
The Anatomy of Diffusion LLMs
...explained from scratch!

This week’s deep dive covers one of the most important architectural shifts happening in language modeling right now: diffusion LLMs.
Read the full Part 1 deep dive here →
It builds a complete understanding from first principles:
how autoregressive generation is structurally memory-bandwidth bound)
why Gaussian noise can’t work on discrete tokens
how masked diffusion solves this with an ELBO-derived training objective
the math behind the forward and reverse processes
unmasking strategies
block diffusion for KV cache compatibility
and a detailed engineering comparison between the two paradigms.
Read the full Part 1 deep dive here →
Why care?
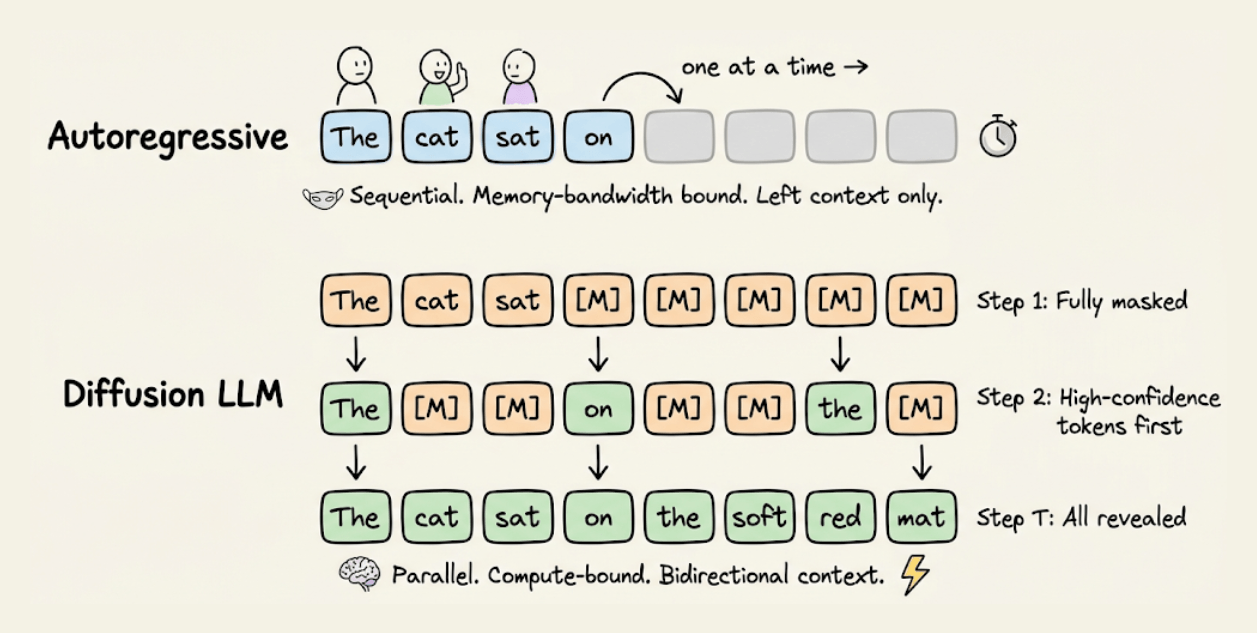
Every production LLM today, GPT-4, Claude, Gemini, LLaMA, generates text the same way: one token at a time, left to right.
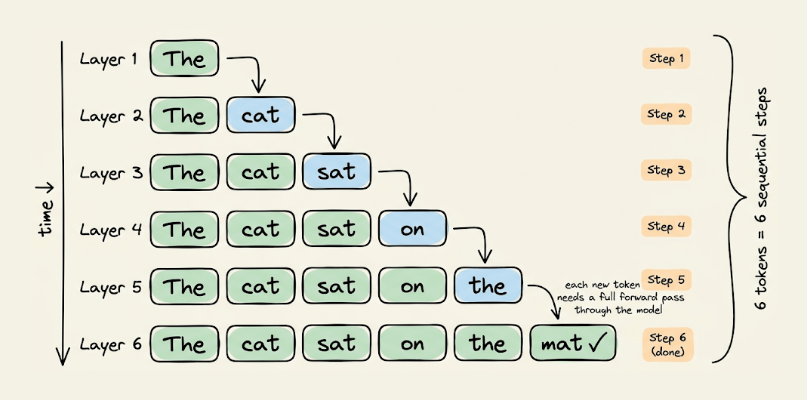
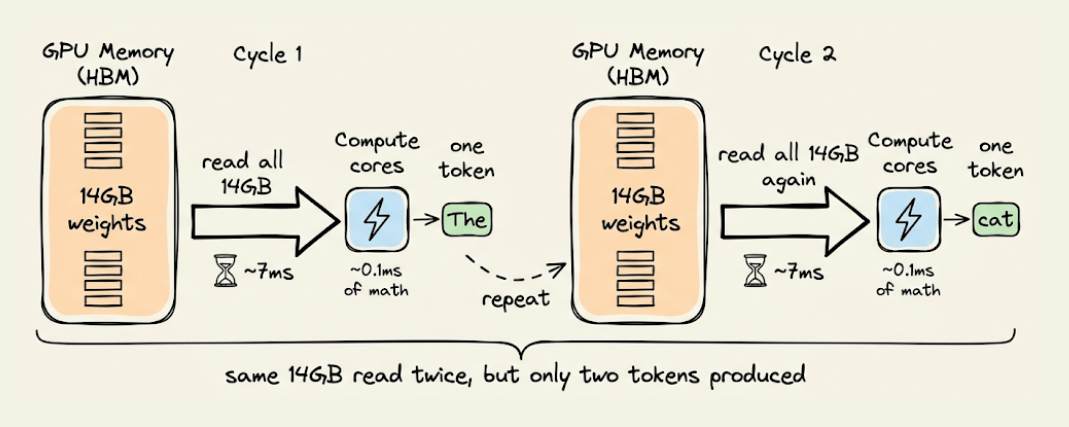
Each token requires loading the full model weights through GPU memory, performing a tiny computation, and then loading all the weights again for the next token. On an A100, this means roughly 1 FLOP per byte of data moved, while the GPU is designed for 100+ FLOPs per byte.
Diffusion LLMs take a completely different approach. They start with a fully masked sequence and iteratively unmask all tokens in parallel, using bidirectional attention at every step. This shifts inference from memory-bandwidth bound to compute-bound, which is exactly where modern GPUs are efficient.
The results are catching up fast. Block diffusion (BD3-LM) is within 0.5 perplexity points of autoregressive on LM1B. LLaDA at 8B parameters matches LLaMA 3 on MMLU and exceeds it on TruthfulQA and HumanEval. And models like Dream 7B are already being served in production with SGLang.
Understanding how it works at a mathematical level, from the forward masking process to the ELBO objective to block-level KV caching, is going to be increasingly valuable as these models scale.
You can read the Part 1 here →
👉 Over to you: Do you think the future of LLM generation is pure diffusion, pure autoregressive, or some hybrid of the two?
Thanks for reading!