
The Evolution of Retrieval Layer
Naive RAG → Retrieval layer → Agentic Layer

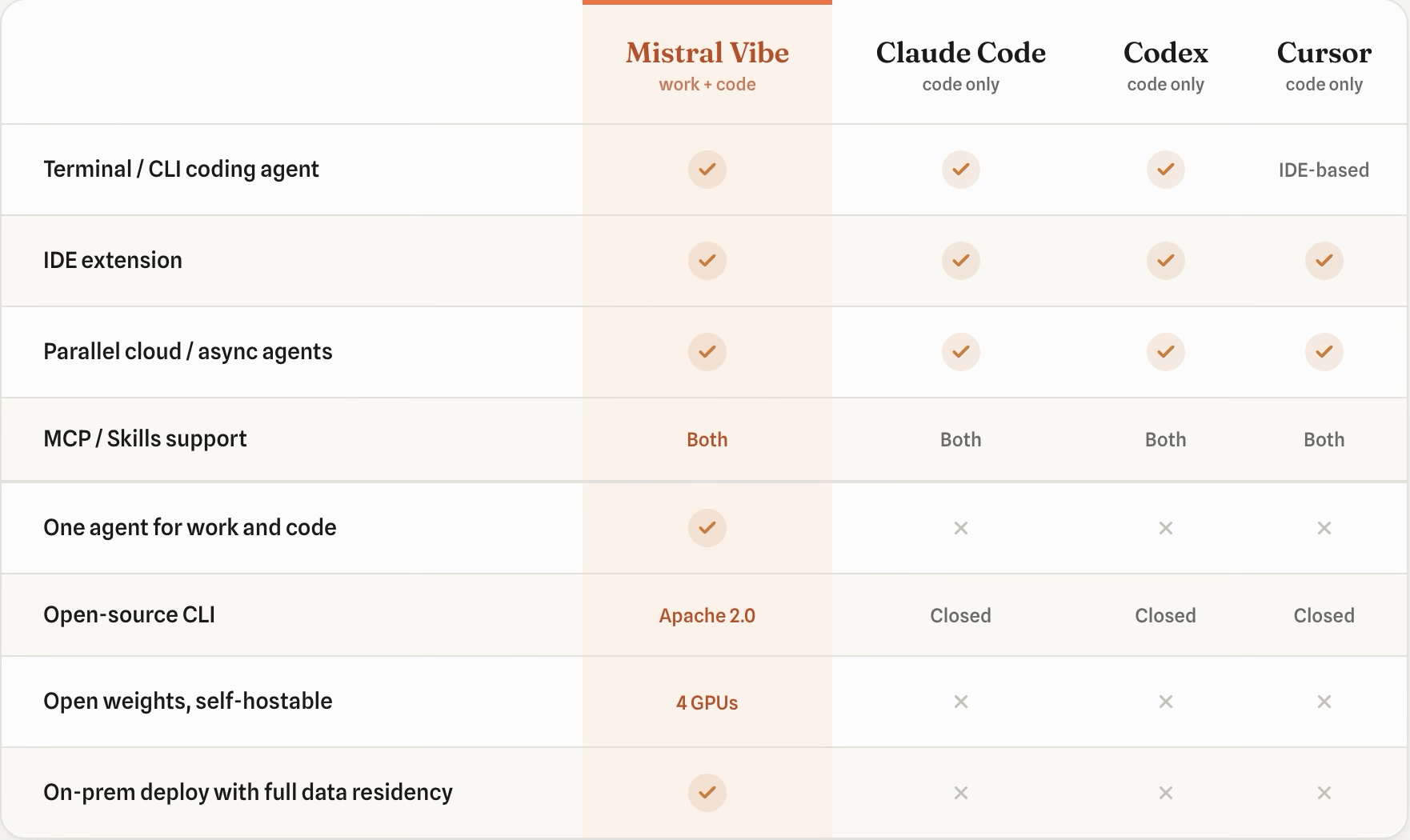
An open-weight agent that handles both work + code
AI tools typically split work and code into two products.
For instance:
Claude Code lives in a separate interface from Claude.
ChatGPT’s agent and Codex are different products.
On its own, that split looks harmless. But the cost shows up when a single task crosses the line, like a bug discussed in Slack that needs a code change.
Neither product carries the other's history, connectors, or task state, so you re-explain the same context twice, and each agent only ever sees half the work.
Mistral Vibe is taking an interesting approach by collapsing that into one agent with two modes.
Work Mode handles long-horizon tasks across your inbox, calendar, and docs. It maps a plan, gets your sign-off, then executes across connectors like Google Workspace, Slack, and SharePoint. You hand off routine multi-step work in a single prompt, and every step stays visible as it runs.
Code Mode takes a request from a prompt to a merged pull request. Sessions run in isolated sandboxes, in parallel, and end with a reviewable PR on GitHub.
The CLI is open-source under Apache 2.0, so you can fork it, swap models, or wire it into your own pipeline.
The model ships with open weights and self-hosts on as few as four GPUs, which means code never has to leave your infrastructure.
There’s also /teleport. Start a refactor in your terminal, hit /teleport, and the session moves to a cloud sandbox with its history, task state, and approvals intact. Close your laptop, let it keep running, and reattach later from any device.
Get started with Mistral Vibe here →
Find the CLI GitHub repo here → (don’t forget to star 🌟)
The evolution of retrieval
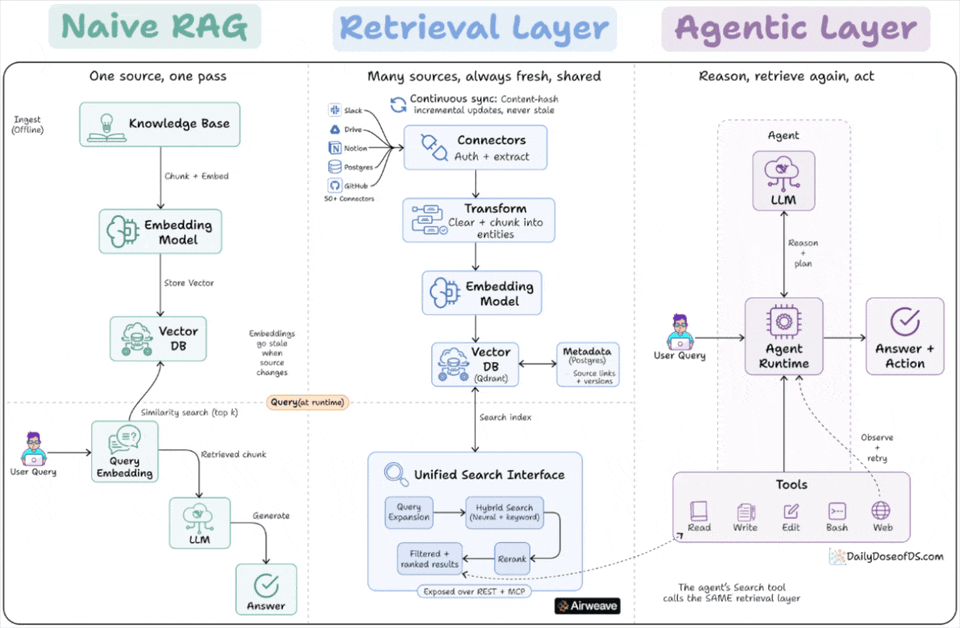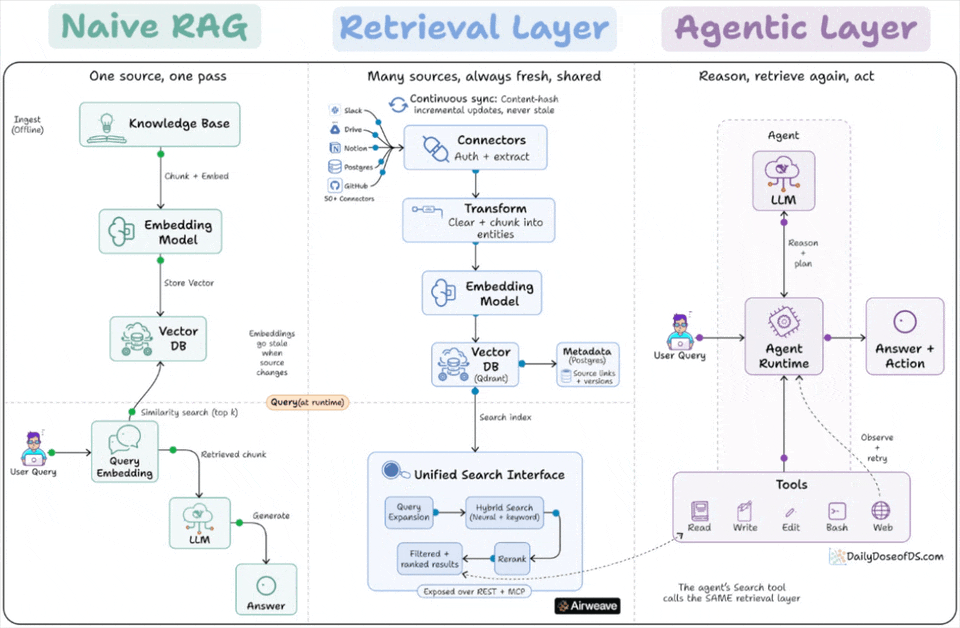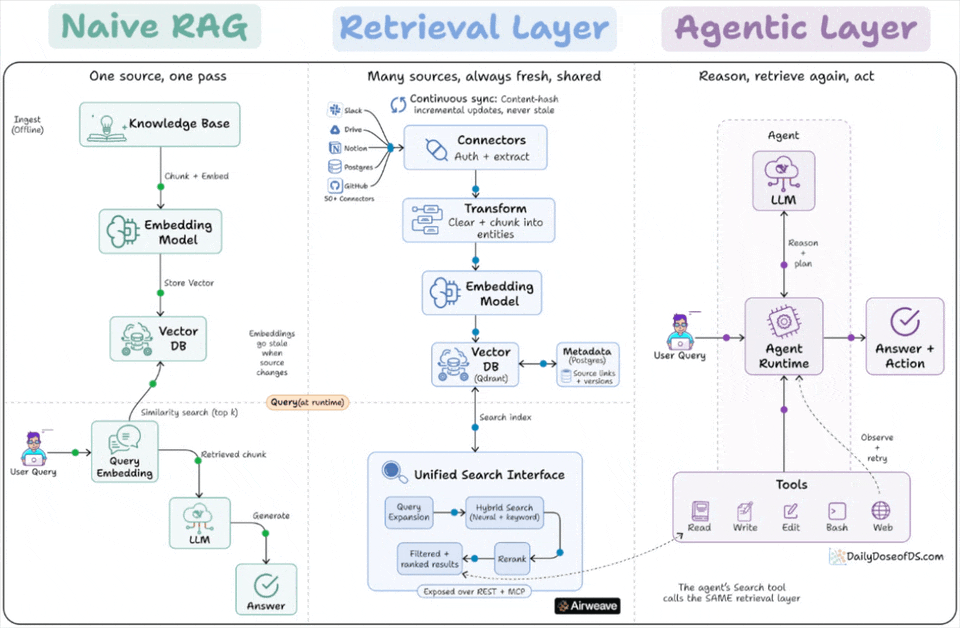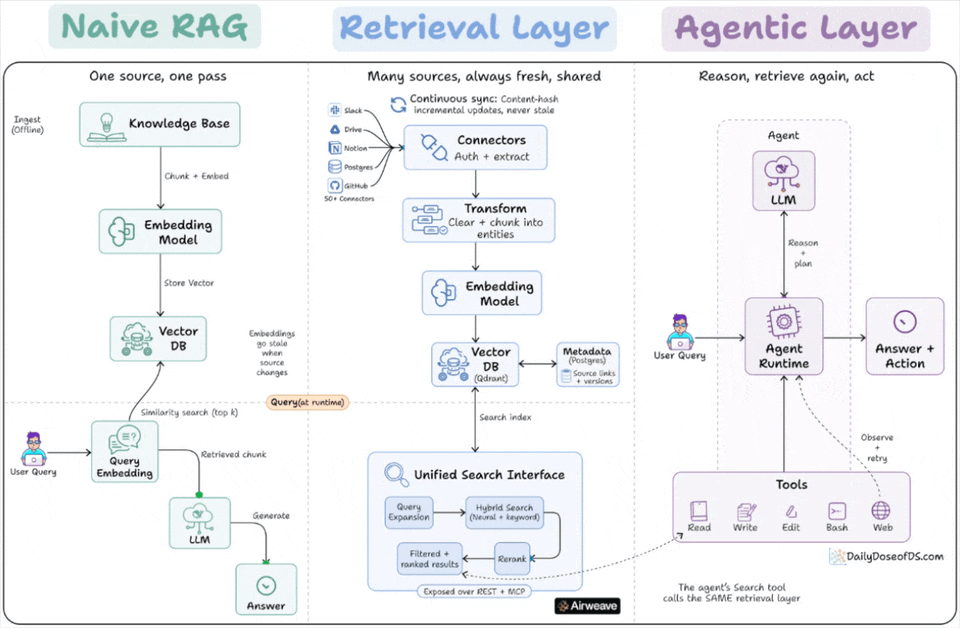
Google and Anthropic agree on one thing about RAG that retrieval is no longer a pipeline you build once.
Instead, it is a tool that something else calls.
Anthropic’s MCP exposes retrieval as a tool an agent can call.
Google now ships retrieval the same way, with its RAG Engine sitting under the Gemini agent platform alongside MCP servers.
That shift sounds small, but it changes the entire architecture underneath.
Today, let’s break down why classical RAG isn’t ideal in production, what a standing retrieval layer looks like, and how agents consume it.
Classical/Naive RAG
Naive RAG runs as a one-time pipeline inside a single app. A knowledge base gets chunked, embedded, and written to a vector DB.
At query time, the user’s query hits that vector DB for a similarity search, and the retrieved chunks go to the LLM.
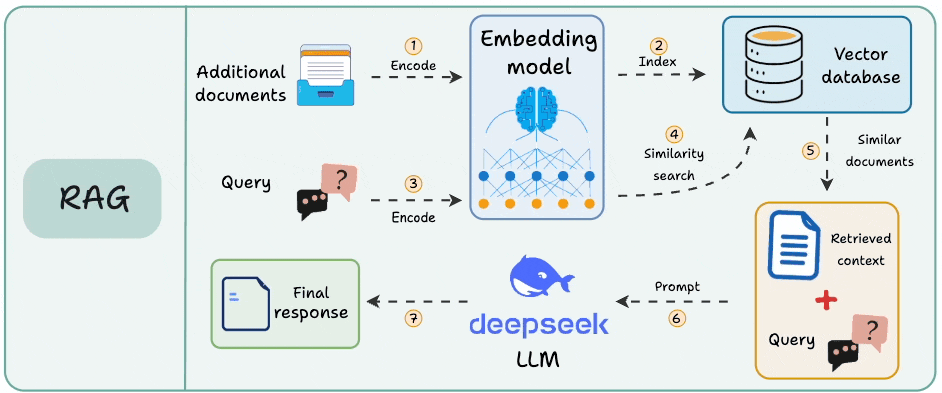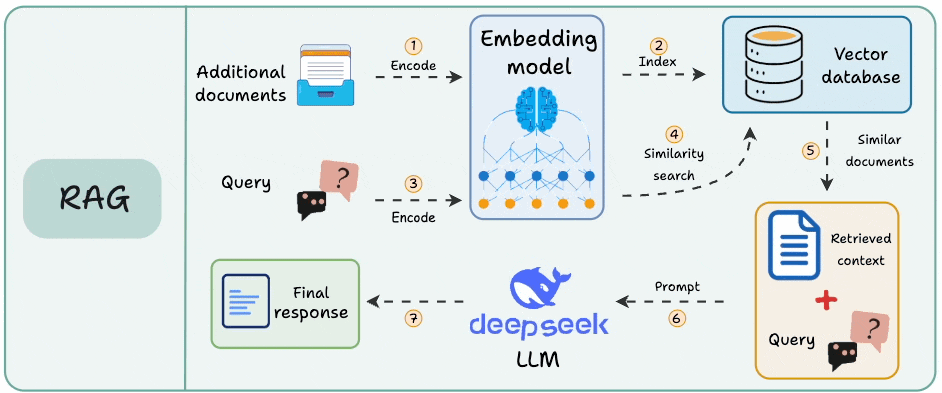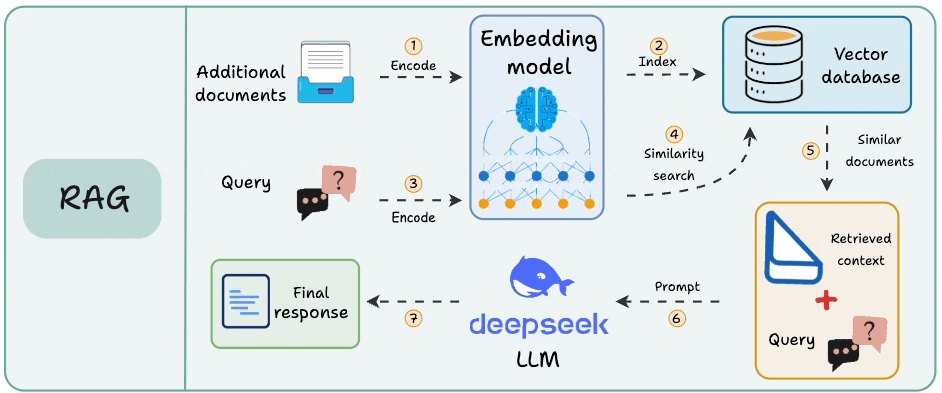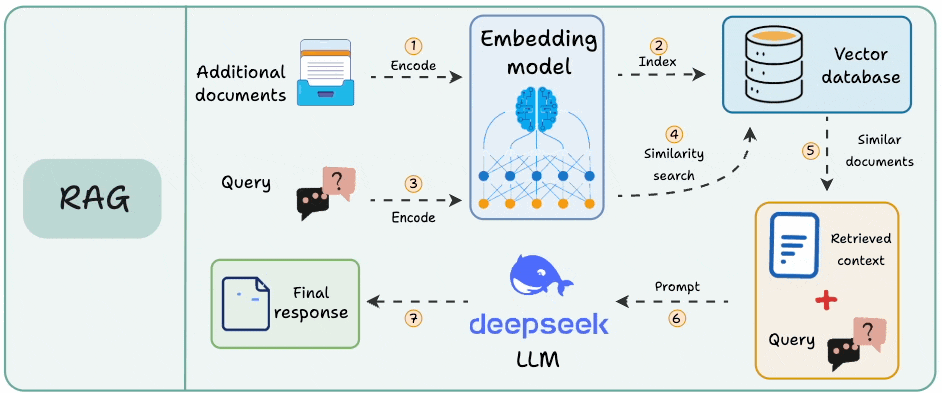
This works when the answer lives in one corpus that rarely changes. It breaks on two fronts that show up immediately at scale.
The first is staleness. The embeddings reflect the source at the moment of indexing. When a doc changes in Notion or a row updates in Postgres, the vectors still point at the old content until someone reruns the pipeline.
The second is duplication. The retrieval logic is welded to one application. A second app, or an agent, that needs the same data has to rebuild the same connectors, chunking, and embedding from scratch.
Retrieval as a standing layer
The fix is to stop treating retrieval as a step inside the app and start treating it as a standing layer underneath it. A retrieval layer separates ingestion from query, and runs ingestion continuously instead of once.
On the ingest side, connectors pull from many sources, handle auth and extraction, chunk into entities, embed, and write to a vector store with a metadata store alongside it for source links and versions.
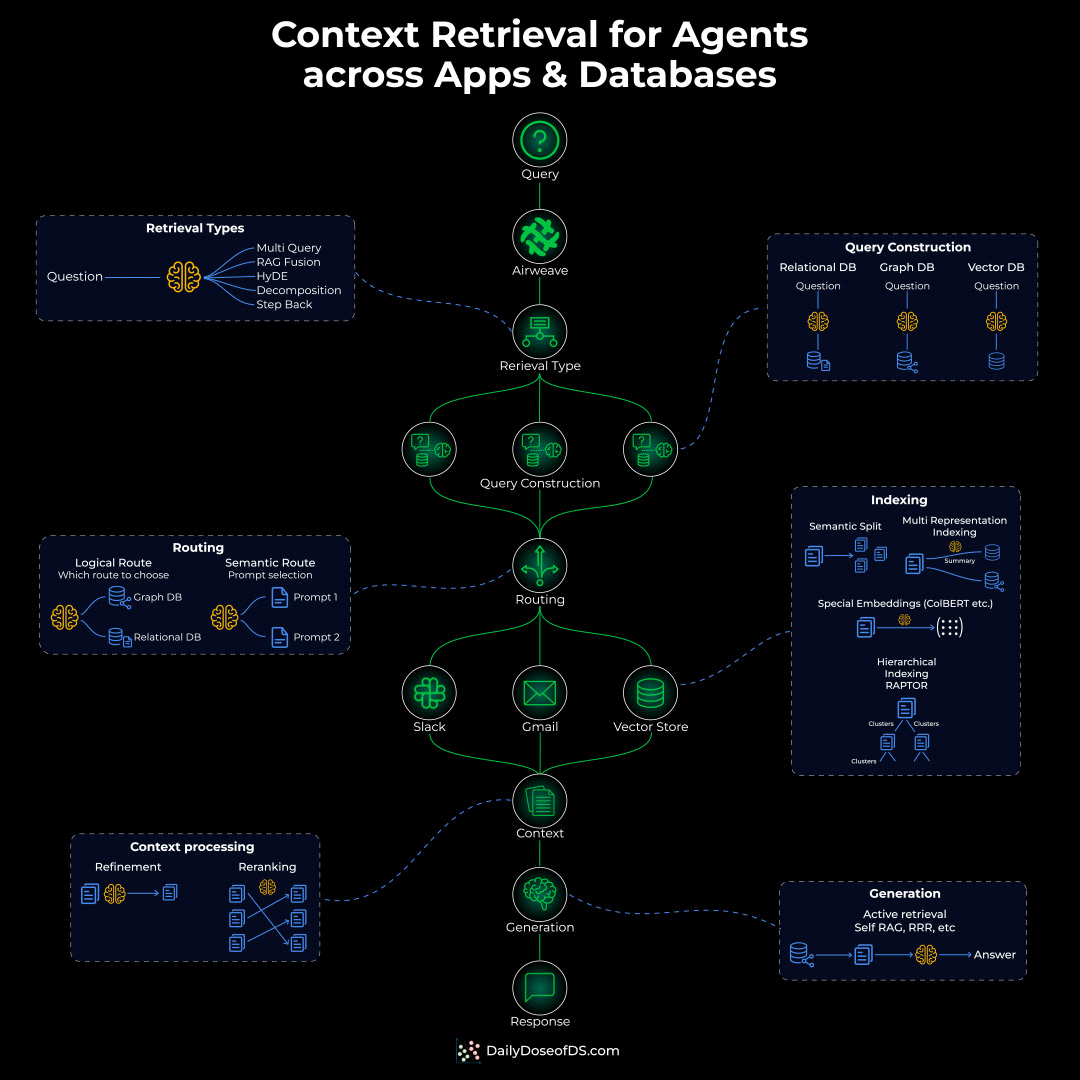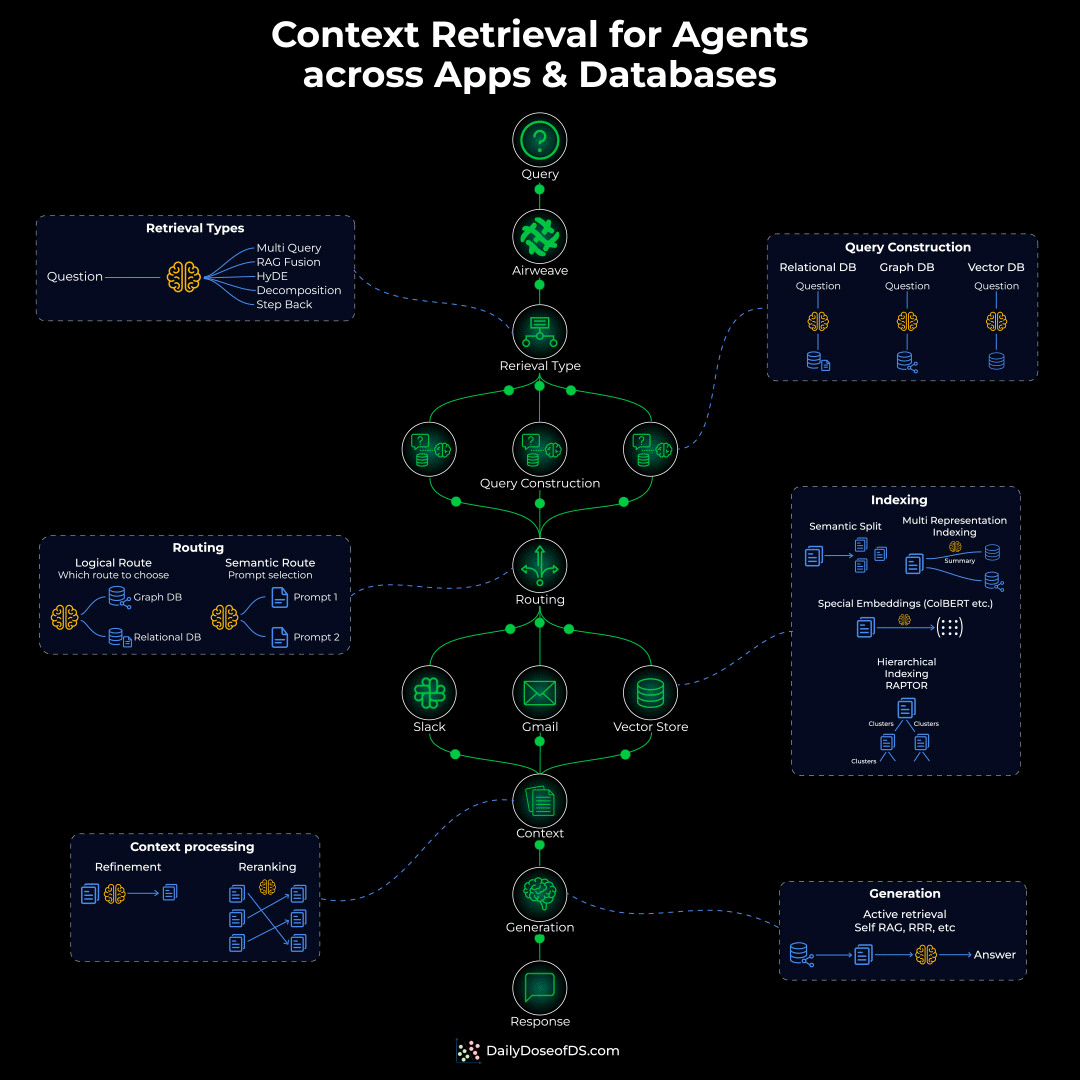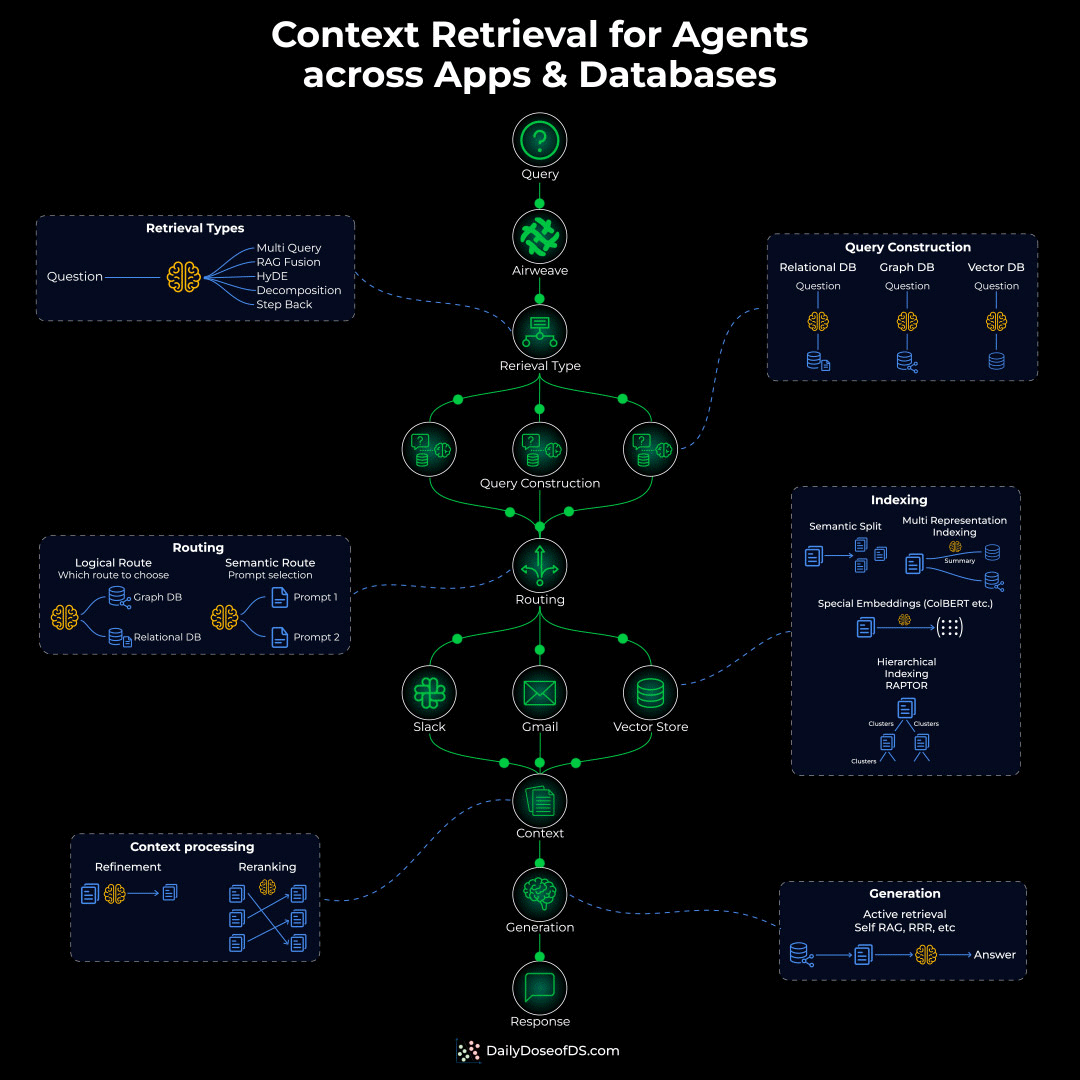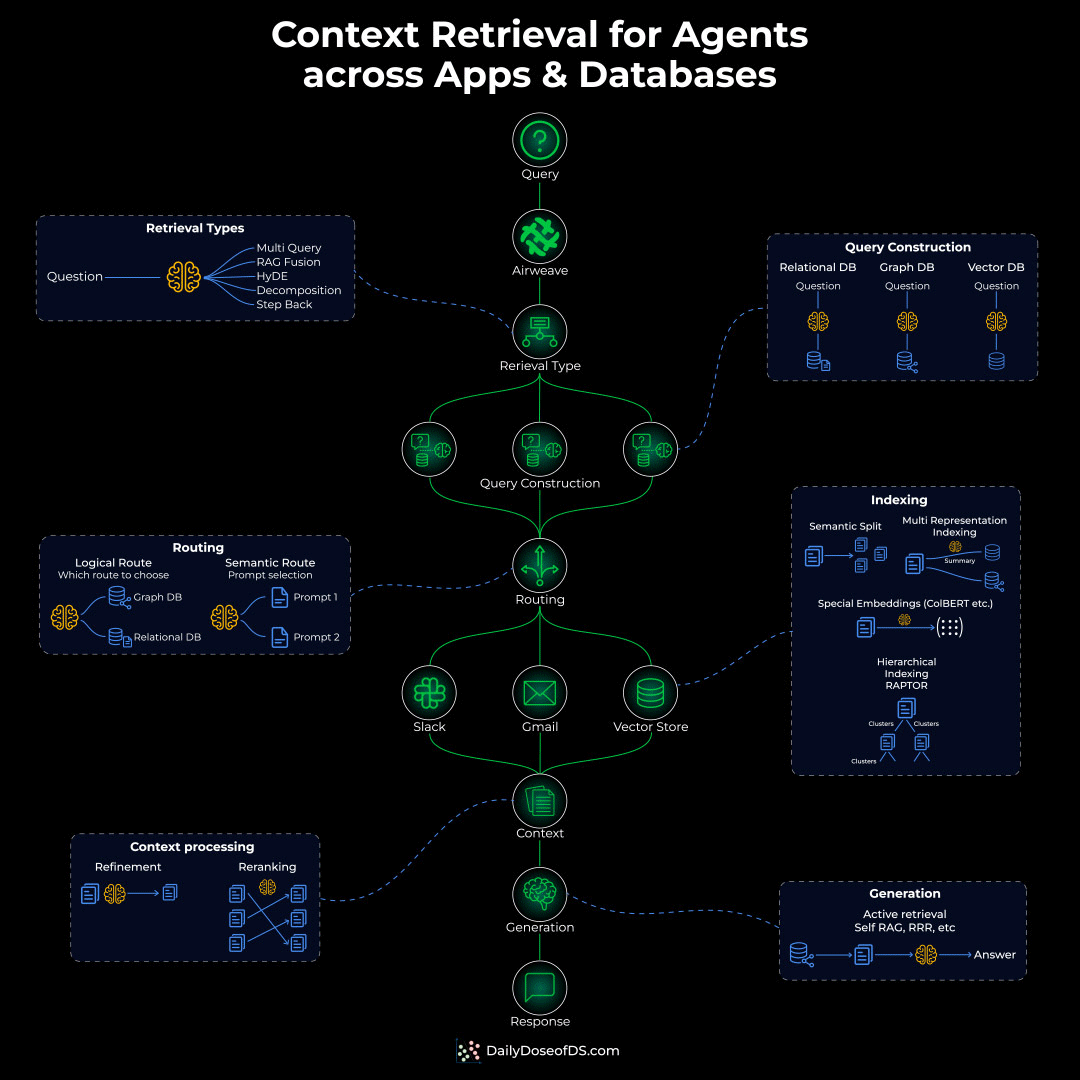
A sync process watches for changes and updates only what changed, using content hashing so unchanged data is not re-embedded.
On the query side, a request gets expanded, run through hybrid search that combines neural and keyword retrieval, then reranked before results come back with their source attribution.
The key property is that this layer is owned by no single app. It is exposed over an API, so a RAG chatbot and an autonomous agent can both query the same index.
How agents change the picture
An agent does not run retrieval once at the start.
It reasons, decides it needs context, calls search, reads the result, and decides whether to search again with a refined query. Retrieval becomes a tool inside a loop, not a fixed first step.
And the tool the agent calls is the retrieval layer.
The agent’s search function and the RAG app’s retrieval are the same query path into the same synced store.
They were never separate systems. Instead, one was just drawn inside the app and the other was pulled out and shared.
If you want to see this whole layer in practice, Airweave is an open-source implementation of it.
It connects to 50+ sources, continuously syncs them with content-hash incremental updates so the index stays current, and exposes everything through one search endpoint over both REST and MCP. The MCP endpoint is what lets an agent treat the whole layer as a single search tool.
👉 Over to you: Is moving retrieval out of the app and into a shared layer the right call for your stack?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.