
The Intuition Behind Using ‘Variance’ in PCA
Variance = Information.

AI isn’t magic. It’s math.
Understand the concepts powering technology like ChatGPT in minutes a day with Brilliant.

Thousands of quick, interactive lessons in AI, programming, logic, data science, and more make it easy.
Try it free for 30 days here →
Thanks to Brilliant for partnering with us today!
The Intuition Behind Using ‘Variance’ in PCA
PCA is built on the idea of variance preservation.
The more variance we retain when reducing dimensions, the less information is lost.
Here’s an intuitive explanation of this.
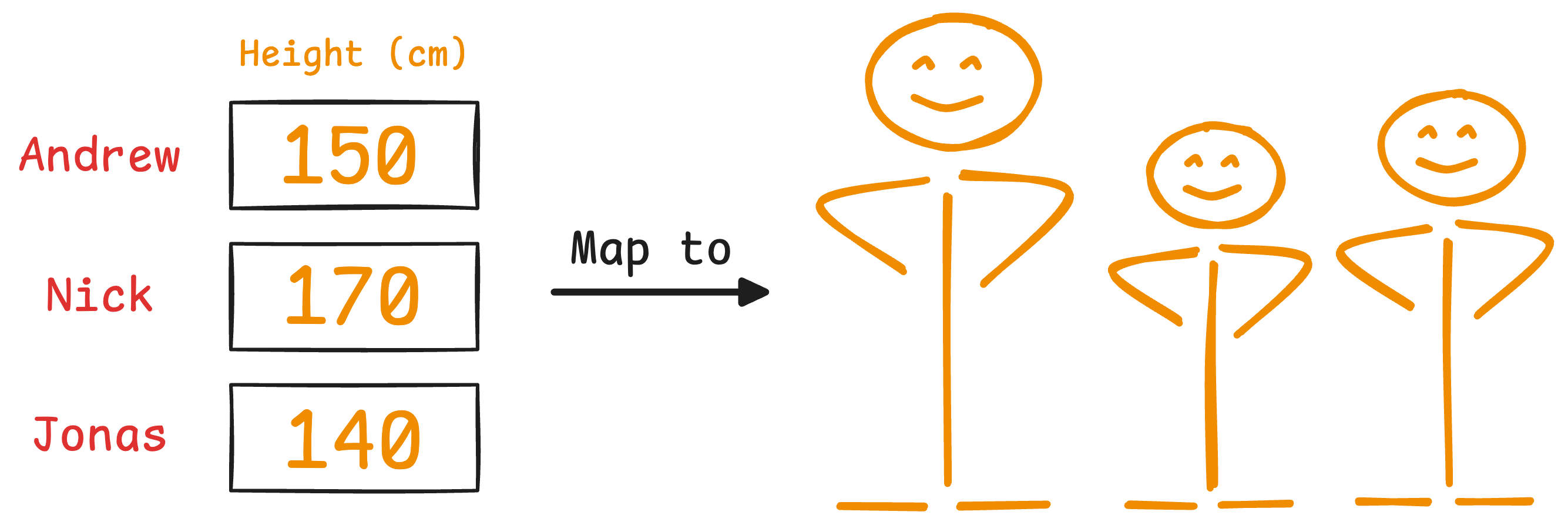
Imagine you have the following data about three people:

It is clear that height has more variance than weight.
Even if we discard the weight, we can still identify them solely based on height.
But if we discard the height, it’s a bit difficult to identify them now:

This is the premise on which PCA is built.
More specifically, during dimensionality reduction, if we retain more original data variance, we retain more information.
Of course, since it uses variance, it is influenced by outliers.
That said, in PCA, we don’t just measure column-wise variance and drop the columns with the least variance.
Instead, we transform the data to create uncorrelated features and then drop the new features based on their variance.
To dive into more mathematical details, we formulated the entire PCA algorithm from scratch here: Formulating the Principal Component Analysis (PCA) Algorithm From Scratch, where we covered:
What are vector projections, and how do they alter the mean and variance of the data?
What is the optimization step of PCA?
What are Lagrange Multipliers?
How are Lagrange Multipliers used in PCA optimization?
What is the final solution obtained by PCA?
Proving that the new features are indeed uncorrelated.
How to determine the number of components in PCA?
What are the advantages and disadvantages of PCA?
Key takeaways.
And in the follow-up part to PCA, we formulated tSNE from scratch, an algorithm specifically designed to visualize high-dimensional datasets.
We also implemented tSNE with all its backpropagation steps from scratch using NumPy. Read it here: Formulating and Implementing the t-SNE Algorithm From Scratch.
👉 Over to you: Could there be some other way of retaining “information” but not using variance as an indicator?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.