
The Full MLOps/LLMOps Blueprint
...covered with foundations, projects, and real-world insights.

Part 3 of the MLOps and LLMOps crash course is now available, which extensively focuses on reproducibility and versioning for ML systems, with hands-on implementations.
Read here: MLOps and LLMOps crash course Part 3 →
We cover:
Why reproducibility matters and challenges.
9 industry best practices for reproducibility and versioning.
PyTorch model training loop and model persistence.
Git + DVC for version control.
Training and tracking experiments with MLflow.
Just like all our past series on MCP, RAG, and AI Agents, this series is both foundational and implementation-heavy, walking you through everything that a real-world ML system entails:
In Part 1, we covered the foundations:
Why does MLOps matter?
MLOps vs. DevOps and traditional software systems
System-level concerns in production ML
The ML system lifecycle.
In Part 2, we went hands-on and covered:
The entire ML system lifecycle.
Data pipelines
Model training and experimentation
Model deployment and inference
Model deployment and inference
Hands-on project from training to API
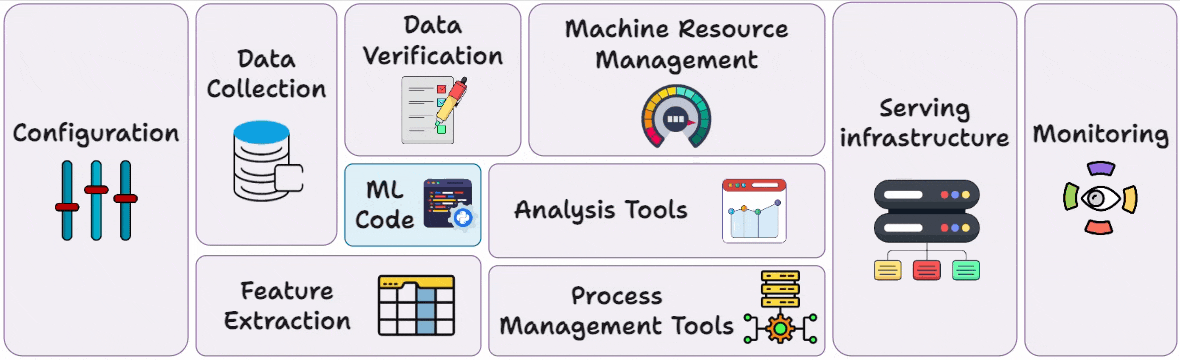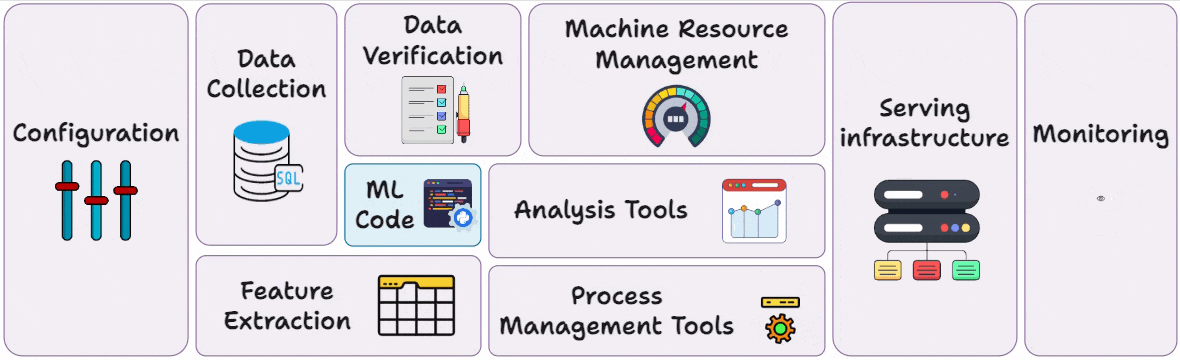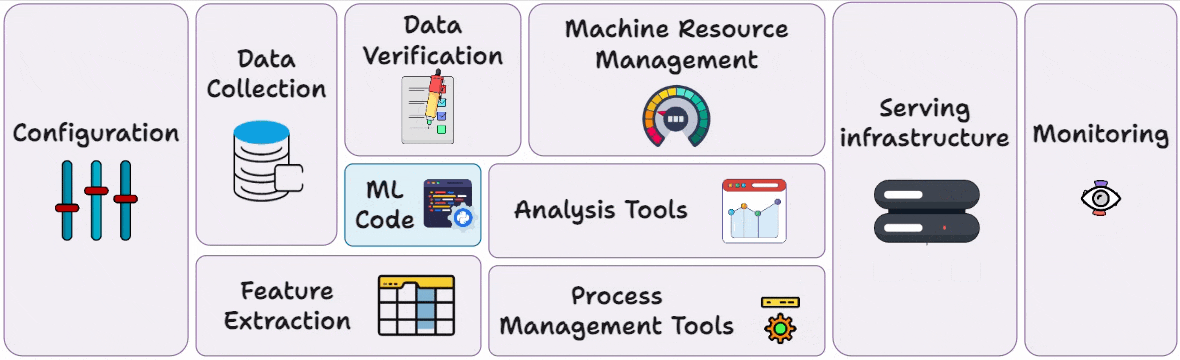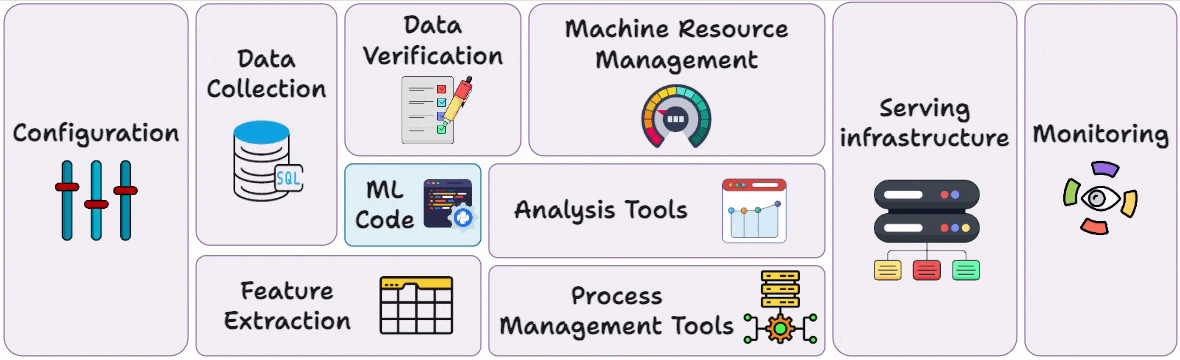
Only a tiny fraction of an “ML system” is the ML code; the vast surrounding infrastructure (for data, configuration, automation, serving, monitoring, etc.) is much larger and more complex:
We are creating this MLOps and LLMOps crash course to provide a thorough explanation and systems-level thinking to build AI models for production settings.
Just as the MCP crash course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
Thanks for reading!