
The Categorization of Clustering Algorithms in Machine Learning
6 types of clustering algorithms in a single frame.

Clustering is one of the core branches of unsupervised learning in ML.
The first (and sometimes the only) clustering algorithm folks learn is KMeans.
Yet, it is important to note that KMeans is not a universal solution to all clustering problems.
In fact, there’s a whole world of clustering algorithms beyond KMeans, which we must be familiar with.
The visual below summarizes 6 different types of clustering algorithms in machine learning:
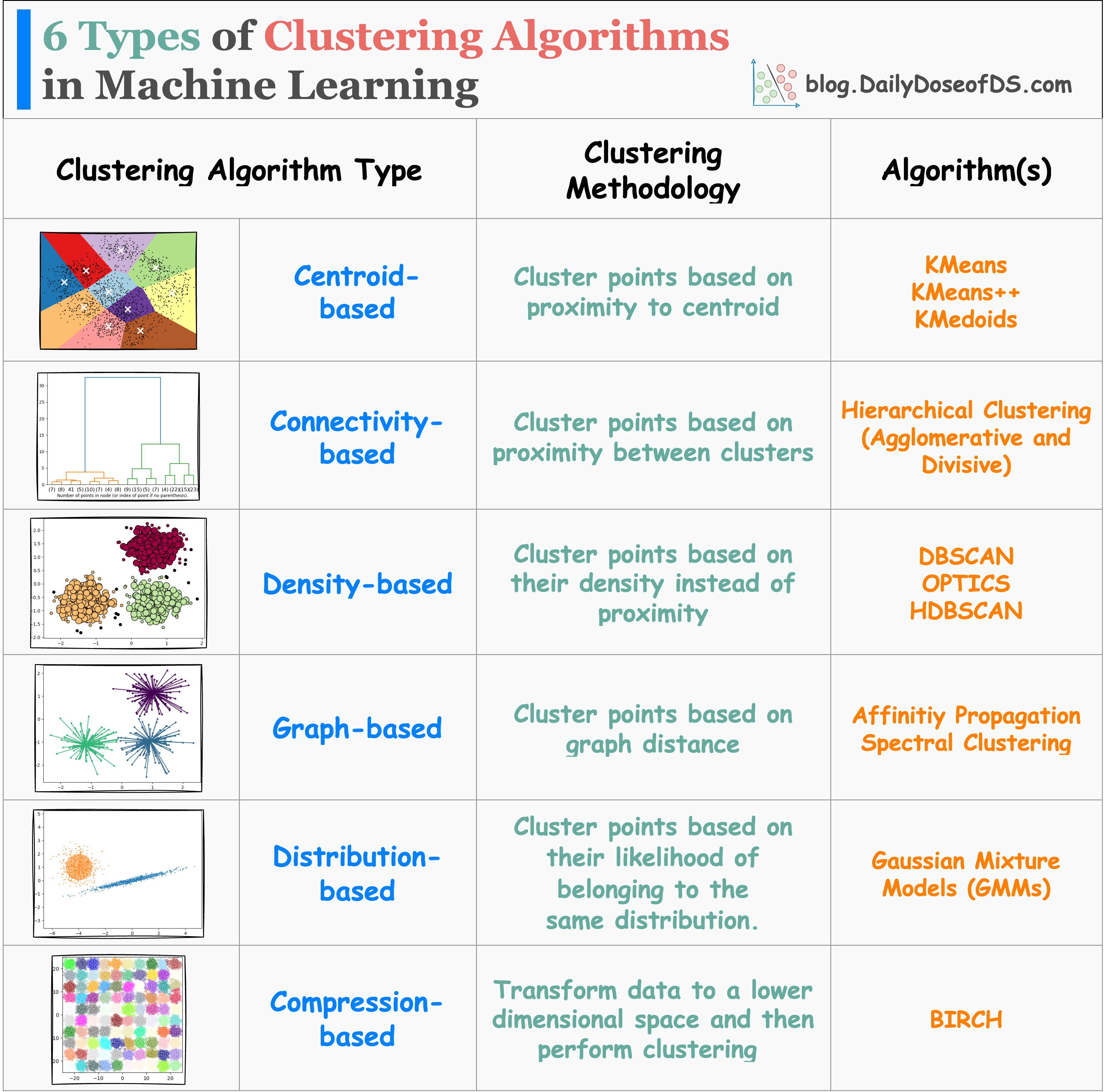
Centroid-based: Cluster data points based on proximity to centroids.
Connectivity-based: Cluster points based on proximity between clusters.
Density-based: Cluster points based on their density. It is more robust to clusters with varying densities and shapes than centroid-based clustering.
DBSCAN is a popular algorithm here, but it has high run-time. We covered DBSCAN++, which is a faster and more scalable alternative to DBSCAN: DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Graph-based: Cluster points based on graph distance.
Distribution-based: Cluster points based on their likelihood of belonging to the same distribution. Gaussian Mixture Model in one example. We discussed it in detail here: Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Compression-based: Transform data to a lower dimensional space and then perform clustering
Over to you: What other clustering algorithms will you include here?
Whenever you are ready, here’s one more way I can help you:
Every week, I publish 1-2 in-depth deep dives (typically 20+ mins long). Here are some of the latest ones that you will surely like:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
Snapchat Filters: Convolutional Neural Networks (allegedly)
Netflix Recommendation System: Restricted Boltzmann Machines
Google Translate (Machine Translation): Recurrent Neural Networks
Siri (Personal Assistants): Hidden Markov Models (2011-2014), Long Short Term Memory Networks (2014+), which is a type of Recurrent Neural Networks.
Self-driving cars (Image recognition, Video recognition): Convolutional Neural Networks (among other things)
Speech recognition, Hand-writing recognition: Recurrent Neural Networks
Market Segmentation: k-means clustering
Google AlphaGo: Convolutional Neural Networks
Image generation: Generative Adversarial Networks (GANs)