
The M*N Integration Problem Solved by MCP
...explained visually.

In today’s newsletter:
Generate LLM-ready text files from a Website URL.
The M*N Integration Problem Solved by MCP.
[Hands-on] Build a common memory layer for all your AI apps.
Traditional RAG vs. HyDE.
🔥 Generate LLM-ready text files from website URL

The /llms.txt endpoint of Firecrawl lets you convert any website into a single file standard for AI.
Just add llmstxt.new in front of any URL to get LLM-ready data.
For instance, “domain.com” will become “llmstxt.new/domain.com.”.”
The M*N Integration Problem Solved by MCP
MCP provides a standardized way for LLMs and AI app to connect with tools using a client-server architecture.
But it solves a much bigger problem than that, known as the M*N integration problem!
Let’s understand today!
Imagine you have M apps, and each app should have access to N tools!
Before MCP:
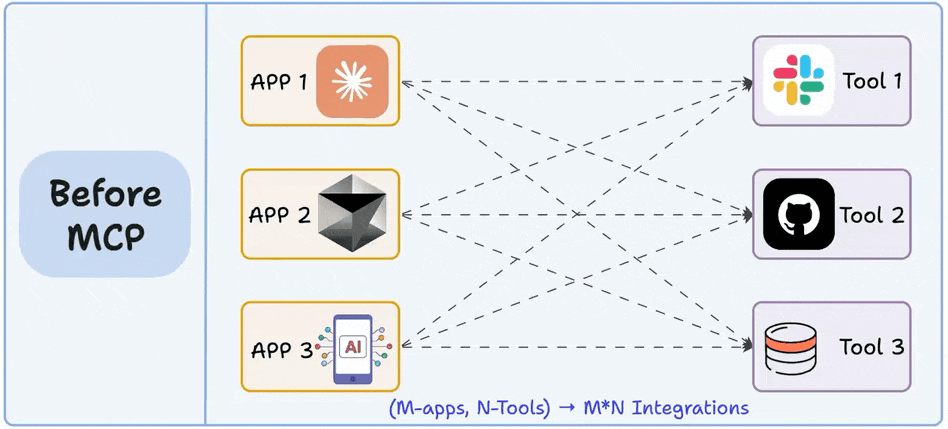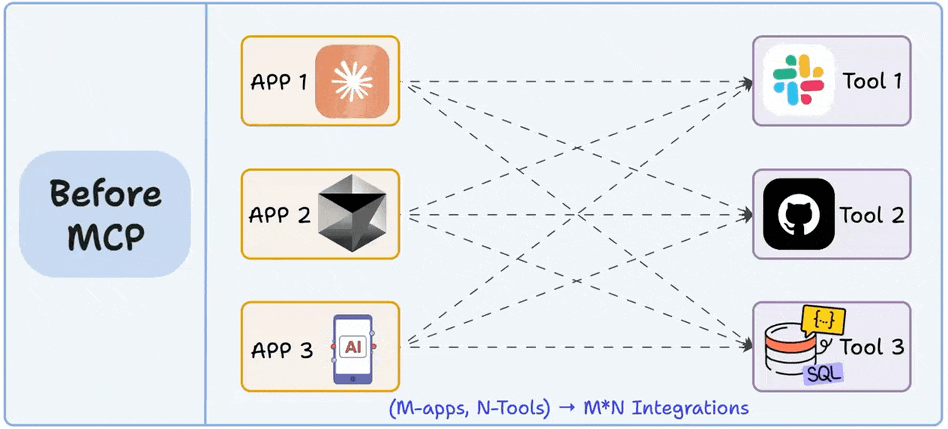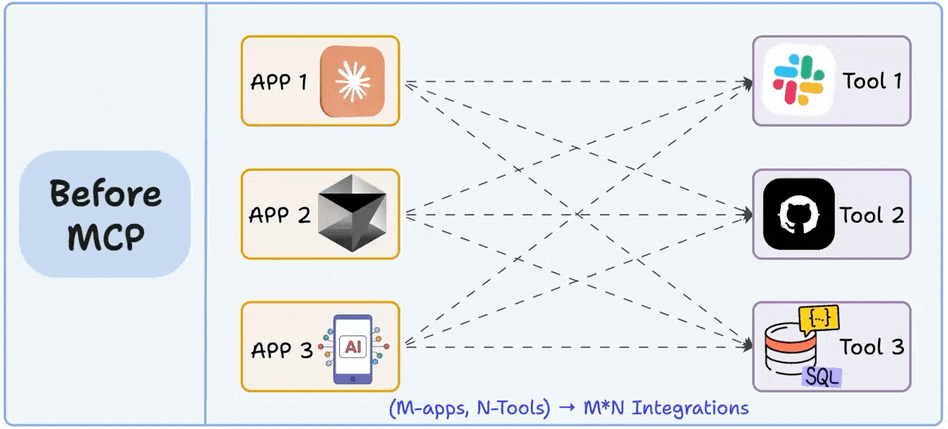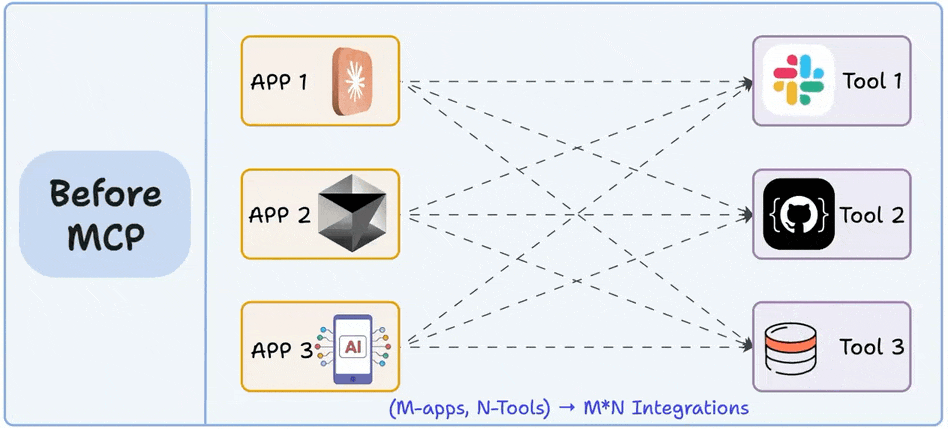
Every LLM/AI app operated in silos, each writing it’s own tool integration.
Every new connection meant building a custom integration.
M apps & N tools led to M×N integrations.
There was no shared protocol for engineers to rely on.
After MCP:
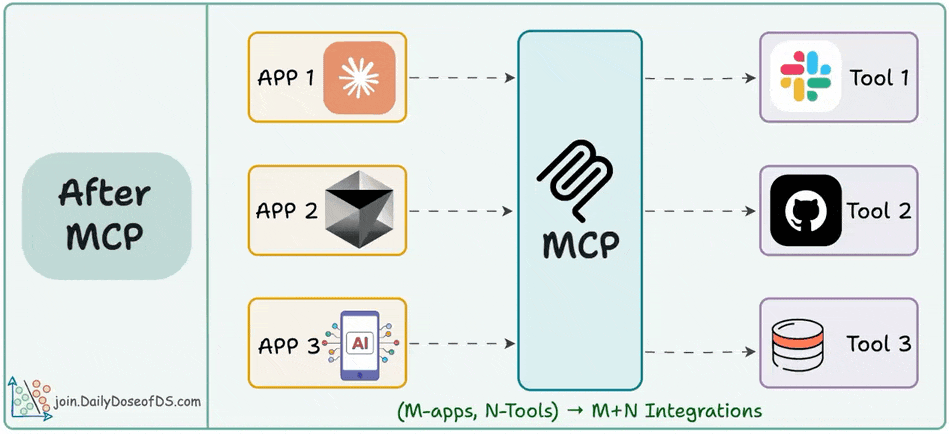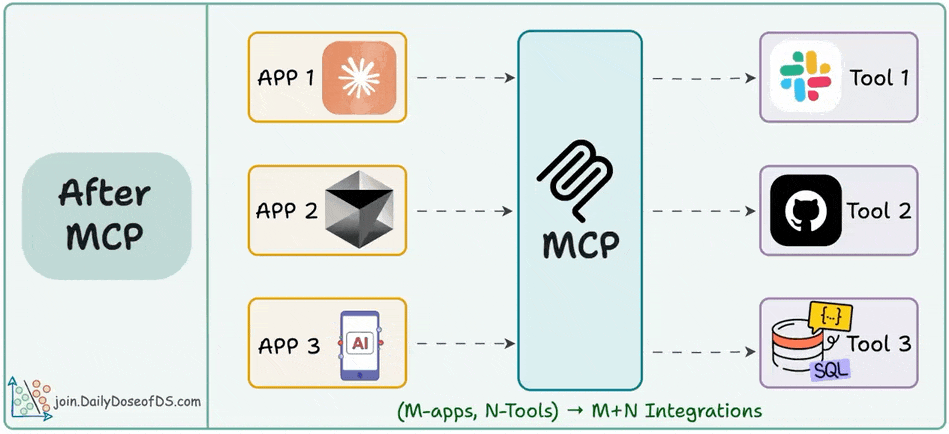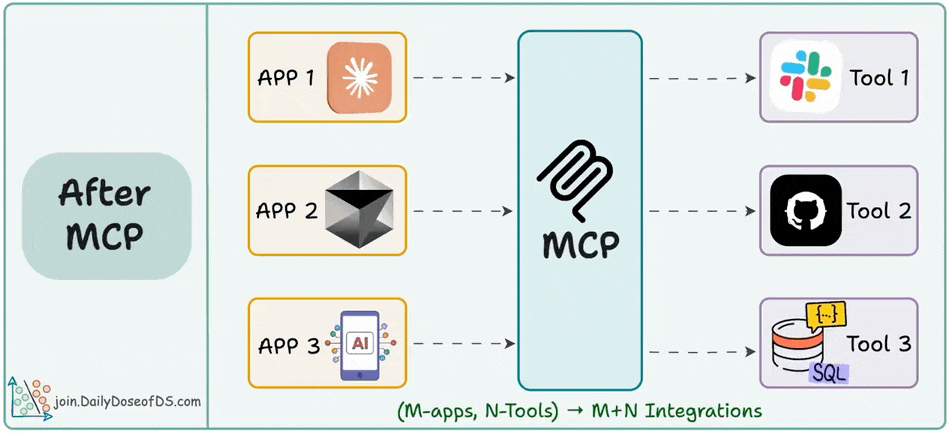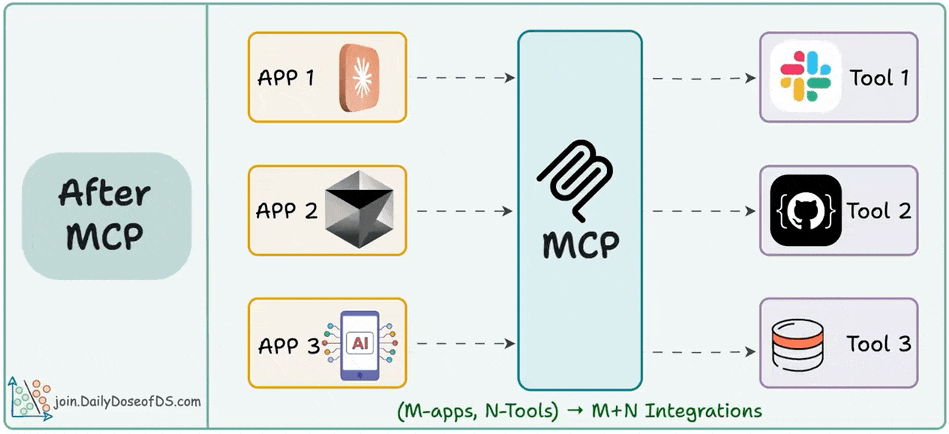
Just create one MCP server for your tool.
It plugs into any AI app that speaks MCP.
You go from M×N complexity to just M + N integrations.
On a side note, a similar strategy is also popular in Google Translate.
There are over 250 supported languages. Building a dedicated model for each possible language pair would result in ~62,000 translation models (250 × 249).
That’s not scalable.
Instead, we use an interlingua approach, where languages are first mapped to an intermediate space and then translated into the target language.
This reduces the required mappings from M×N to M + N, just like MCP does for AI tools and apps.
In case you missed it, we started a foundational implementation-heavy crash course on MCP recently:
In Part 1, we introduced:
Why context management matters in LLMs.
The limitations of prompting, chaining, and function calling.
The M×N problem in tool integrations.
And how MCP solves it through a structured Host–Client–Server model.
In Part 2, we went hands-on and covered:
The core capabilities in MCP (Tools, Resources, Prompts).
How JSON-RPC powers communication.
Transport mechanisms (Stdio, HTTP + SSE).
A complete, working MCP server with Claude and Cursor.
Comparison between function calling and MCPs.
In Part 3, we built a fully custom MCP client from scratch:
How to build a custom MCP client and not rely on prebuilt solutions like Cursor or Claude.
What the full MCP lifecycle looks like in action.
The true nature of MCP as a client-server architecture, as revealed through practical integration.
How MCP differs from traditional API and function calling, illustrated through hands-on implementations.
In Part 4, we covered:
What exactly are resources and prompts in MCP.
Implementing resources and prompts server-side.
How tools, resources, and prompts differ from each other.
Using resources and prompts inside the Claude Desktop.
A full-fledged real-world use case powered by coordination across tools, prompts, and resources.
👉 Over to you: What is your take on MCP, and what are you using it for?
Build a common memory layer for all your AI apps
Knowledge graphs are insanely good at giving agents human-like memory!
Recently, we built an MCP-powered memory layer that can be shared across all your AI apps like Cursor, Claude Desktop, etc.
Here's a complete walk-through:
It's built using a real-time knowledge graph.
Tech stack:
Everything is 100% open-source and self-hosted.
Traditional RAG vs. HyDE
One critical problem with the traditional RAG system is that questions are not semantically similar to their answers.
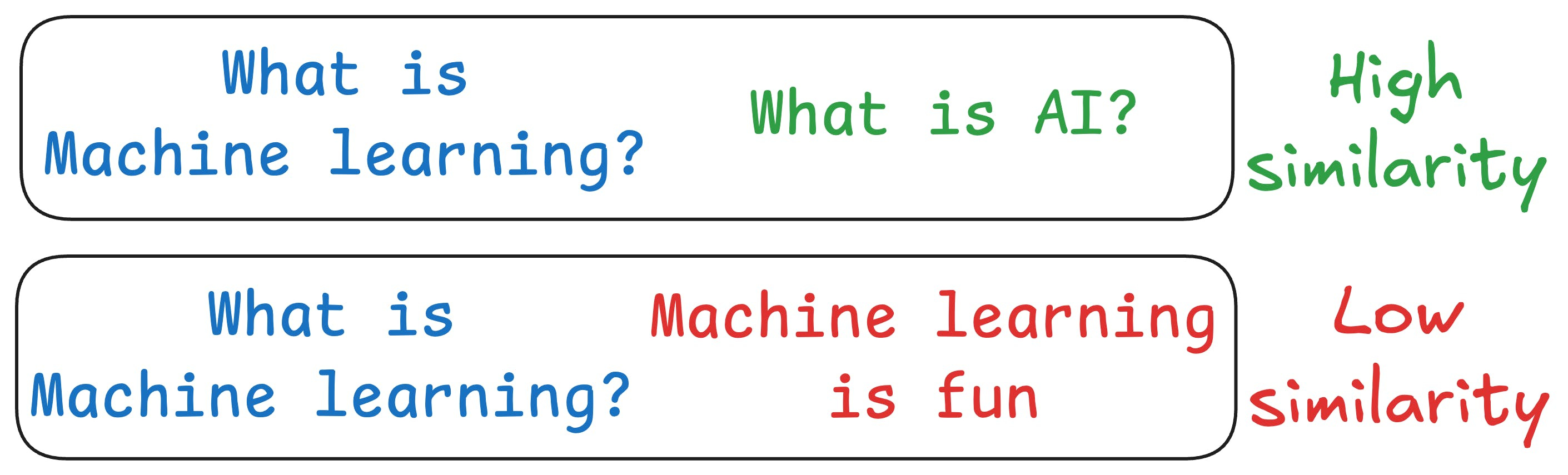
As a result, several irrelevant contexts get retrieved during the retrieval step due to a higher cosine similarity than the documents actually containing the answer.
HyDE solves this.
The following visual depicts how it differs from traditional RAG:
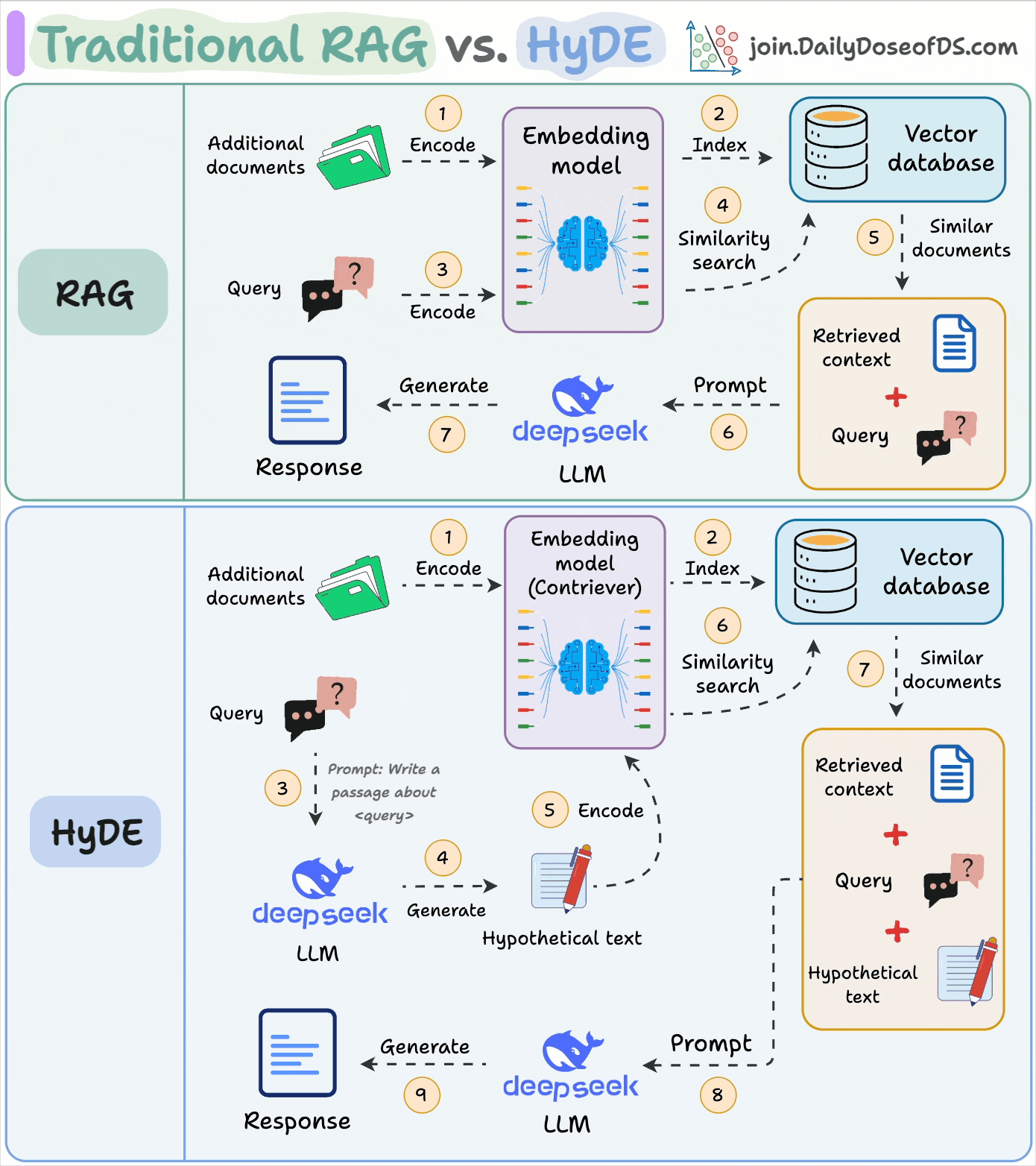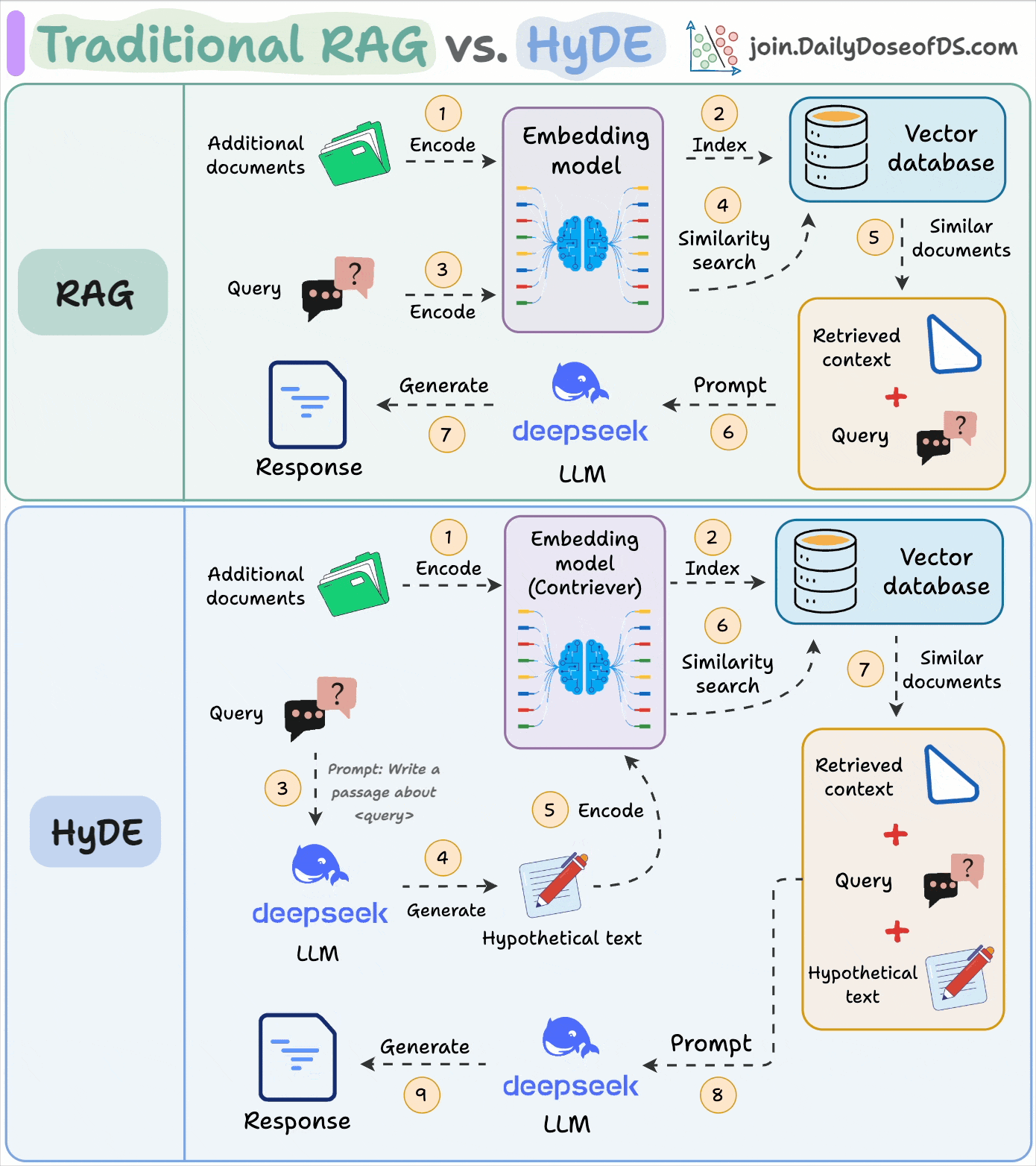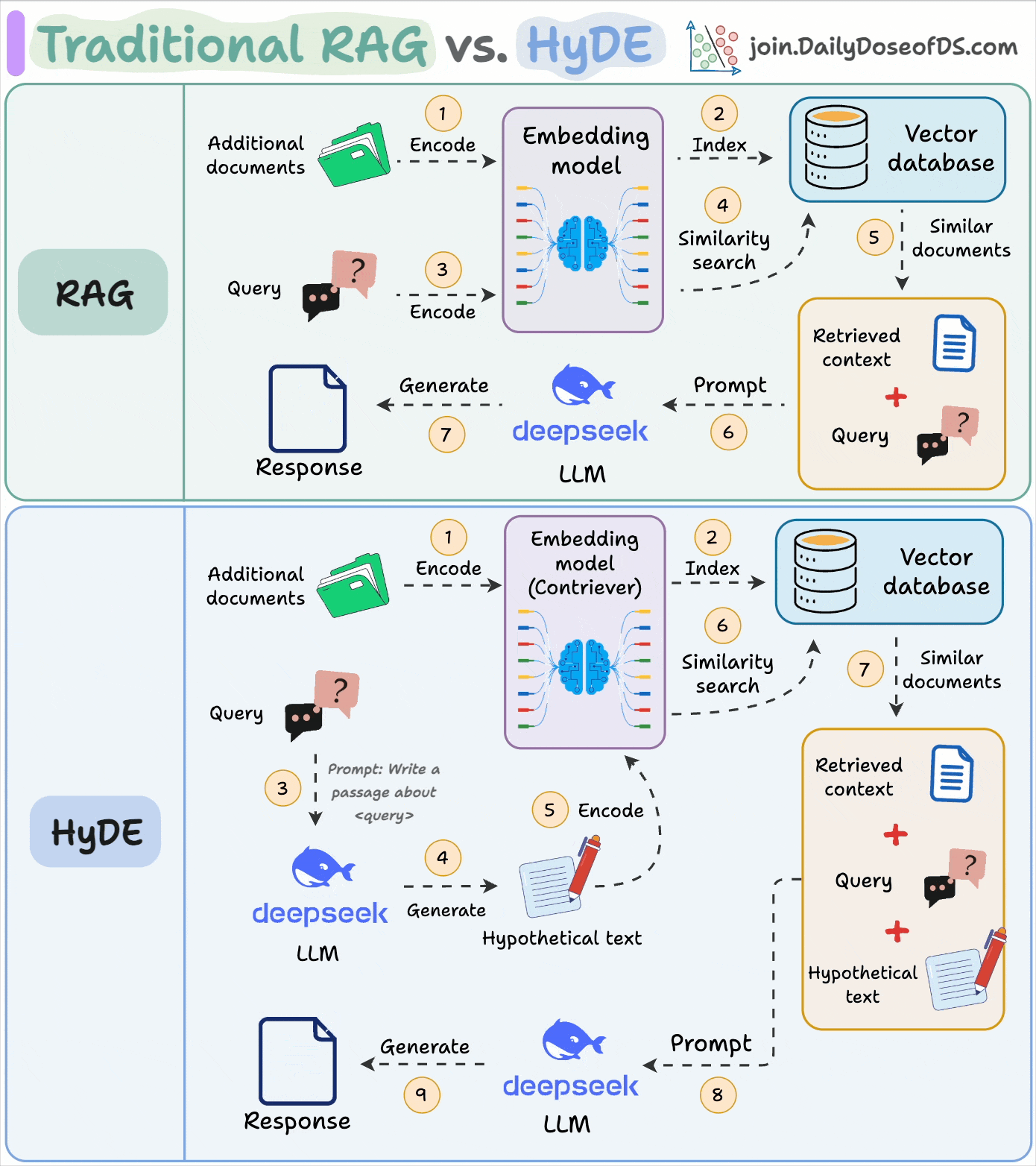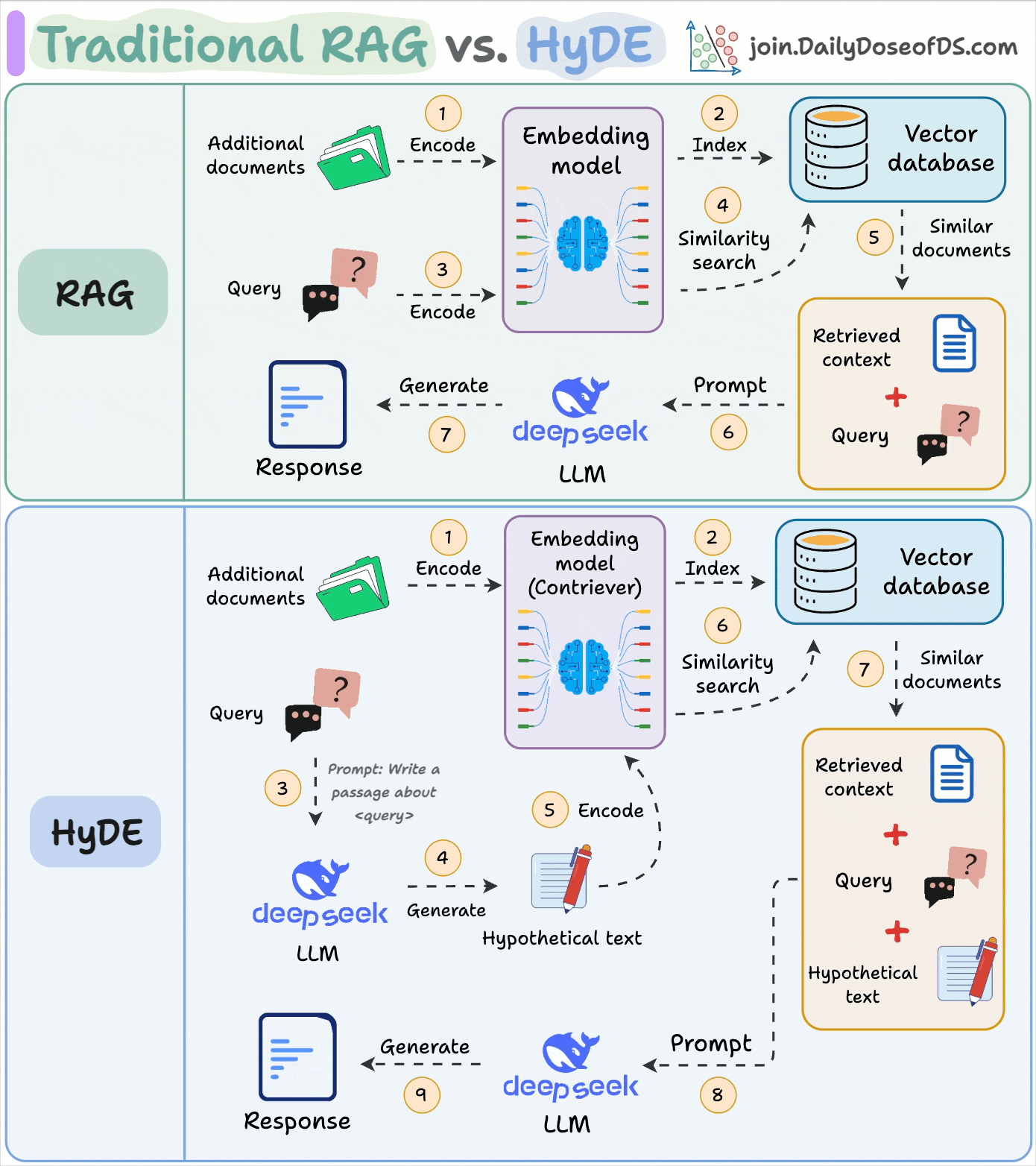
Use an LLM to generate a hypothetical answer
Hfor the queryQ(this answer does not have to be entirely correct).Embed the answer using a contriever model to get
E(Bi-encoders are famously used here, which we discussed and built here).Use the embedding
Eto query the vector database and fetch relevant context (C).Pass the hypothetical answer
H+ retrieved-contextC+ queryQto the LLM to produce an answer.
Several studies have shown that HyDE improves the retrieval performance compared to the traditional embedding model.
Learn more in this newsletter issue →
Thanks for reading!