
The Full MCP Blueprint
Background, foundations, architecture, and usage.

After the RAG and AI Agents crash course, we have started an MCP crash course. Read the first two parts here:
Just like our past series, this series is both foundational and implementation-heavy, walking you through everything step-by-step.
In Part 1, we introduce:
Why context management matters in LLMs.
The limitations of prompting, chaining, and function calling.
The M×N problem in tool integrations..
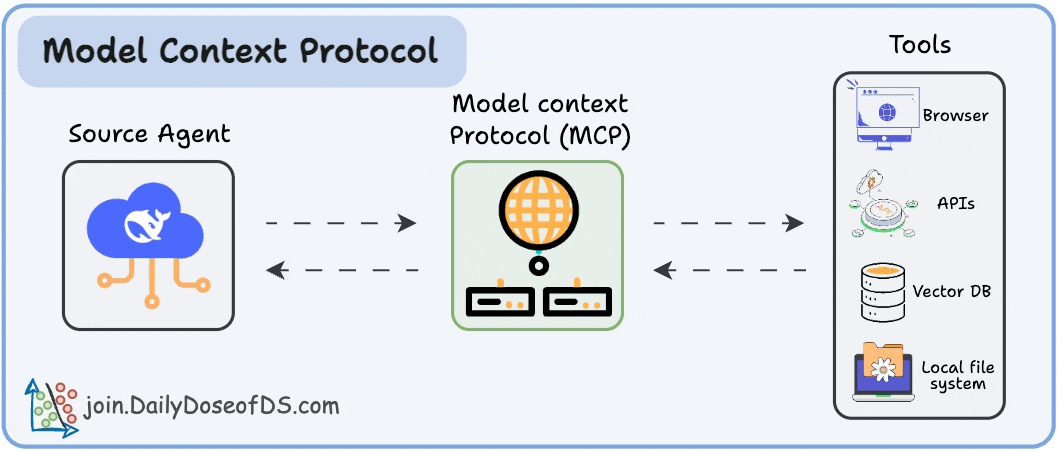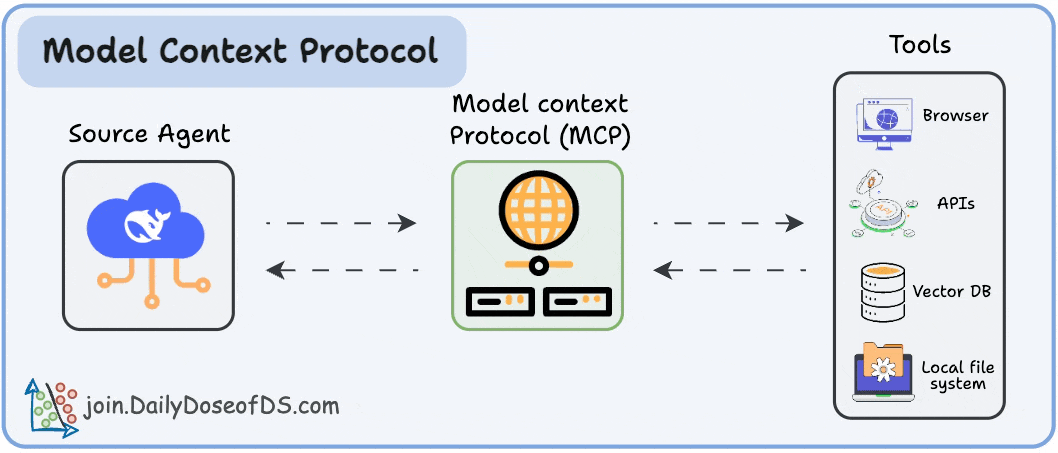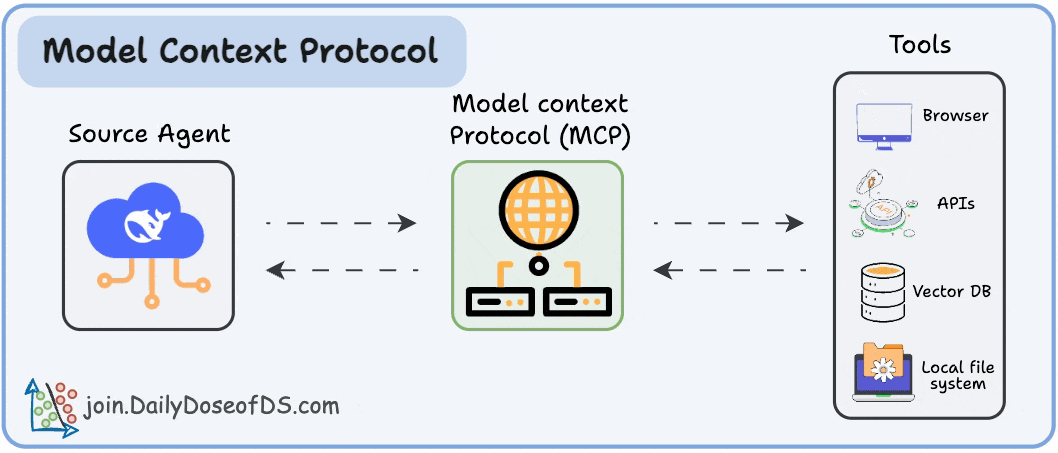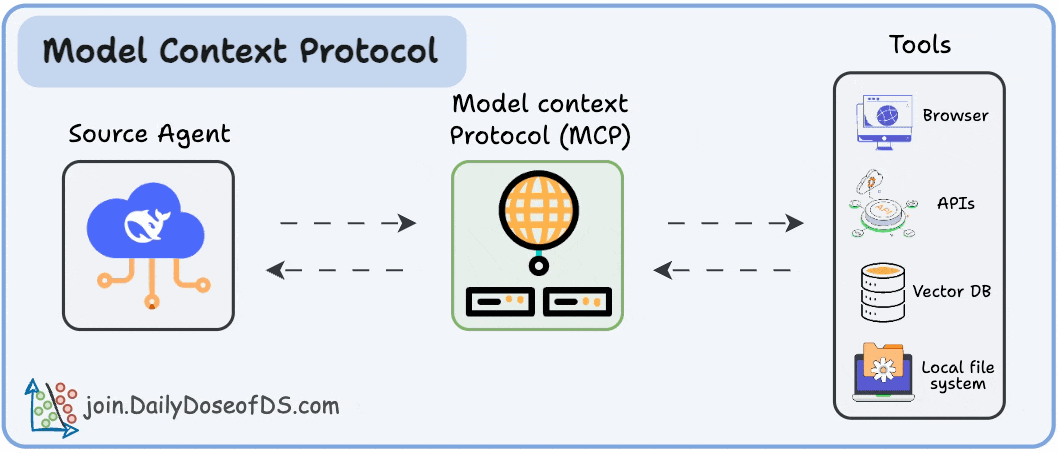
And how MCP solves it through a structured Host–Client–Server model.
In Part 2, we go hands-on and cover:
The core capabilities in MCP (Tools, Resources, Prompts).
How JSON-RPC powers communication.
Transport mechanisms (Stdio, HTTP + SSE).
A complete, working MCP server with Claude and Cursor.
Comparison between function calling and MCPs.
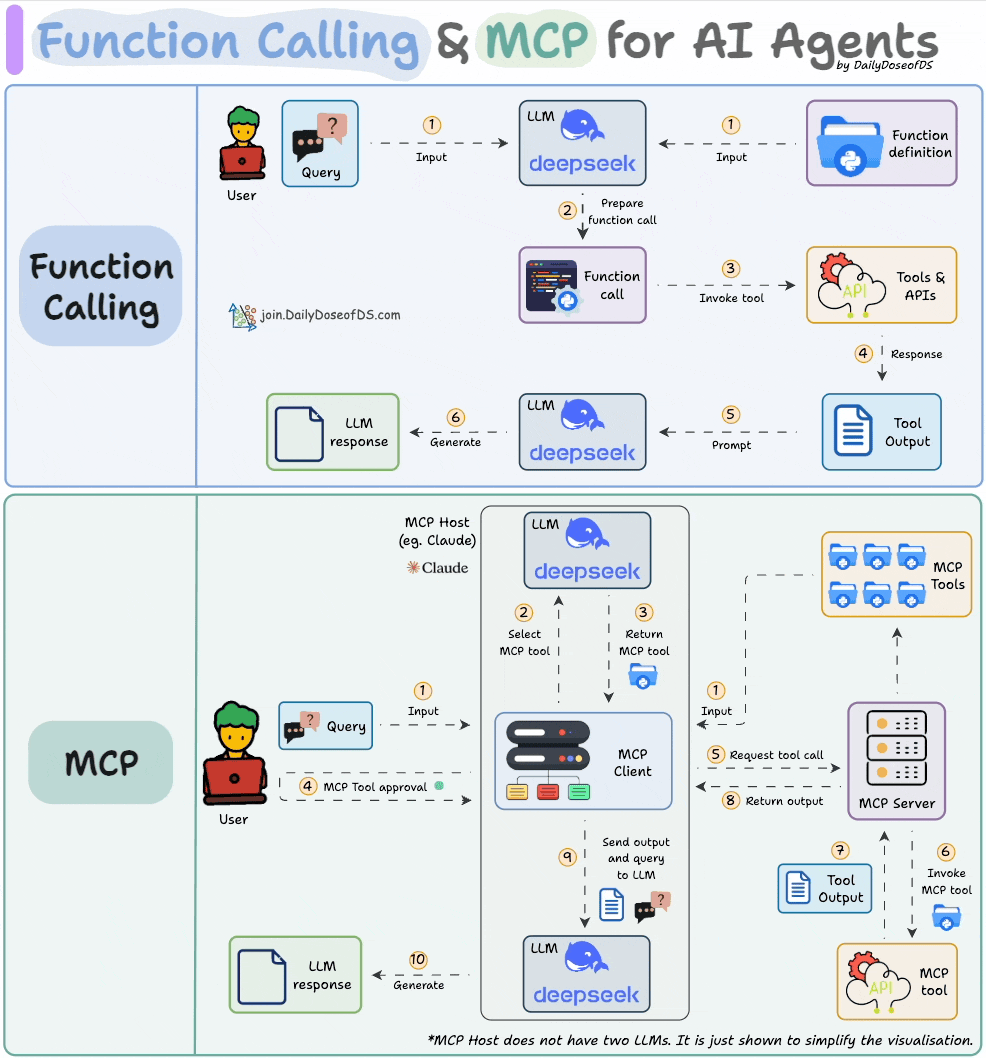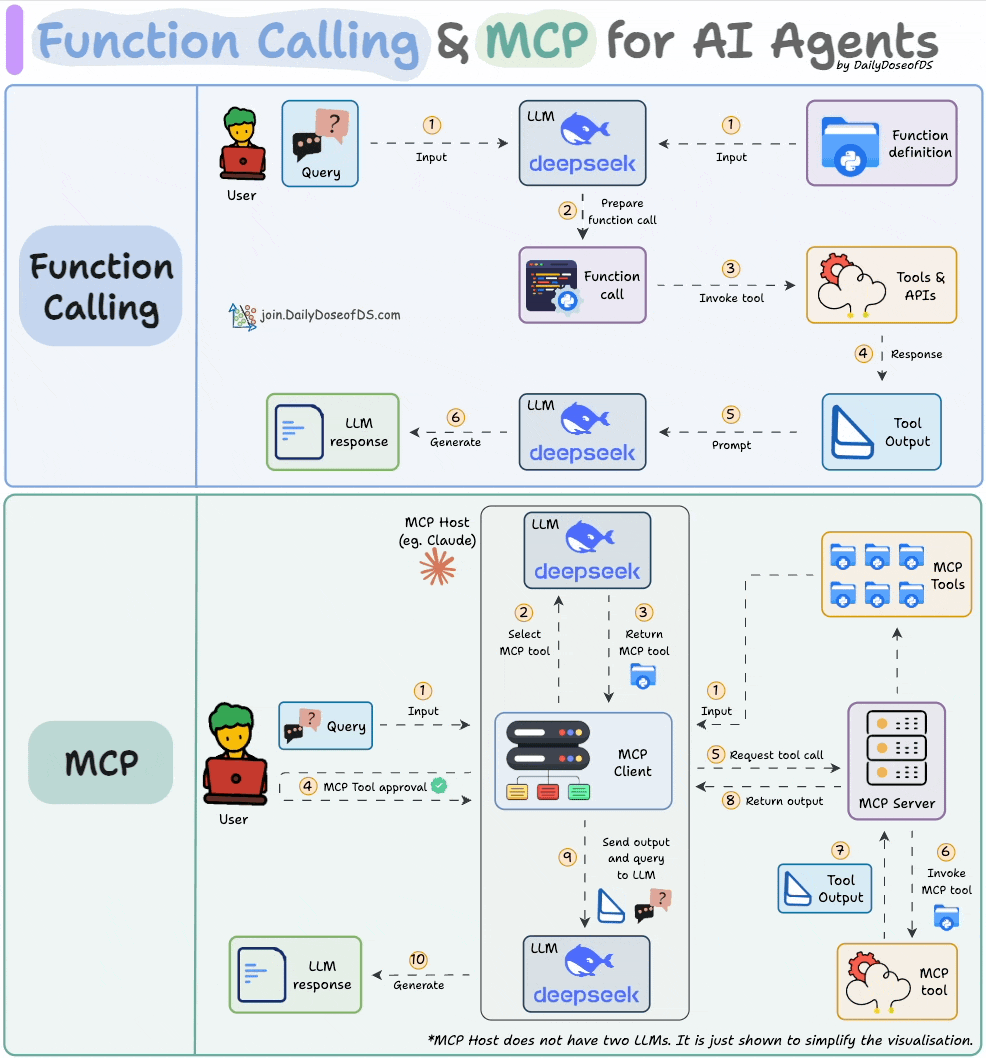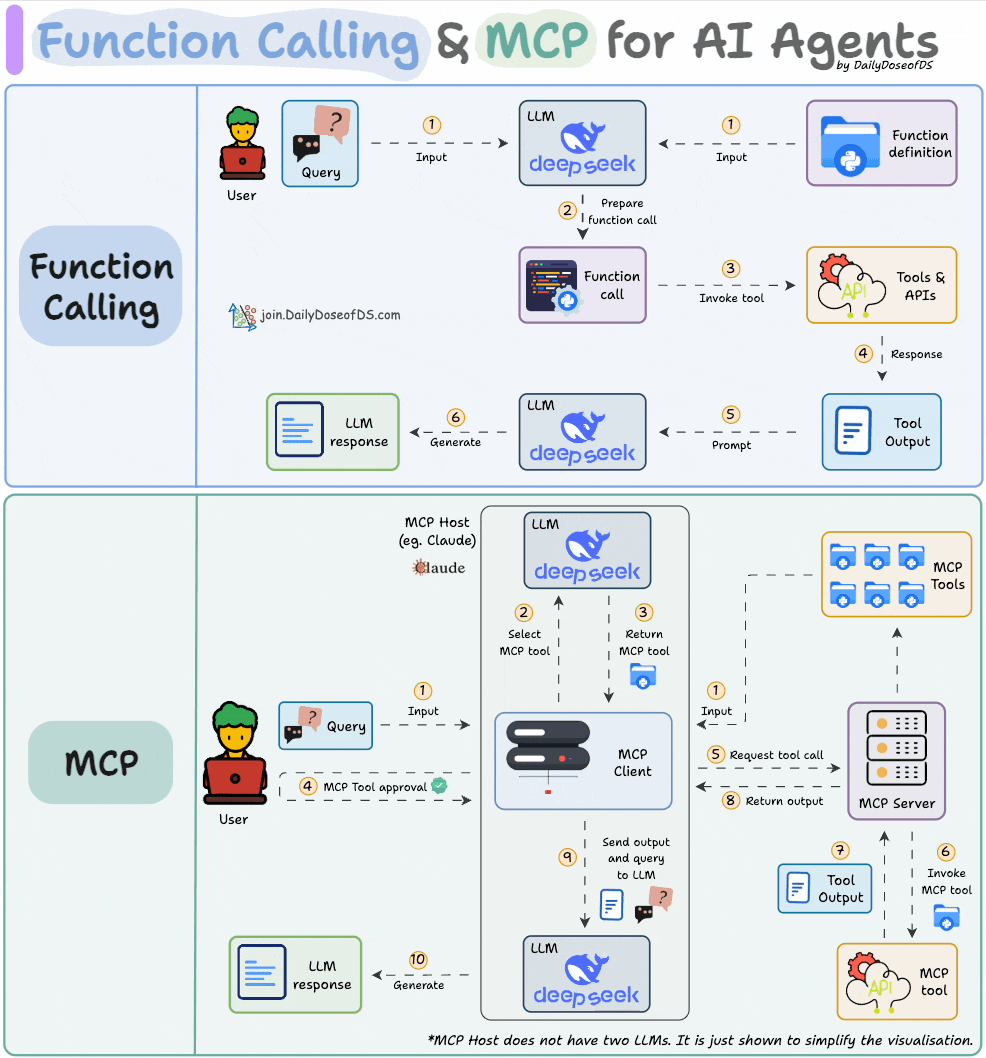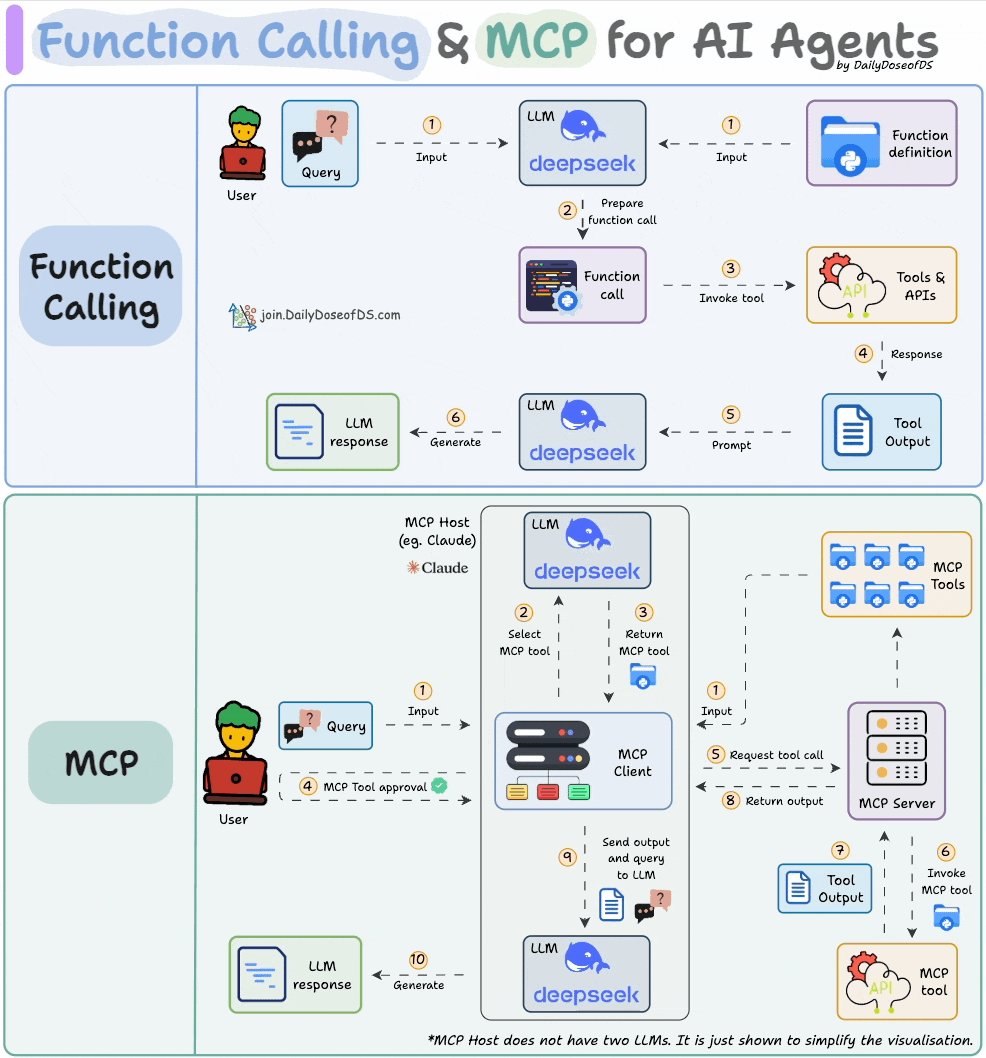
Why care?
Most LLM workflows today rely on hardcoded tool integrations. But these setups don’t scale, they don’t adapt, and they severely limit what your AI system can actually do.
MCP solves this.
Think of it as the missing layer between LLMs and tools, a standard way for any model to interact with any capability: APIs, data sources, memory stores, custom functions, and even other agents.
Without MCP:
You’re stuck gluing every tool manually to every model.
Context sharing is messy and brittle.
Scaling beyond prototypes is painful.
With MCP:
Models can dynamically discover and invoke tools at runtime.
You get plug-and-play interoperability between systems like Claude, Cursor, LlamaIndex, CrewAI, and beyond.
You move from prompt engineering to systems engineering, where LLMs become orchestrators in modular, reusable, and extensible pipelines.
This protocol is already powering real-world agentic systems.
And in this crash course, you’ll learn exactly how to implement and extend it, from first principles to production use.
Read the first two parts here:
Thanks for reading!