
The Biggest Source of Friction in ML Pipelines That Everyone is Overlooking
The guide that every everyone must read to manage ML experiments like a pro.

In my experience, most ML projects lack a dedicated experimentation management/tracking system.
As the name suggests, this helps us track:
Model configuration → critical for reproducibility.
Model performance → essential in comparing different models.
…across all experiments.
Yet, most ML projects typically leverage manual systems, wherein, they track limited details like:
Final performance (ignoring the epoch-wise convergence)
Hyperparameters, etc.
But across experiments, so many things can change vary:

Hyperparameters
Data
Model type
Accurately tracking every little detail can be quite tedious and time-consuming.
What’s more, consider that our ML pipeline has three steps:

If we only made some changes in model training (step 3), say, we changed a hyperparameter, does it make any sense to rerun the first two steps?
No, right?
Yet, typically, most ML pipelines rerun the entire pipeline, wasting compute resources and time.
Of course, we may set some manual flags to avoid this.
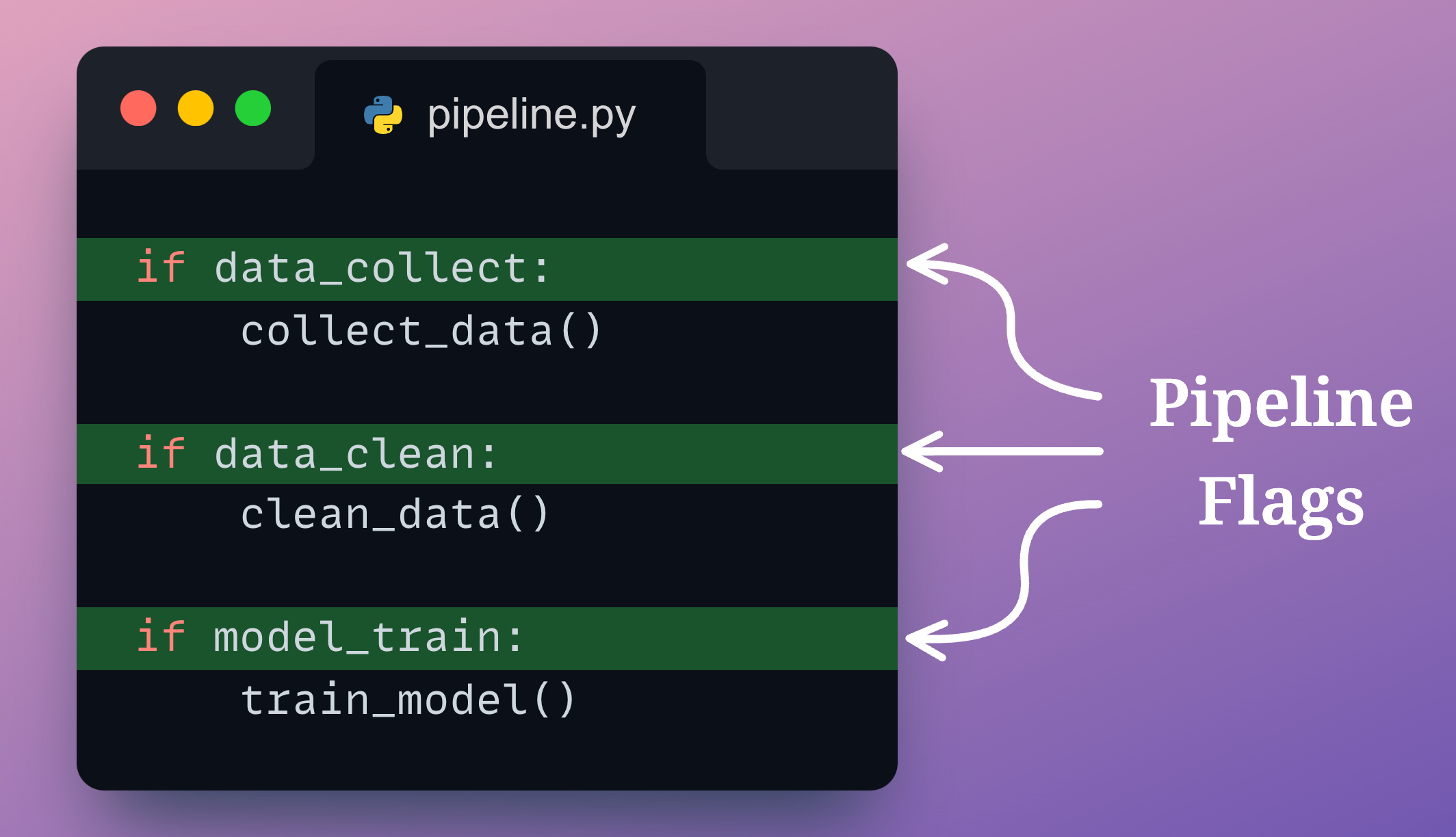
But being manual, it will always be prone to mistakes.
To avoid this hassle and unnecessary friction, an ideal tracking system must be aware of the following:
All changes made to an ML pipeline.
The steps it can avoid rerunning.
The only steps it must execute to generate the final results.
While the motivation is quite clear, this is a critical skill that most people ignore, and they continue to leverage highly inefficient and manual tracking systems — Sheets, Docs, etc.
To help you develop this critical skill, I’m excited to bring you a special guest post by Bex Tuychiev.
Bex is a Kaggle Master, he’s among the top 10 AI/ML writers on Medium, and I am a big fan of his writing.
Bex has very kindly stepped in to contribute a practical deep dive to Daily Dose of Data Science, so a huge shout out to him for doing this.

In today’s machine learning deep dive, he will continue where we left off last week — data version control.
More specifically, this article will expand on further highly useful features of DVC for machine learning projects: How to (Massively) Streamline Your Machine Learning Workflow With DVC.
The article has been divided into two parts, and by the end of this article, you will learn:
How to efficiently track and log your ML experiments?
How to build efficient ML pipelines?
👉 Interested folks can read it here: How to (Massively) Streamline Your Machine Learning Workflow With DVC.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!