
The MCP Illustrated Guidebook
Free guide covering MCP fundamentals & projects.

In today's newsletter:
Scenario: Open-source testing platform for AI agents.
The MCP Illustrated Guidebook.
RAG vs. Agentic RAG, explained visually.
Scenario: Open-source testing platform for AI agents

Today, there’s a big release for the Agent development community.
Using LangWatch Scenario, you can test your agents on real-world scenarios and visualize the results.
Product Hunt Release → (don’t forget to upvote)
It is the first and only testing platform that allows you to confidently test agents in simulated realities.
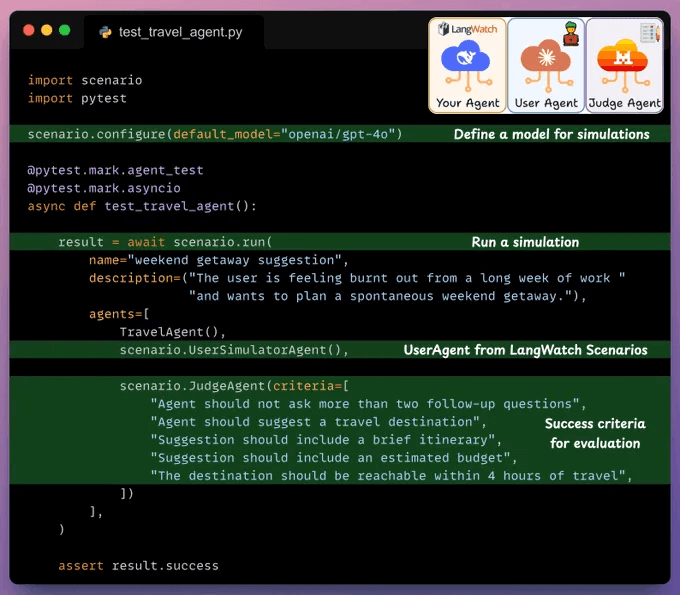
You can test edge cases by simulating users and then letting the simulation play out in conversations, with no dataset required.
From here, you can validate your full agent behavior: check for tool calls, handovers, integrate with guardrails, and more.
Learn about the release here on Product Hunt → (don’t forget to upvote).
The MCP Illustrated GuideBook
Today, we are happy to announce our MCP Illustrated Guidebook (2025 Edition):

You can access it on Google Drive here for free →
The book covers:
The foundations of MCP
The problems it solves
Architecture overview
Tools, resources, and prompts
And 11 hands-on MCP projects with well-documented code.
We intend to keep updating this frequently as we talk more and more about MCPs.
You can access the book on Google Drive here for free →
Moreover, we are actively seeking feedback on improving the guidebook, so if you have any suggestions, please reply to this email.
Lastly, you should expect an RAG/Agents Guidebook pretty soon.
Happy learning!
RAG vs. Agentic RAG
RAG has some issues:
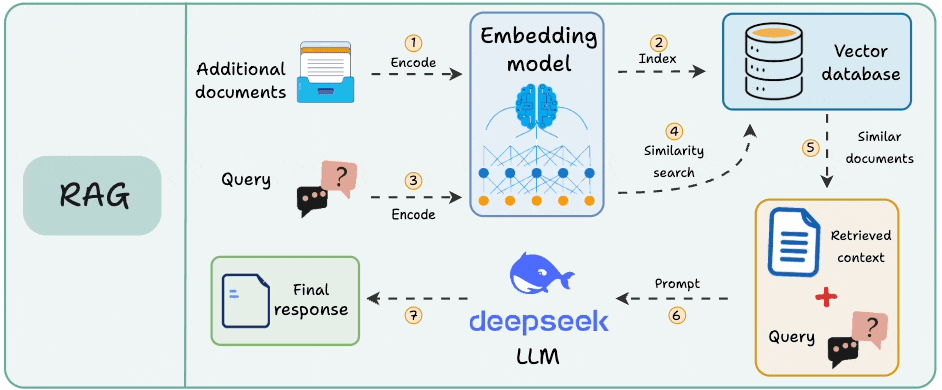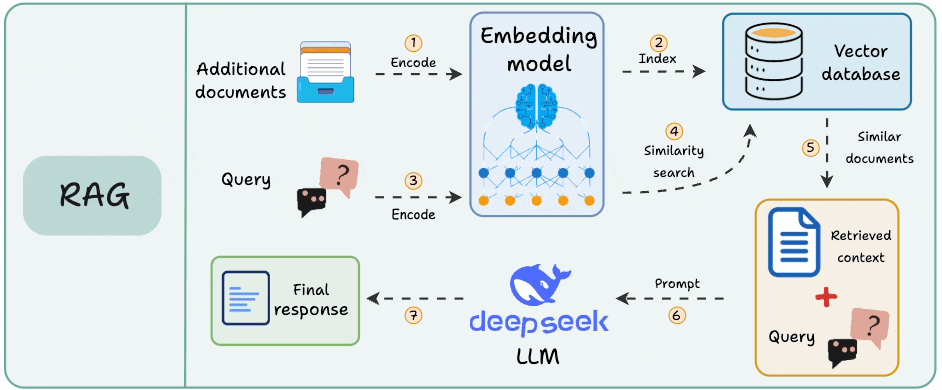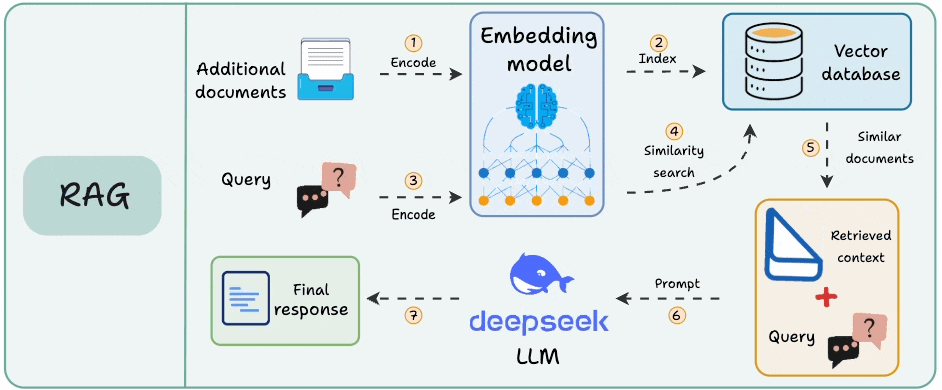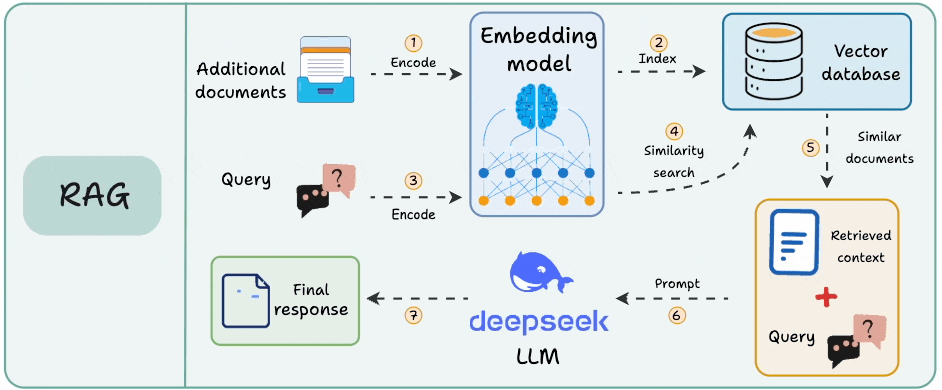
It retrieves once and generates once. If the context isn’t enough, it cannot dynamically search for more info.
It cannot reason through complex queries.
The system can’t modify its strategy based on the problem.
Agentic RAG attempts to solve this.
The following visual depicts how it differs from traditional RAG.
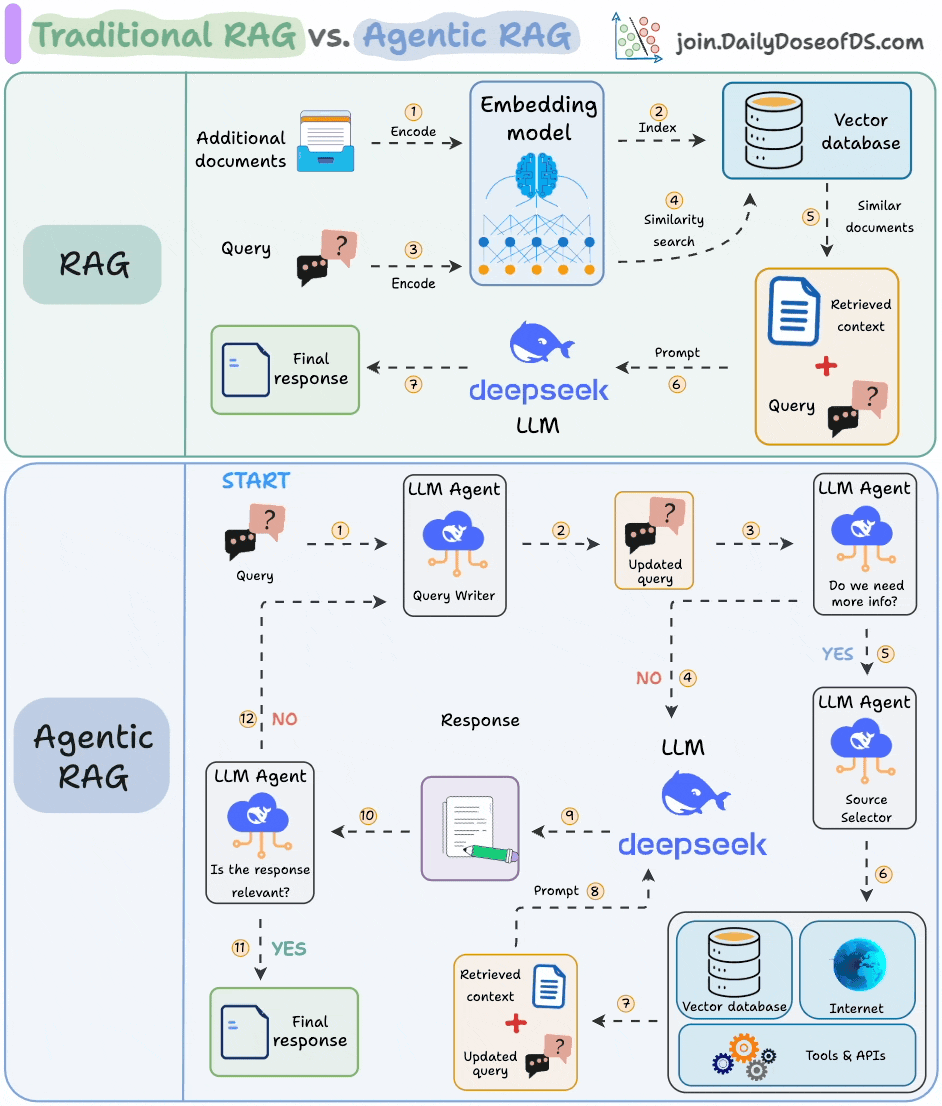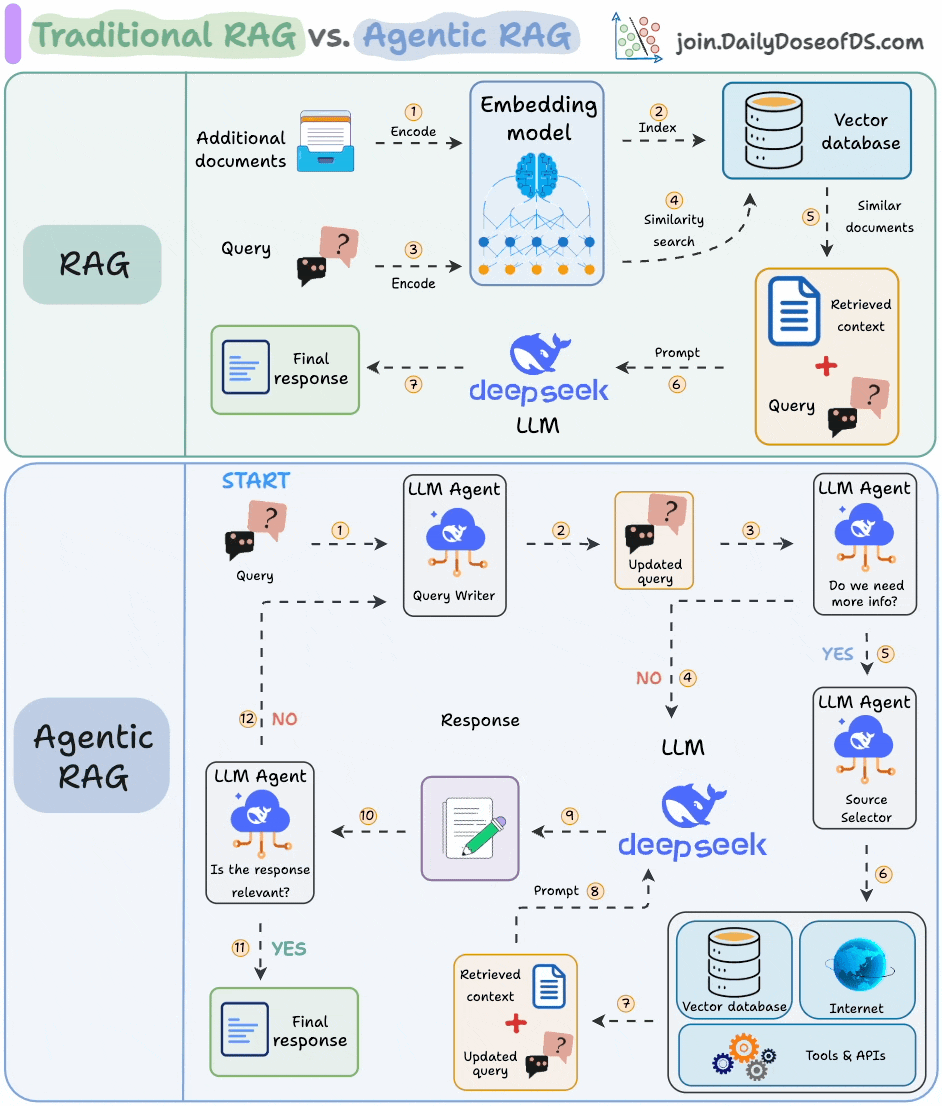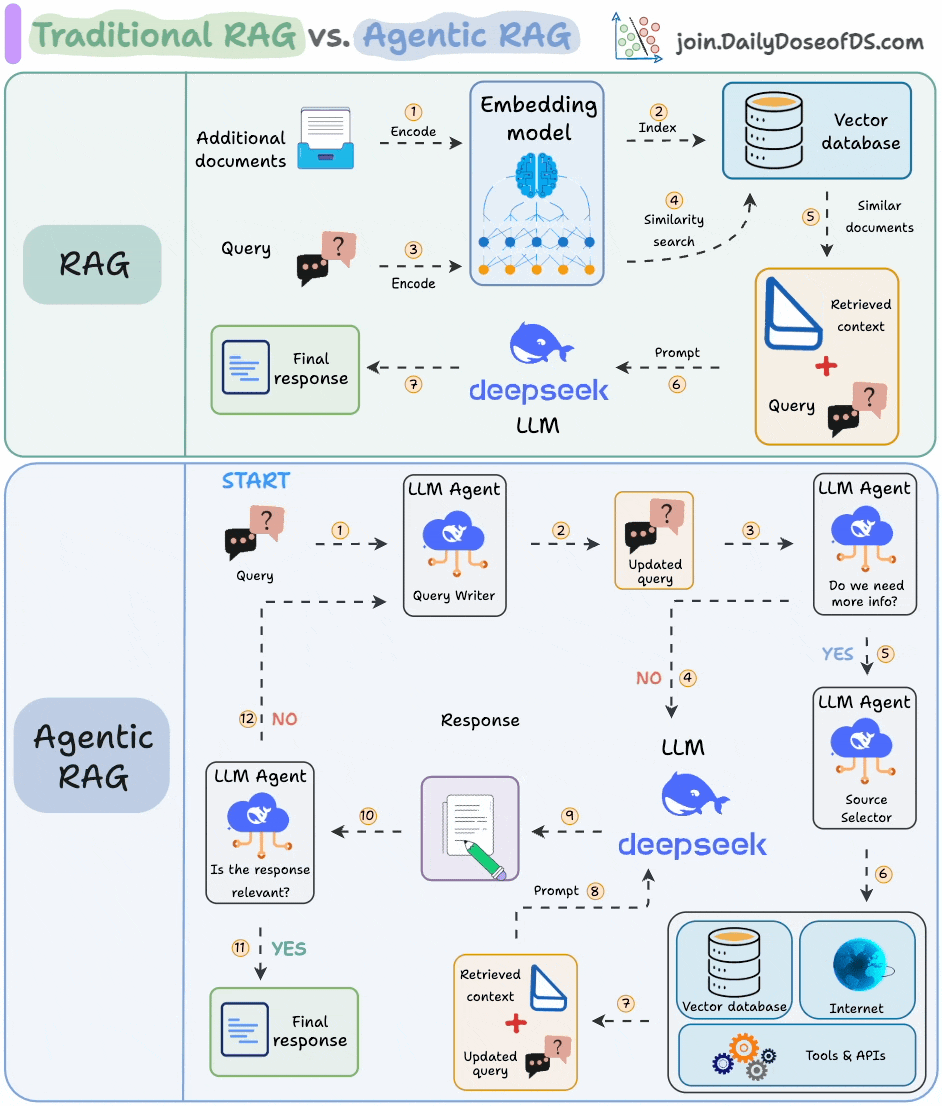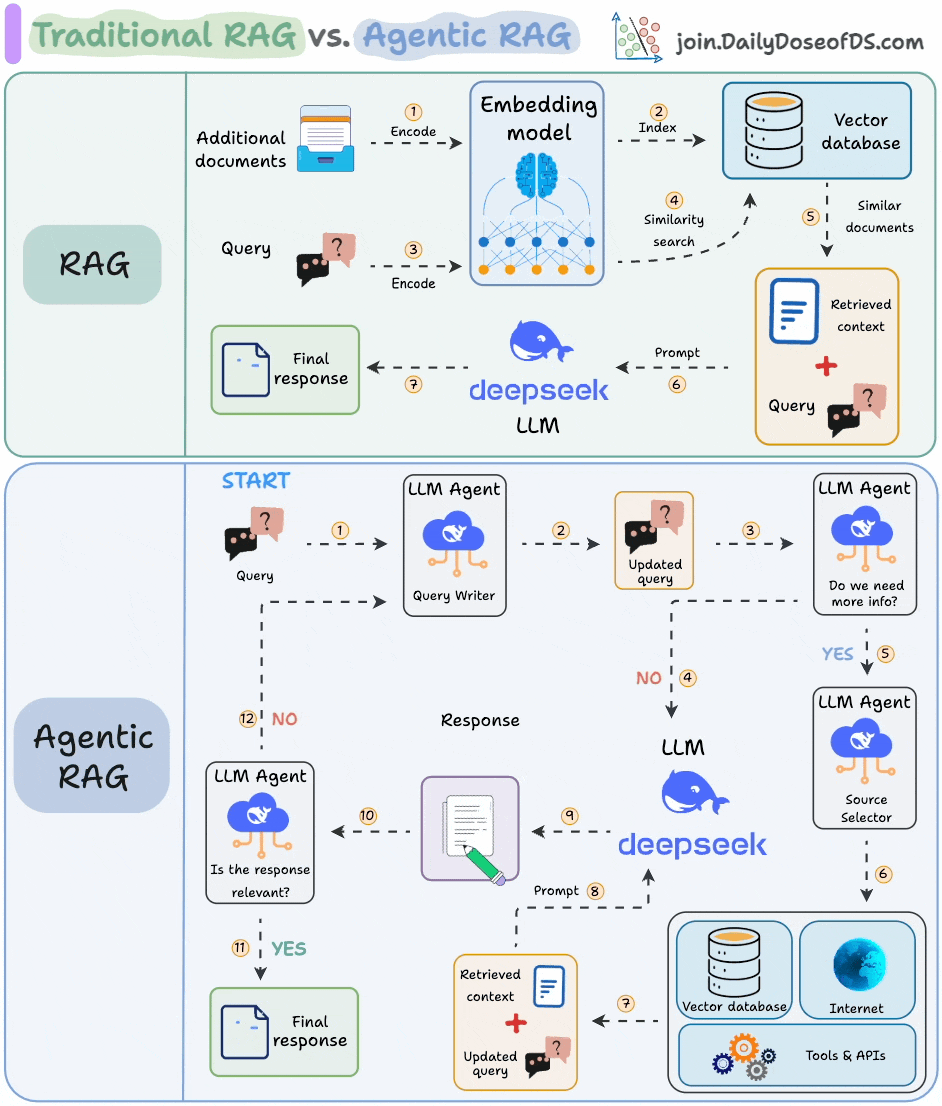
The core idea is to introduce agentic behaviors at each stage of RAG.
Steps 1-2) An agent rewrites the query (removing spelling mistakes, etc.)
Step 3-8) An agent decides if it needs more context.
If not, the rewritten query is sent to the LLM.
If yes, an agent finds the best external source to fetch context, to pass it to the LLM.
Step 9) We get a response.
Step 10-12) An agent checks if the answer is relevant.
If yes, return the response.
If not, go back to Step 1.
This continues for a few iterations until we get a response or the system admits it cannot answer the query.
This makes RAG more robust since agents ensure individual outcomes are aligned with the goal.
That said, the diagram shows one of the many blueprints an agentic RAG system may possess.
You can adapt it according to your specific use case.
Soon, we shall cover Agentic RAG and many more related techniques to building robust RAG systems.
In the meantime, make sure you are fully equipped with everything we have covered so far like:
What you are using for graphs ?
Thank you so much for such content,you are the best