
The Biggest Mistake ML Folks Make When Using Multiple Embedding Models
...that often goes unnoticed.

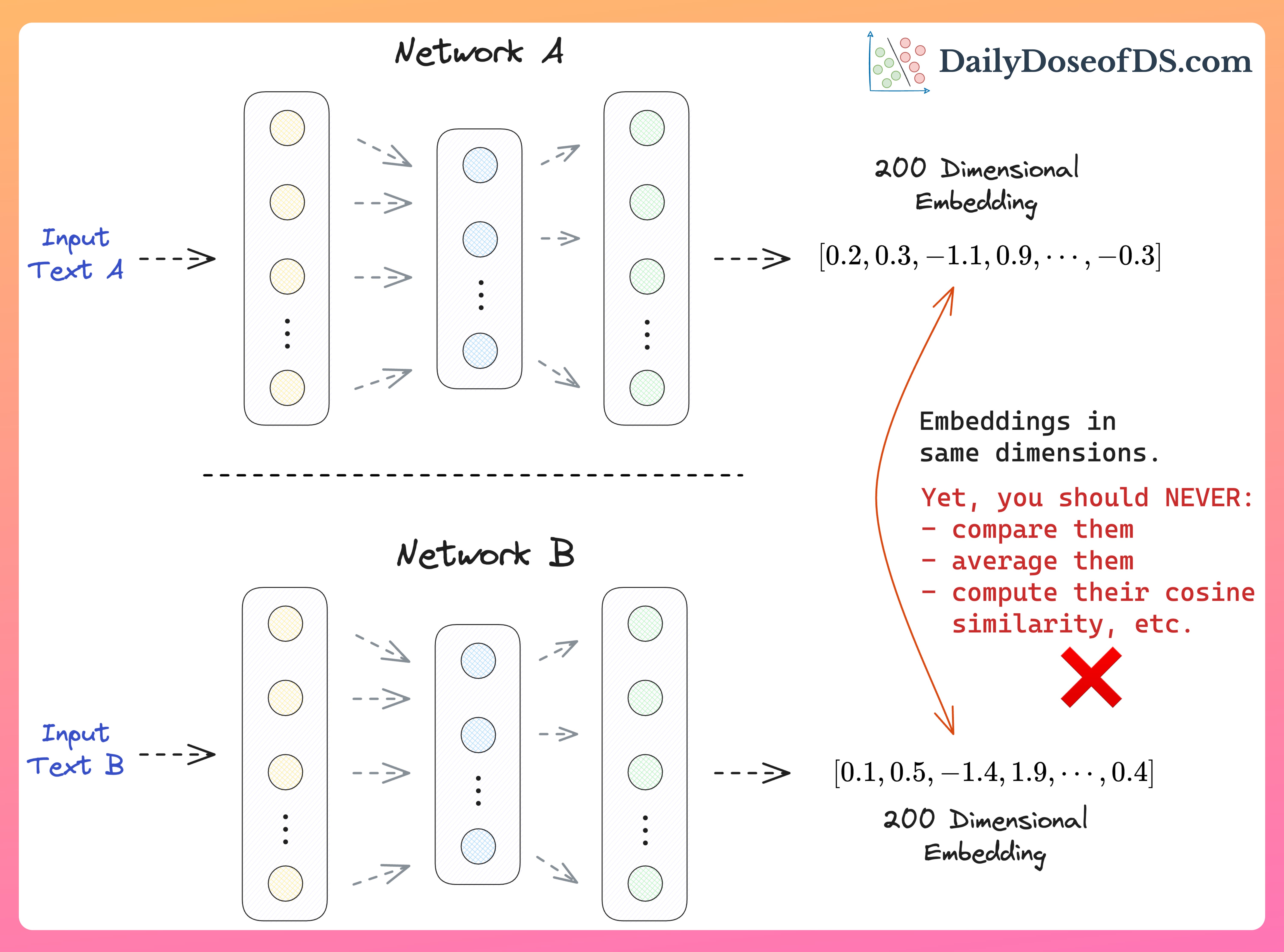
Imagine you have two different models (or sub-networks) in your whole ML pipeline.
Both generate a representation/embedding of the input in the same dimensions (say, 200).

These could also be pre-trained models used to generate embeddings—Bert, XLNet, etc.
Here, many folks get tempted to make them interact.
They would:
compare these representations
compute their Euclidean distance
compute their cosine similarity, and more.
The rationale is that the representations have the same dimensions. Thus, they can seamlessly interact.
However, that is NOT true, and you should NEVER do that.
Why?
Even though these embeddings have the same length, they are out of space.
Out of space means that their axes are not aligned.
To simplify, imagine both embeddings were in a 3D space.
Now, assume that their z-axes are aligned.
But the x-axis of one of them is at an angle to the x-axis of the other.

As a result, coordinates from these two spaces are no longer comparable.
Similarly, comparing the embeddings from two networks would inherently assume that all axes are perfectly aligned.
But this is highly unlikely because there are infinitely many ways axes may orient relative to each other.
Thus, the representations can NEVER be compared, unless they are generated by the same model.
This is a mistake that may cause some serious trouble in your ML pipeline.
Also, it can easily go unnoticed, so it is immensely crucial to be aware of this.
Hope that helped!
👉 Over to you: How do you typically handle embeddings from multiple models?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.