
The Anatomy of Diffusion LLMs
...explained from scratch!

Part 2 of the diffusion LLMs deep dive is live. Part 1 mostly covered the background and foundations, and this one gives you the engineering with hands-on implementations.
Read the full Part 2 deep dive here →
It covers:
the training techniques that scaled dLLMs from 8B to 100B parameters (including converting pre-trained autoregressive models like LLaMA into diffusion models via attention mask annealing)
the inference acceleration stack (block-wise KV caching with Fast-dLLM, confidence-aware parallel decoding, token editing with LLaDA 2.1),
production serving with SGLang
hands-on code for running Dream 7B and serving LLaDA 2.0,
and a decision framework for when dLLMs actually make sense over autoregressive models.
Read the full Part 2 deep dive here →
Why care?
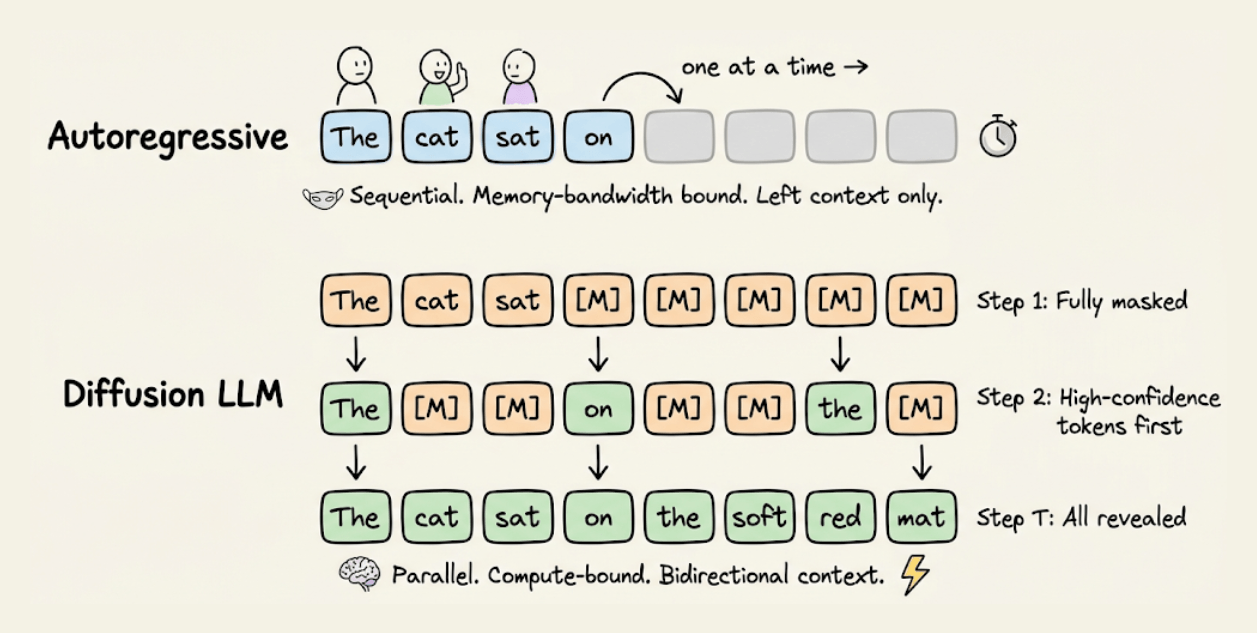
Every production LLM today, GPT-4, Claude, Gemini, LLaMA, generates text the same way: one token at a time, left to right.
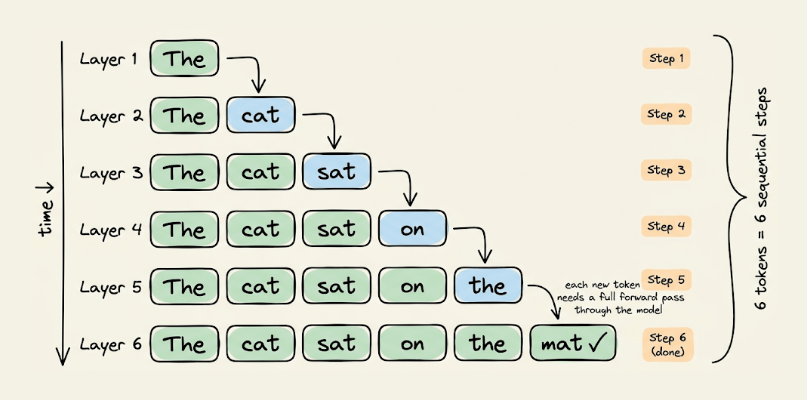
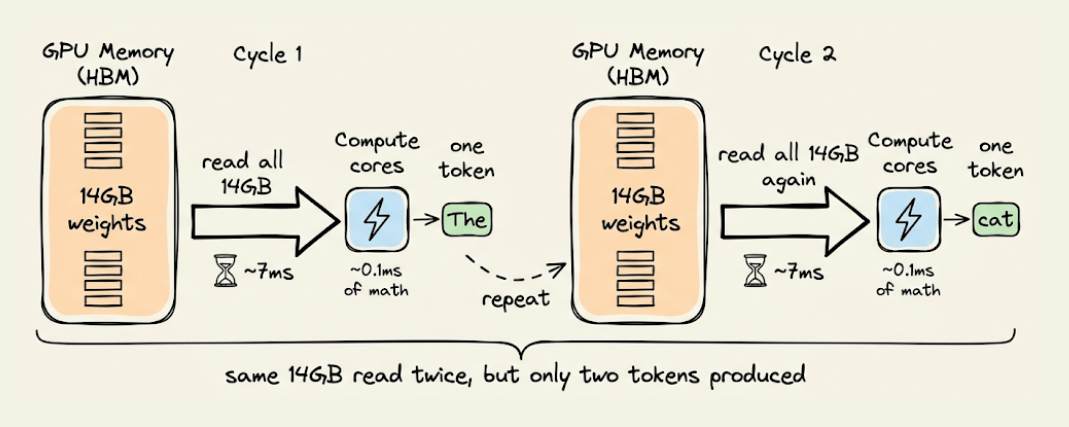
Each token requires loading the full model weights through GPU memory, performing a tiny computation, and then loading all the weights again for the next token. On an A100, this means roughly 1 FLOP per byte of data moved, while the GPU is designed for 100+ FLOPs per byte.
Diffusion LLMs take a completely different approach. They start with a fully masked sequence and iteratively unmask all tokens in parallel, using bidirectional attention at every step. This shifts inference from memory-bandwidth bound to compute-bound, which is exactly where modern GPUs are efficient.
The results are catching up fast.
Block diffusion (BD3-LM) is within 0.5 perplexity points of autoregressive on LM1B. LLaDA at 8B parameters matches LLaMA 3 on MMLU and exceeds it on TruthfulQA and HumanEval. And models like Dream 7B are already being served in production with SGLang.
But knowing that dLLMs exist and knowing how to train them, serve them, and decide when they are the right choice over autoregressive models are very different things.
Part 2 covers the full practical stack, like how teams are converting existing AR checkpoints into dLLMs at a fraction of the training cost, what makes inference fast in practice, and how to run Dream 7B and serve LLaDA 2.0 with code you can execute.
If you haven’t read Part 1, start there first. It covers the theory, math, and generation mechanics that this article builds on.
And you can read Part 2 for practical implementations here →
👉 Over to you: Do you think the future of LLM generation is pure diffusion, pure autoregressive, or some hybrid of the two?
Thanks for reading!