
The Categorisation of Discriminative Models
...and when to prefer a specific type of model.

In yesterday’s post, we discussed the differentiation between Generative and Discriminative Models. Here’s the visual from that post for a quick recap:
In today’s post, we shall dive into a further categorization of discriminative models.
Today, we shall dive into the categorization of discriminative models.
But let’s recap what we discussed yesterday real quick!
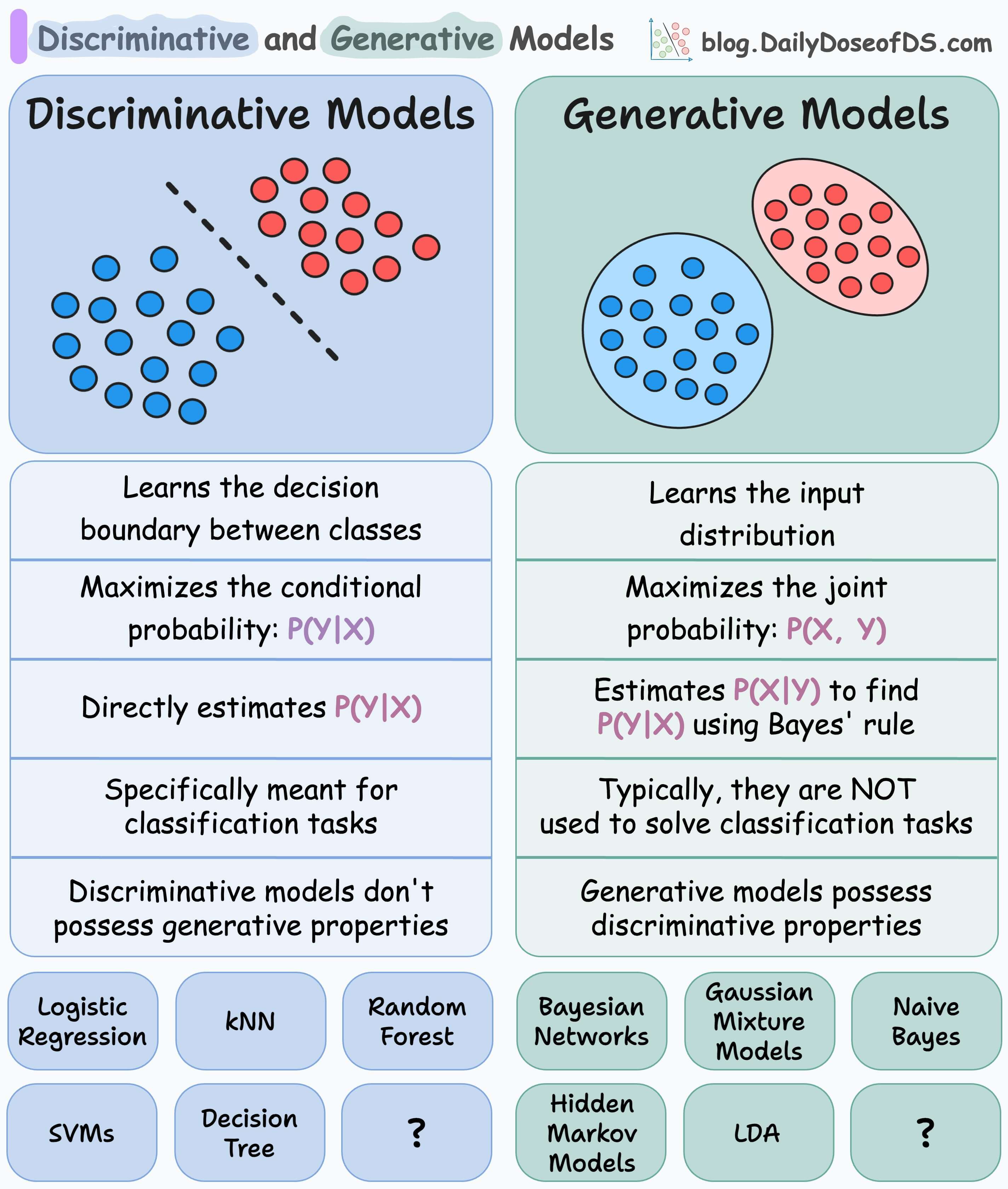
A Quick Recap
Discriminative models:

learn decision boundaries that separate differMaximizeses.
maximize the conditional probability:
P(Y|X)— Given an input X, maximize the probability of label Y.are meant explicitly for classification tasks.
Generative models:

maximize the joint probability:
P(X, Y)learn the class-conditional distribution
P(X|Y)are typically not meant for classification tasks, but they can perform classification nonetheless.
Categorization of discriminative models
In a gist, discriminative models directly learn the function f that maps an input vector (x) to a label (y).
They can be further divided into two categories:
Those that output probabilities.
Those that output direct label.
The following visual summarizes their differences:
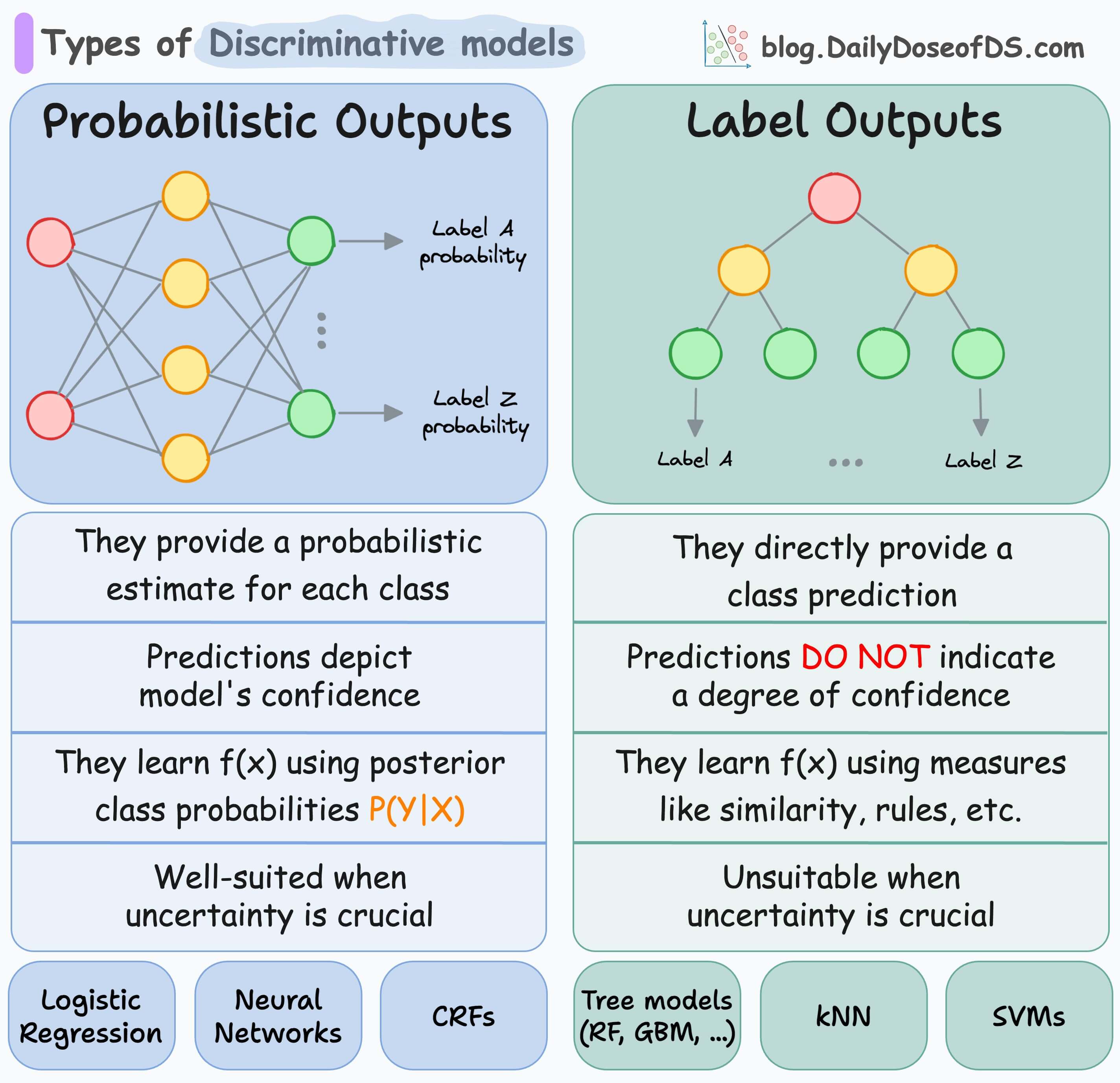
Probabilistic models

As the name suggests, probabilistic models provide a probabilistic estimate for each class.
They do this by learning the posterior class probabilities P(Y|X) — given an input X, what is the probability of a label Y.
As a result, their predictions depict the model’s confidence in predicting a specific class label.
This makes them well-suited in situations when uncertainty is crucial to the problem at hand.
Examples include:
Logistic regression
Neural networks
Conditional Random Fields (CRFs)
Of course, if you need true probabilistic outputs, things don’t stop at building a probabilistic model. We must ensure that the model is calibrated. We discussed this topic in detail below:
Labeling models

In contrast to probabilistic models, labeling models (also called distribution-free classifiers) directly predict the class label without providing any probabilistic estimate.
As a result, their predictions DO NOT indicate a degree of confidence. This makes them unsuitable when uncertainty in a model’s prediction is crucial.
Examples include:
Random forests
kNN
Decision trees
That being said, it is important to note that these models, in some way, can be manipulated to output a probability.
For instance, Sklearn’s decision tree classifier does provide a predict_proba() method, as shown below:

This may appear a bit counterintuitive at first.
However, in this case, the model outputs the class probabilities by looking at the fraction of training class labels in a leaf node.

In other words, say a test instance reaches a specific leaf node for final classification. The model will calculate the probabilities as the fraction of training class labels in that leaf node.

Yet, these manipulations do not account for the “true” uncertainty in a prediction.
This is because the uncertainty is the same for all predictions that land in the same leaf node.
Therefore, it is always wise to choose probabilistic classifiers (calibrated) when uncertainty is paramount, which you can learn below:
Talking of tree models, here are a couple of deep dives on ensembles:
In this deep dive, we discuss the mathematical foundation of Bagging and why it is so effective at variance reduction. Once you understand the mathematics, you will understand why we sample with replacement in Bagging.
In this deep dive, we formulate the entire XGBoost algorithm from scratch, covering the mathematical foundations, and then implement it in NumPy.
👉 Over to you: Can you add one more model for probabilistic and labeling models?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Crash Course on Graph Neural Networks (Implementation Included)
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 85,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.