
The Ideal Loss Function for Class Imbalance
...a popular ML interview question.

Stagehand Agent can now use MCP tools
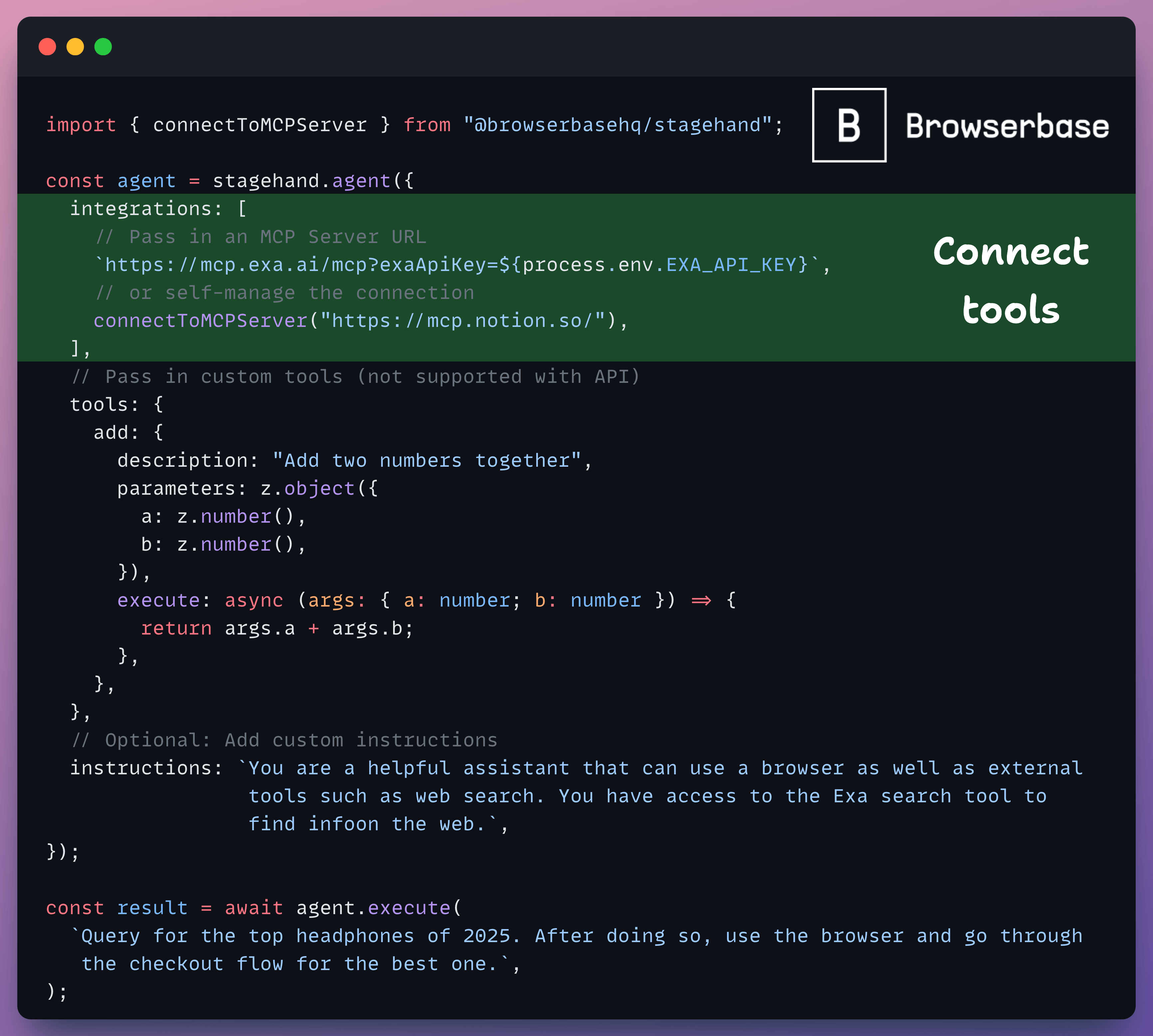
Your AI agents can now call external tools and integrate with any third-party service with Stagehand.
Stagehand's latest update allows your agents to connect to MCP servers, unlocking web search, authentication, Google Workspace, database operations, and custom tools.
This isn't just clicking buttons, it's building AI workflows that reason, remember, and execute complex tasks across your entire tech stack.
Try Stagehand by Browserbase →
Thanks to Browserbase, the leading browser infrastructure for AI, for partnering today!
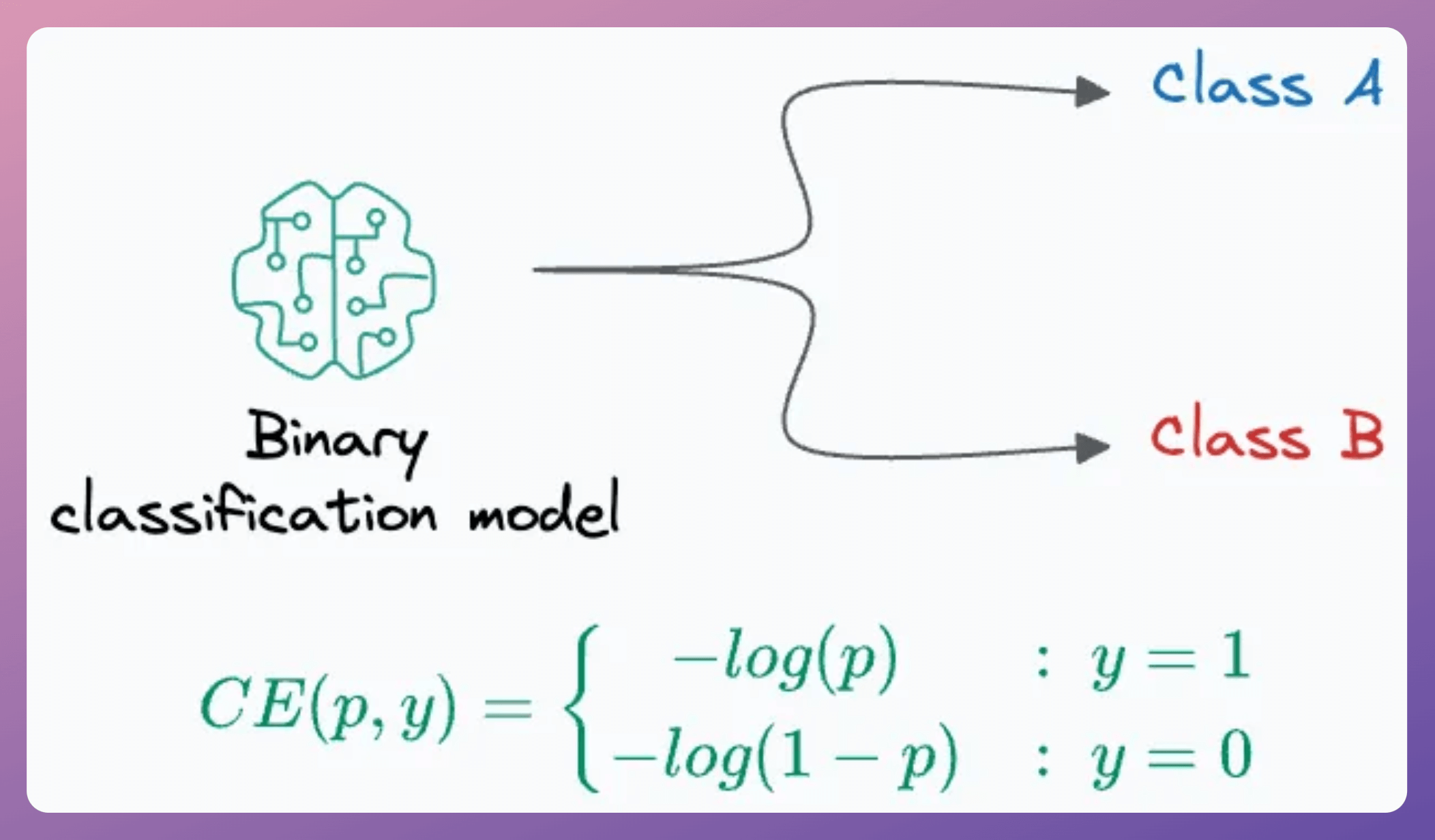
The ideal loss function to handle class imbalance
Binary classification tasks are typically trained using the binary cross-entropy (BCE) loss function:
For notational convenience, if we define pₜ as the following:
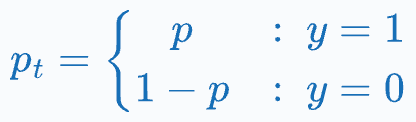
…then we can also write the cross-entropy loss function as:

But one limitation of BCE loss is that it weighs probability predictions for both classes equally:
This means two instances, one from the minority class and another from the majority class, get assigned the same loss value if the probabilities are equal:
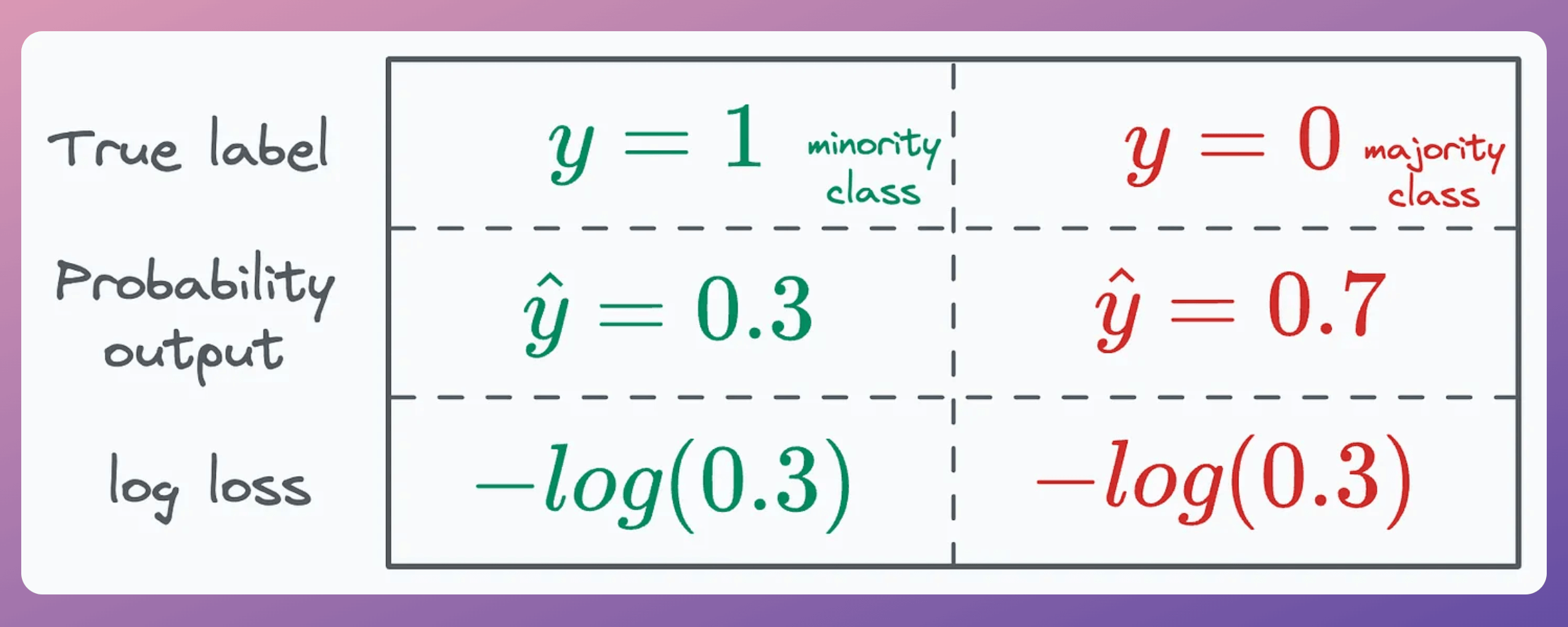
This causes problems in imbalanced datasets, where most instances are easily classifiable.
Ideally, a loss value of -log(0.3) from the minority class should be weighed higher than the same loss value from the minority class.

Focal loss addresses this issue:
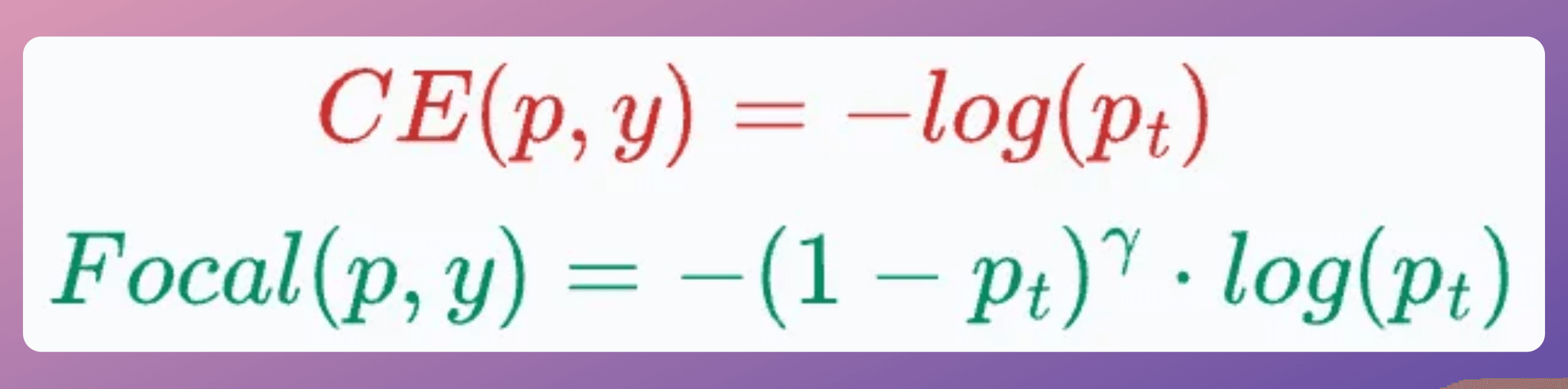
It introduces an additional multiplicative factor called downweighing, and the parameter γ (Gamma) is a hyperparameter.
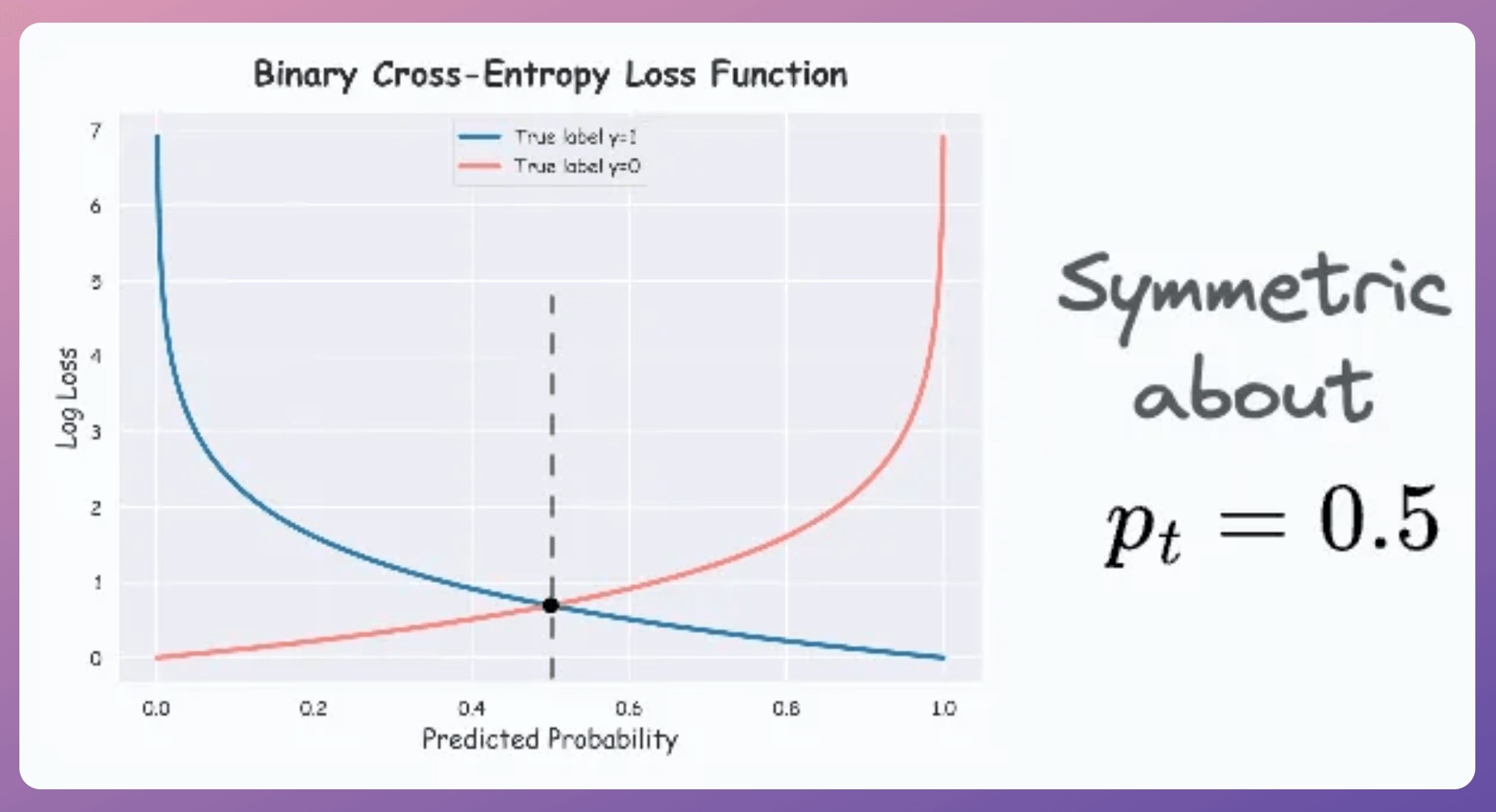
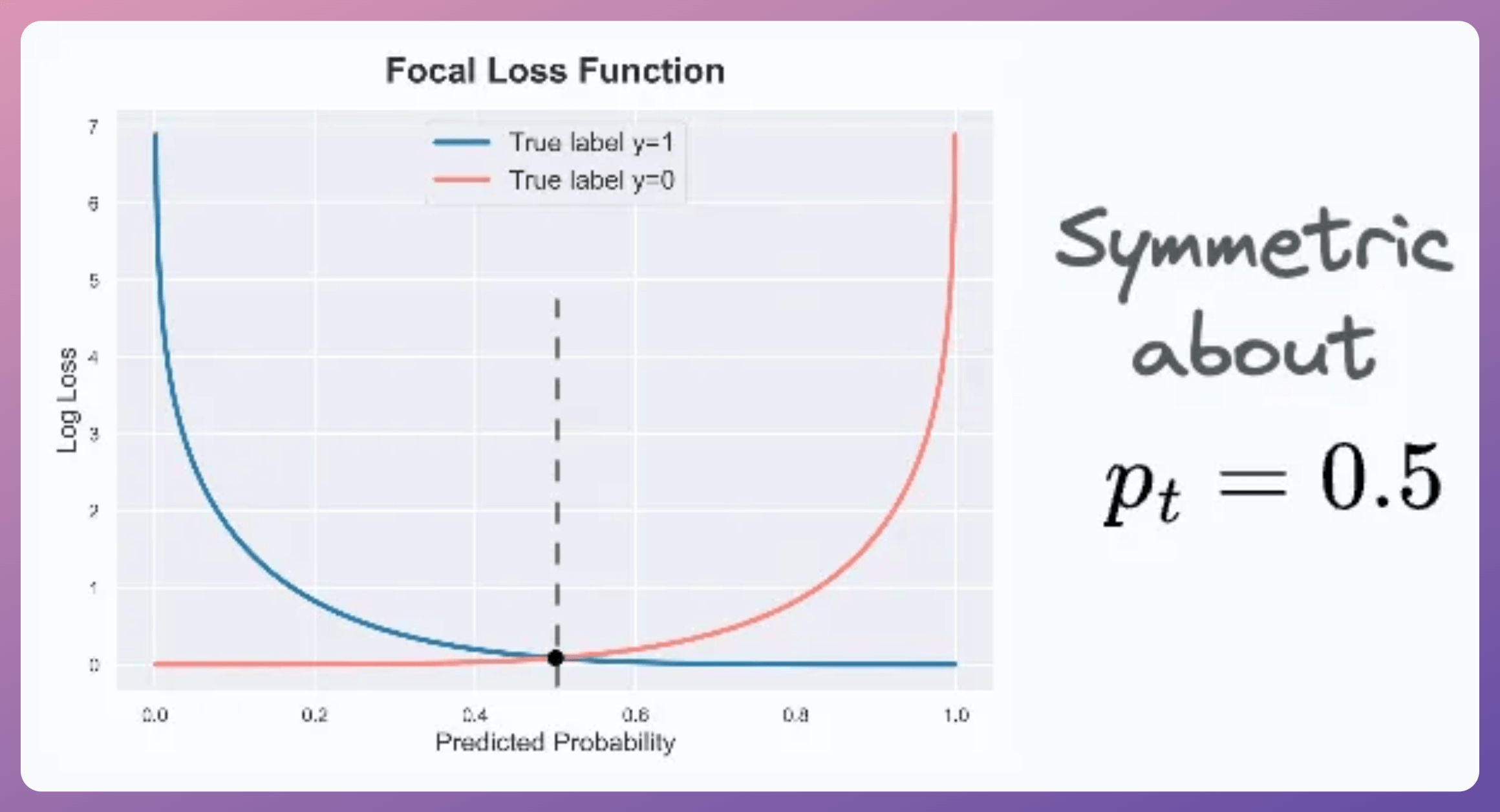
Plotting BCE (class y=1) and Focal loss (for class y=1 and γ=3), we get the following curve:
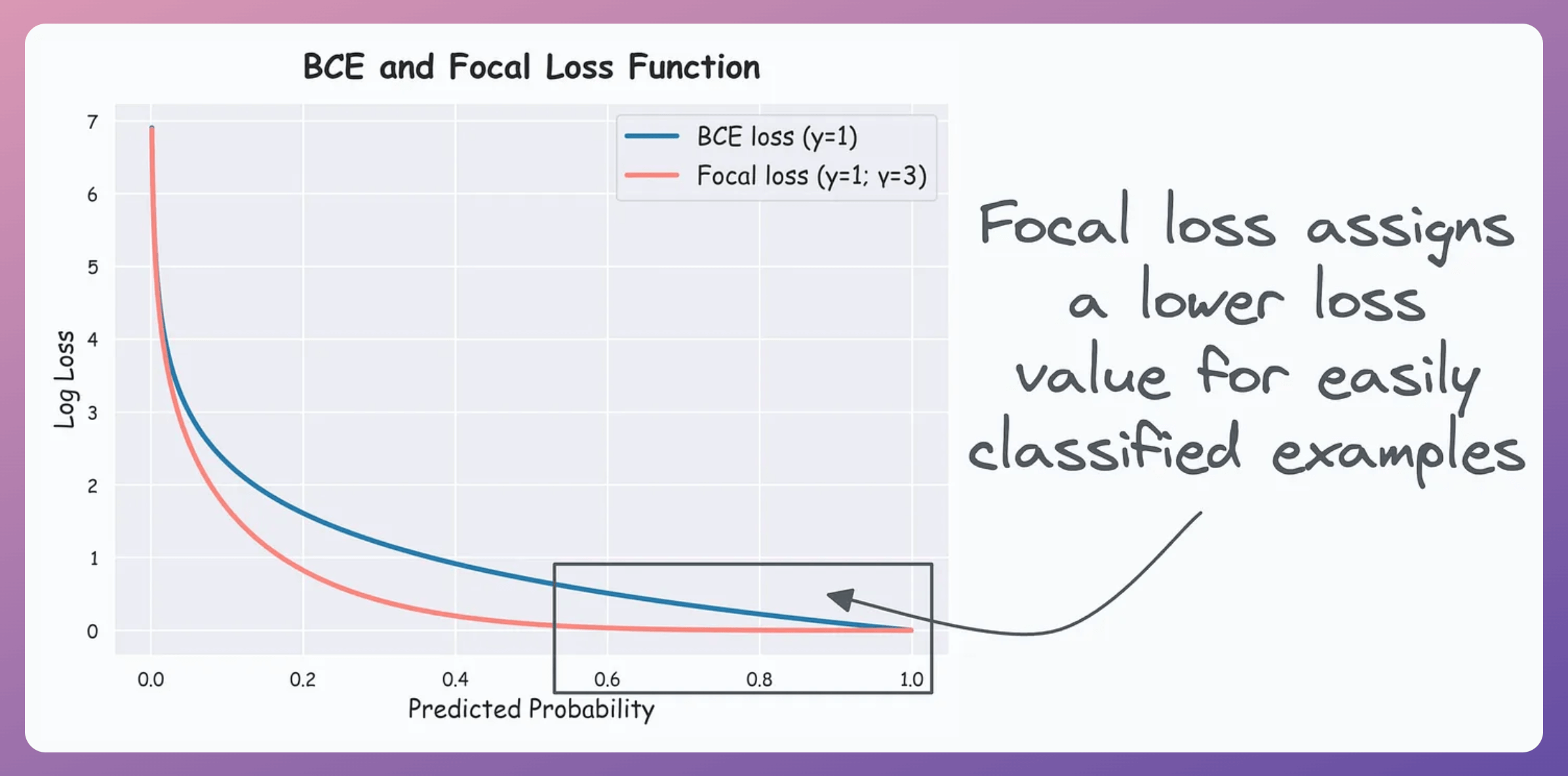
As the above plot shows, focal loss reduces the contribution of the predictions that the model is pretty confident about.
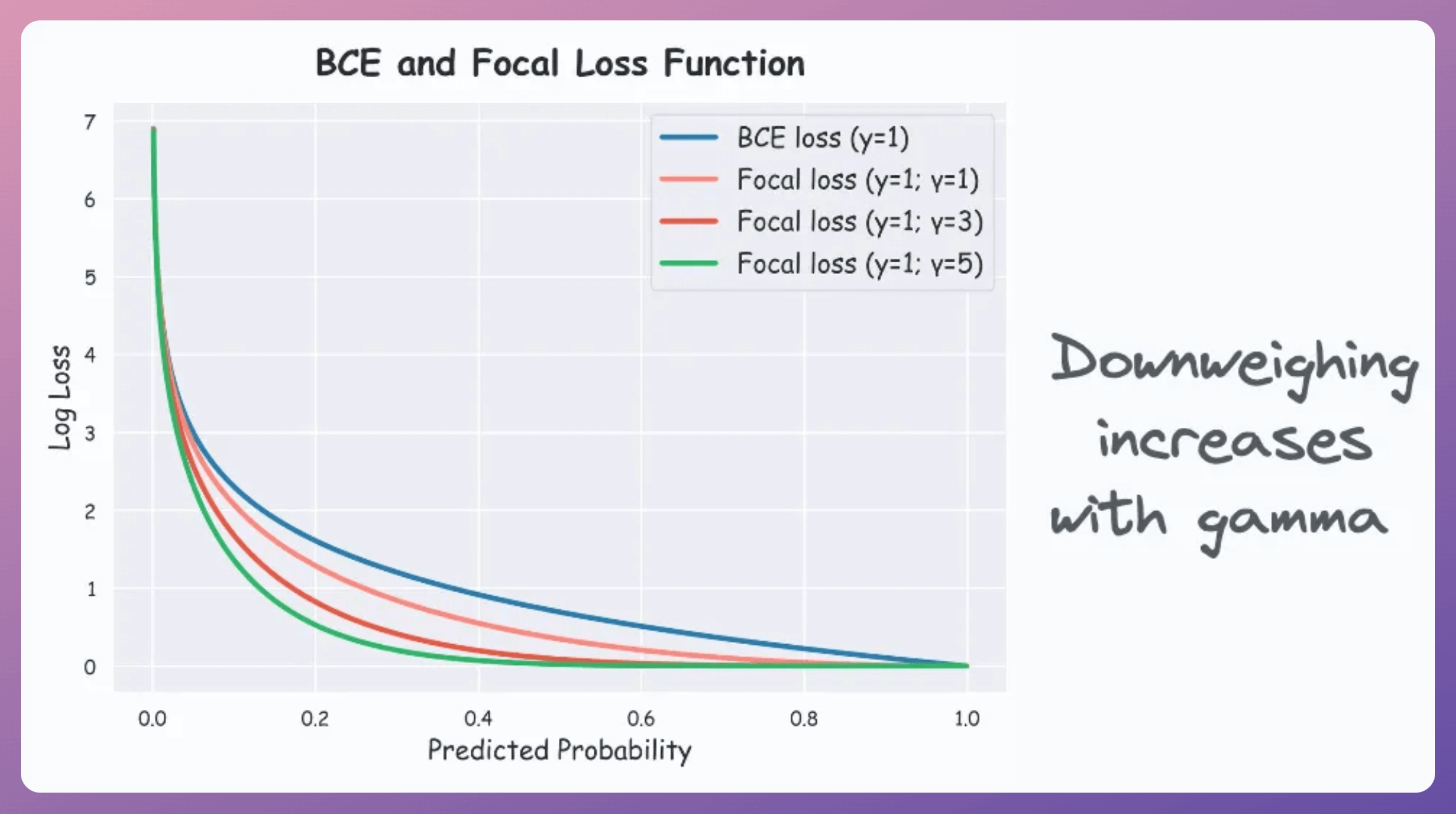
Also, the higher the value of γ (Gamma), the more downweighting takes place, which is evident from the plot below:
Despite this, if we consider the focal loss function now, we notice that it is still symmetric like BCE:
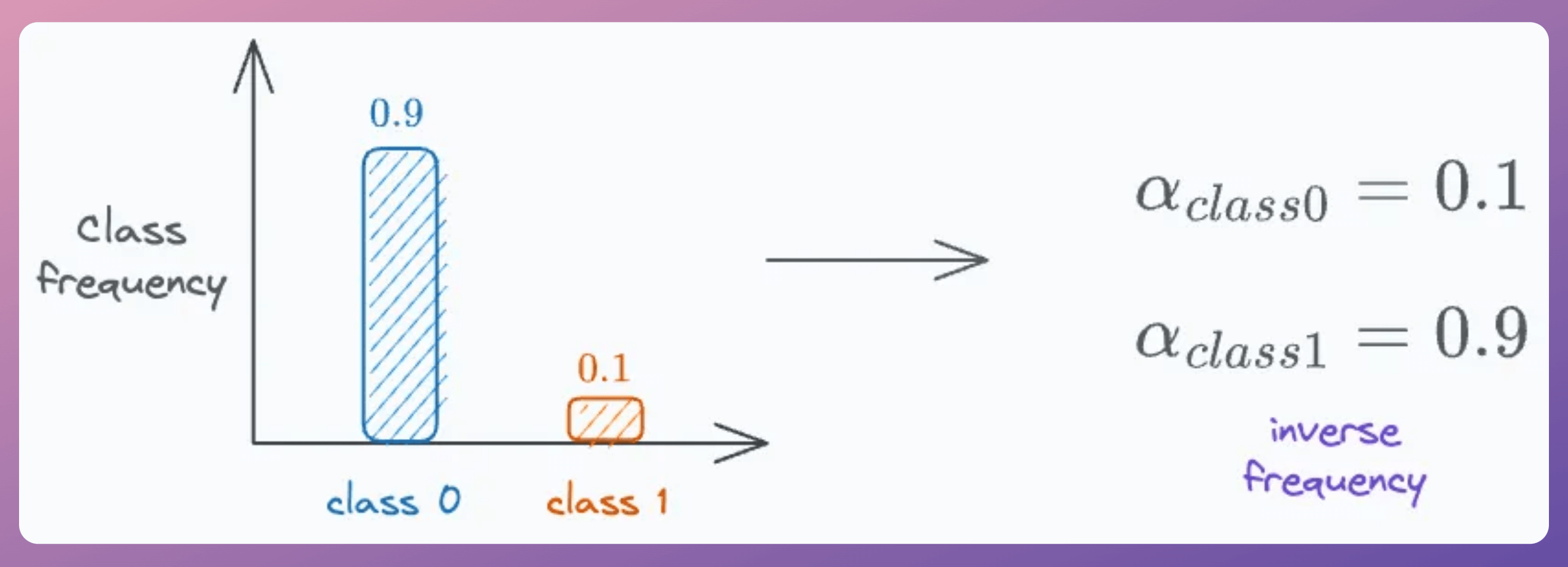
To address this, it adds another weighing parameter (α), which is the inverse of the class frequency, as depicted below:
Thus, the final loss function comes out to be the following:
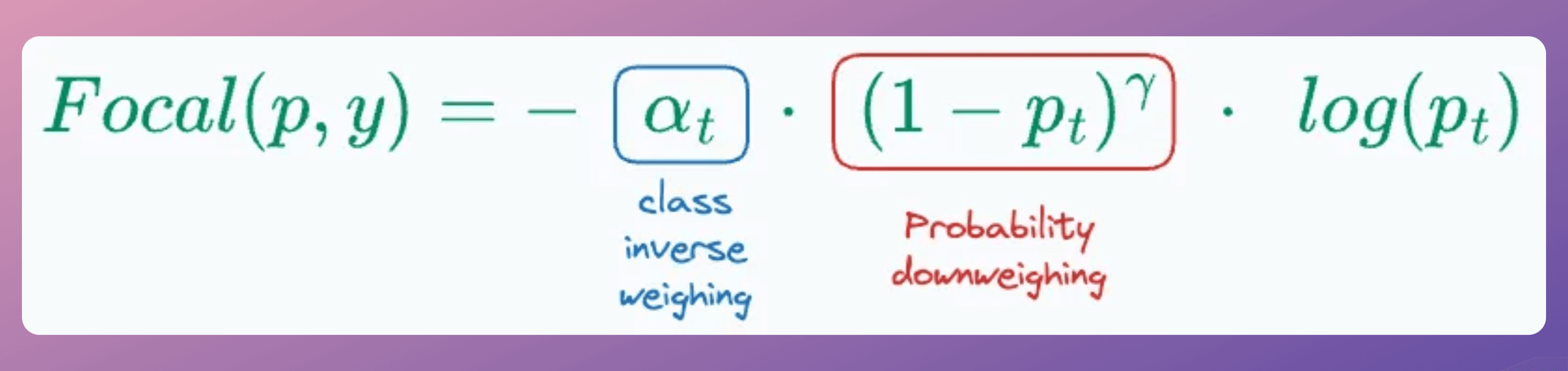
By using both downweighing and inverse weighing, the model gradually learns patterns specific to the hard examples instead of always being overly confident in predicting easy instances.
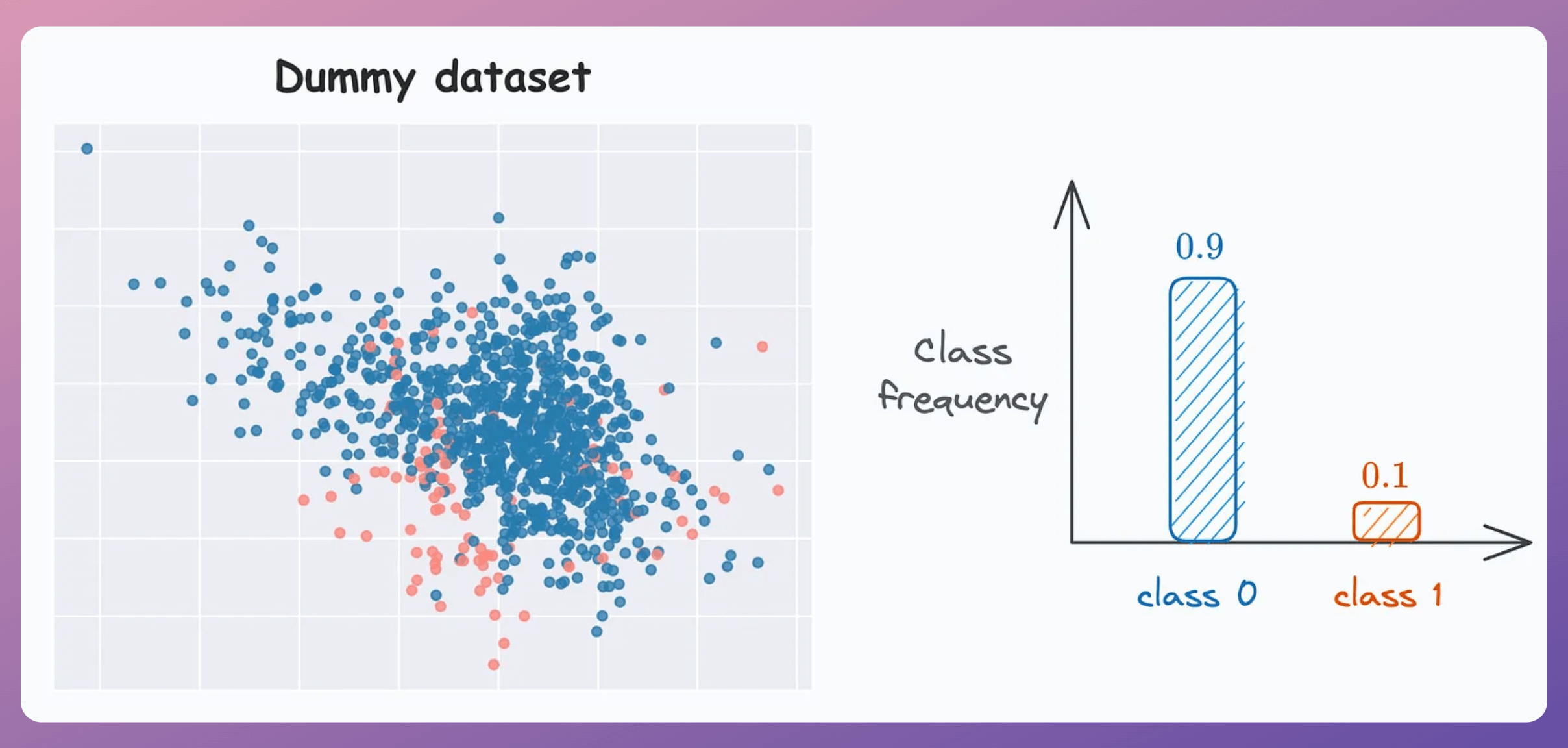
To test the efficacy in an imbalanced setting, consider this dataset with a 90:10 imbalance ratio:
Training two neural network models, one with BCE loss and another with Focal loss, produces these decision region plots and test accuracies:
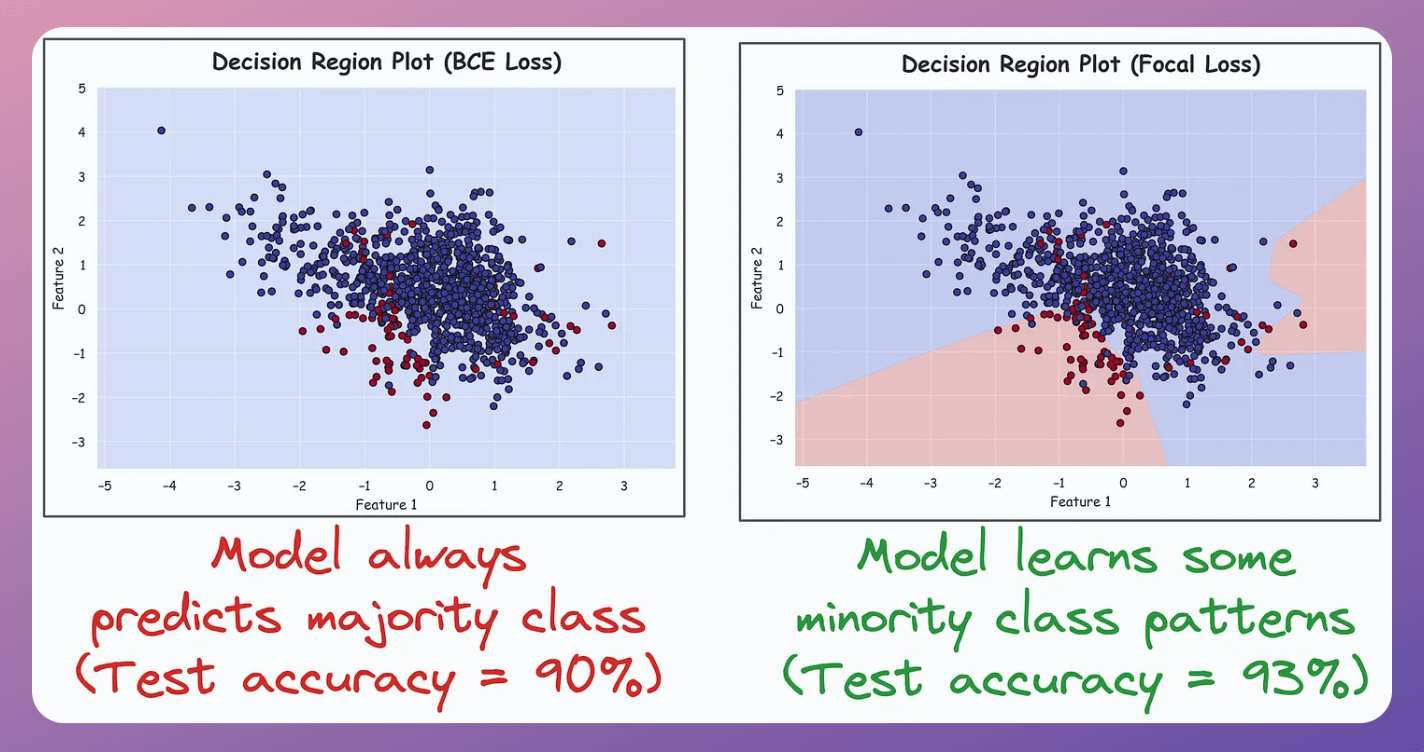
The model trained with BCE loss (left) always predicts the majority class.
The model trained with focal loss (right) focuses relatively more on minority class patterns. As a result, it performs better.
The implementation, along with several other techniques to robustify your ML models is available below:
👉 Over to you: What are some other alternatives to BCE loss under class imbalance?
Thanks for reading!