
The Limitation Of Silhouette Score Which Is Often Ignored By Many
Not all clustering results are convex.


Silhouette score is commonly used for evaluating clustering results.
At times, it is also preferred in place of the elbow curve to determine the optimal number of clusters. (I have covered this before if you wish to recap or learn more).
However, while using the Silhouette score, it is also important to be aware of one of its major shortcomings.
The Silhouette score is typically higher for convex (or somewhat spherical) clusters.
However, using it to evaluate arbitrary-shaped clustering can produce misleading results.
This is also evident from the following image:
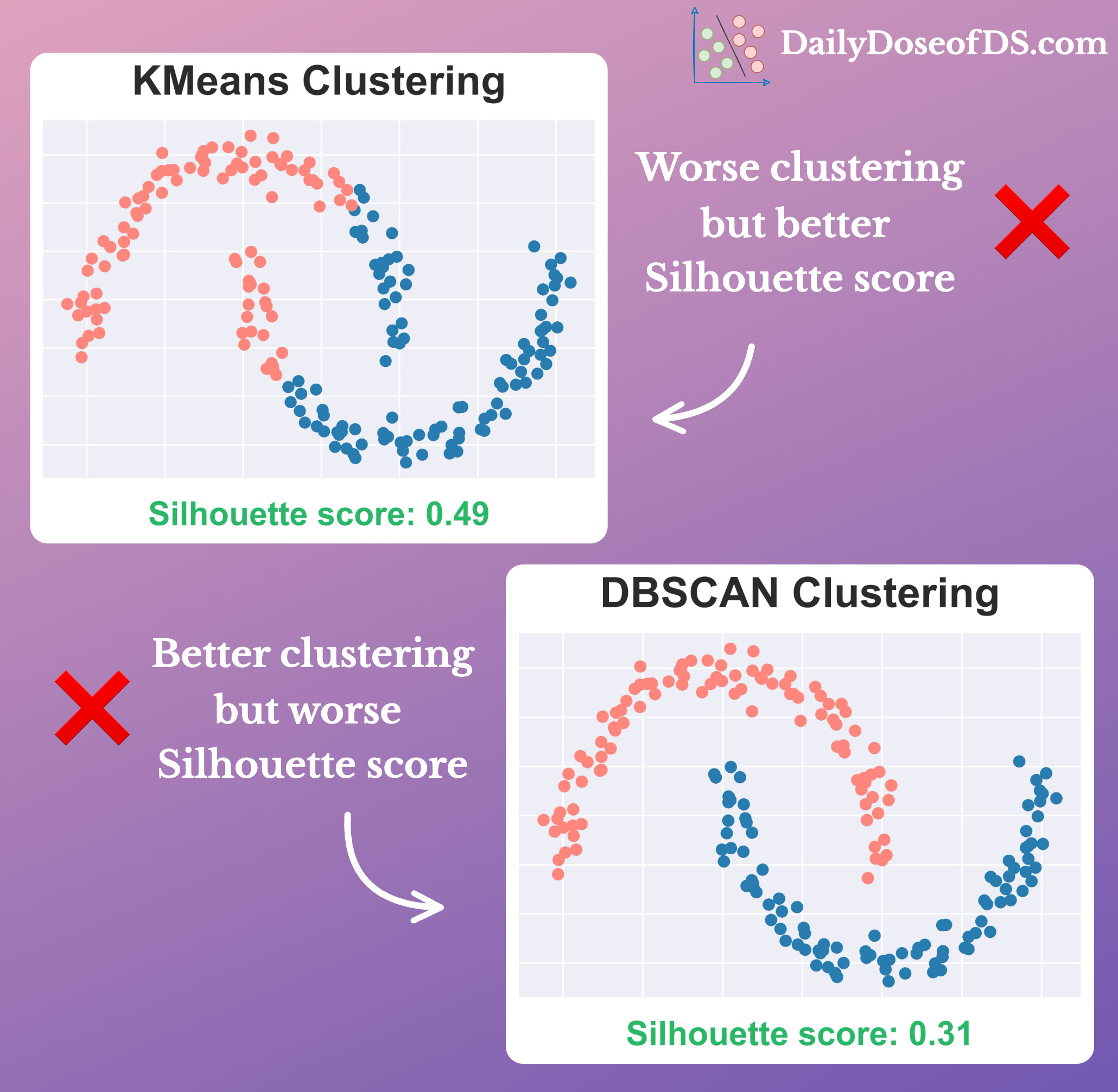
While the clustering output of KMeans is worse, the Silhouette score is still higher than Density-based clustering.
DBCV — density-based clustering validation is a better metric in such cases.
As the name suggests, it is specifically meant to evaluate density-based clustering.
Simply put, DBCV computes two values:
The density within a cluster
The density between clusters
A high density within a cluster and a low density between clusters indicates good clustering results.
DBCV can also be used when you don’t have ground truth labels.
This adds another metric to my recently proposed methods: Evaluate Clustering Performance Without Ground Truth Labels.
The effectiveness of DBCV is also evident from the image below:

This time, the score for the clustering output of KMeans is worse, and that of density-based clustering is higher.
Get started with DBCV here: GitHub.
👉 Over to you: What are some other ways to evaluate clustering where traditional metrics may not work?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Sponsor the Daily Dose of Data Science Newsletter. More info here: Sponsorship details.
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
Well, of course density-based clustering validation gives a higher score to a density-based clustering algorithm. For this example, we only know that DBCV gives a better clustering because it's obvious from plotting the data. In ten dimensions, how do you know which algorithm and which metric will give the best result?
Hi Jean, where did you find out about this disadvantage of the Silhouette, in what article? I need to cite this in my dissertation.