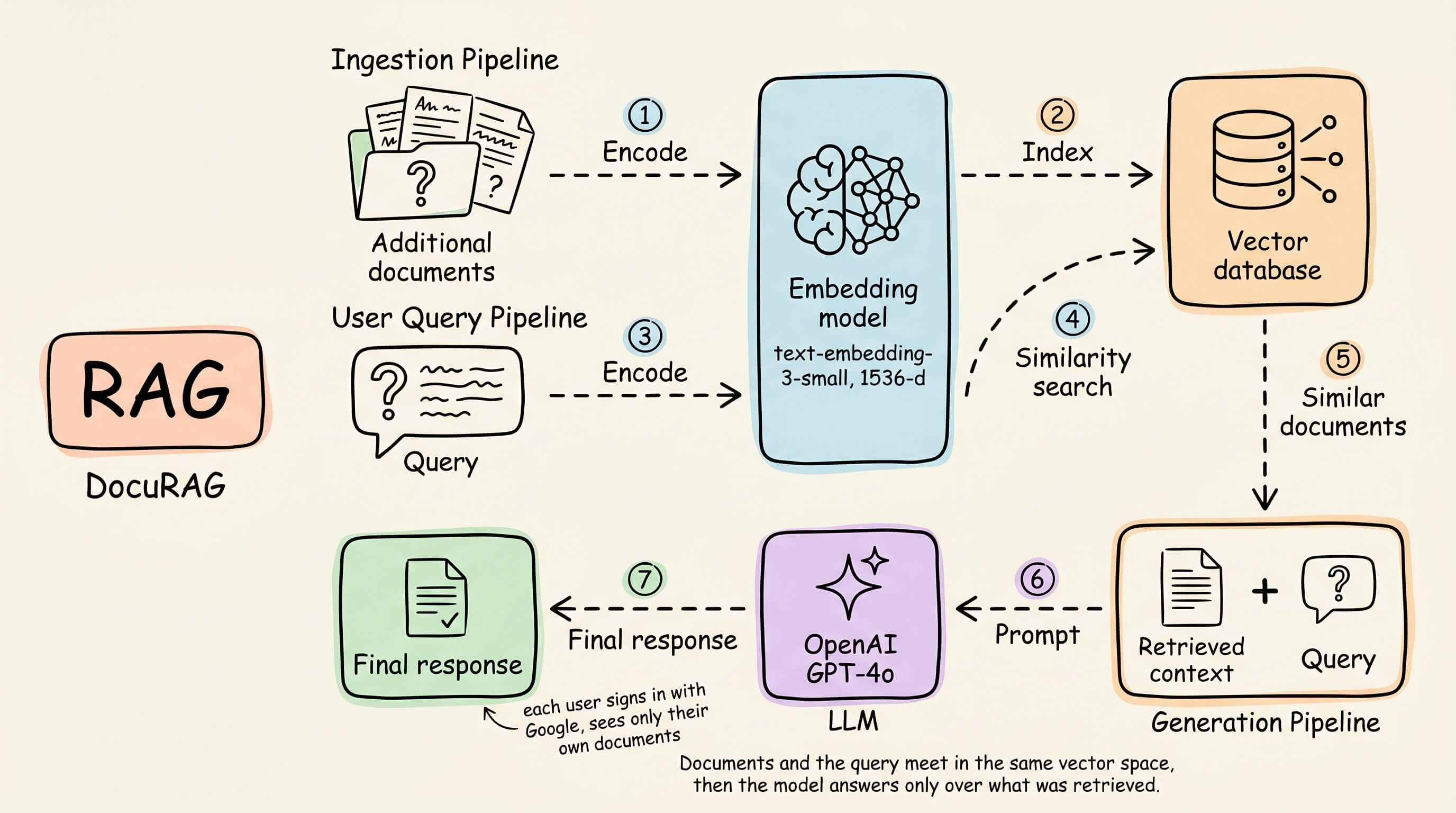
Chunking and re-ranking split documents into units and then reorder retrieved candidates by true relevance.
A vector DB stores embeddings and serves nearest-neighbor search at scale.
Hybrid search combines keyword and vector matching to catch both exact terms and semantic matches.
Knowledge graphs model entities and relationships so retrieval can follow connections, not just similarity.
Episodic and temporal memory keep what happened and when, so the agent recalls past sessions and how facts changed.
Agentic retrieval lets the agent issue and refine its own queries instead of running a single fixed lookup.
We covered this layer in depth (with code) here →
Adaptation and training change the weights when prompting and context aren’t enough:

Fine-tuning (SFT) trains the model on input-output examples to teach format and behavior.
LoRA and QLoRA (PEFT) train small adapter weights instead of the full model, which cuts cost and memory sharply.
RLHF and DPO optimize against human preferences, with DPO skipping the separate reward model.
GRPO and reward models train against a reward signal, which works when you have a scoring function but no preference labels.
Distillation trains a smaller student to match a larger teacher, keeping most of the accuracy at lower cost.
Synthetic data generates training examples with a model when real labeled data is scarce.
We covered this layer in depth (with code) here →
Evaluation and observability help track whether a change helped or quietly broke something.
Offline and online evals run fixed test sets before shipping, and live metrics from real traffic after.
LLM-as-judge uses a model to score open-ended output that rules can’t grade.
Agent trajectory eval judges the full path an agent took, not just the final answer.
Tracing and spans record each step, tool call, and token so you can see where a run went wrong.
Token and cost tracking attributes spend per request and per step to find what’s expensive.
Regression testing re-runs a benchmark after a prompt or model change to catch silent breakage.
We covered this layer in depth (with code) here →
Safety, security and reliability keep the system honest in front of real users.
Prompt injection is untrusted input that smuggles in instructions to hijack the model’s behavior.
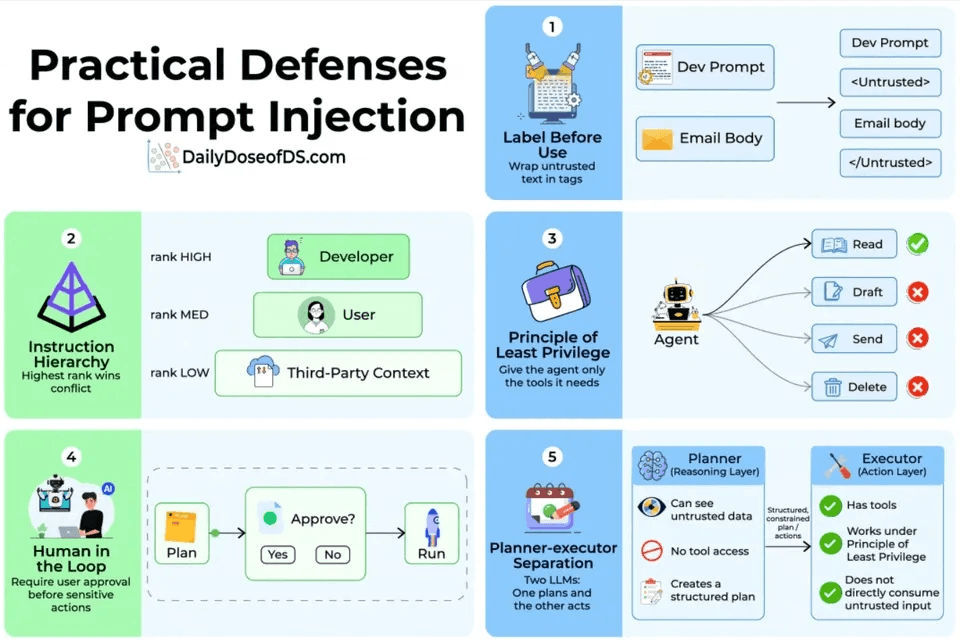
Jailbreaks are crafted prompts that get the model to bypass its own safety constraints.
Hallucination mitigation uses grounding, retrieval, and verification to catch confident wrong answers.
Structured outputs constrain generation to valid JSON or a schema so downstream code can parse it.
PII and data privacy controls detect and redact sensitive data before it enters or leaves the model.
Fallbacks and rate limits add multi-provider failover and request caps that keep the system up under load.
Guardrails are input and output filters that block unsafe or off-policy requests and responses.
We covered this layer in depth (with code) here →
The inference layer is where most production cost hides.
On an H100 running Llama 70B, a single request hits 92% GPU utilization during prefill, then drops to 28% during decode on the same hardware a moment later. The workload changed, not the GPU.
No single technique moves that number much. Stacking eight or nine of them, across compression, attention, decoding, caching, and routing, is what closes a 5-8x cost gap against naive FP16 inference.

We broke down all 72 of these techniques, with the engineering logic behind each, in this issue and across the full LLMOps crash course.
For routing trivial queries to cheaper models, the advisor strategy is another interesting path to start with.
👉 Over to you: which of the eight layers do you spend the most time in?
Thanks for reading!