
The Most Common Misconception That Pandas Users Have
The counterintuitive behaviour of inplace operations.

Most Pandas users have a misconception about inplace operations.
They profoundly use them in expectation of:
Smaller run-time
Lower memory usage
And, of course, the reasoning makes intuitive sense as well.
Inplace, as the name suggests, must modify the DataFrame without creating a new copy. Thus, it is okay to expect that inplace will be more efficient.
Yet, this is rarely the case, which is also evident from the image below:
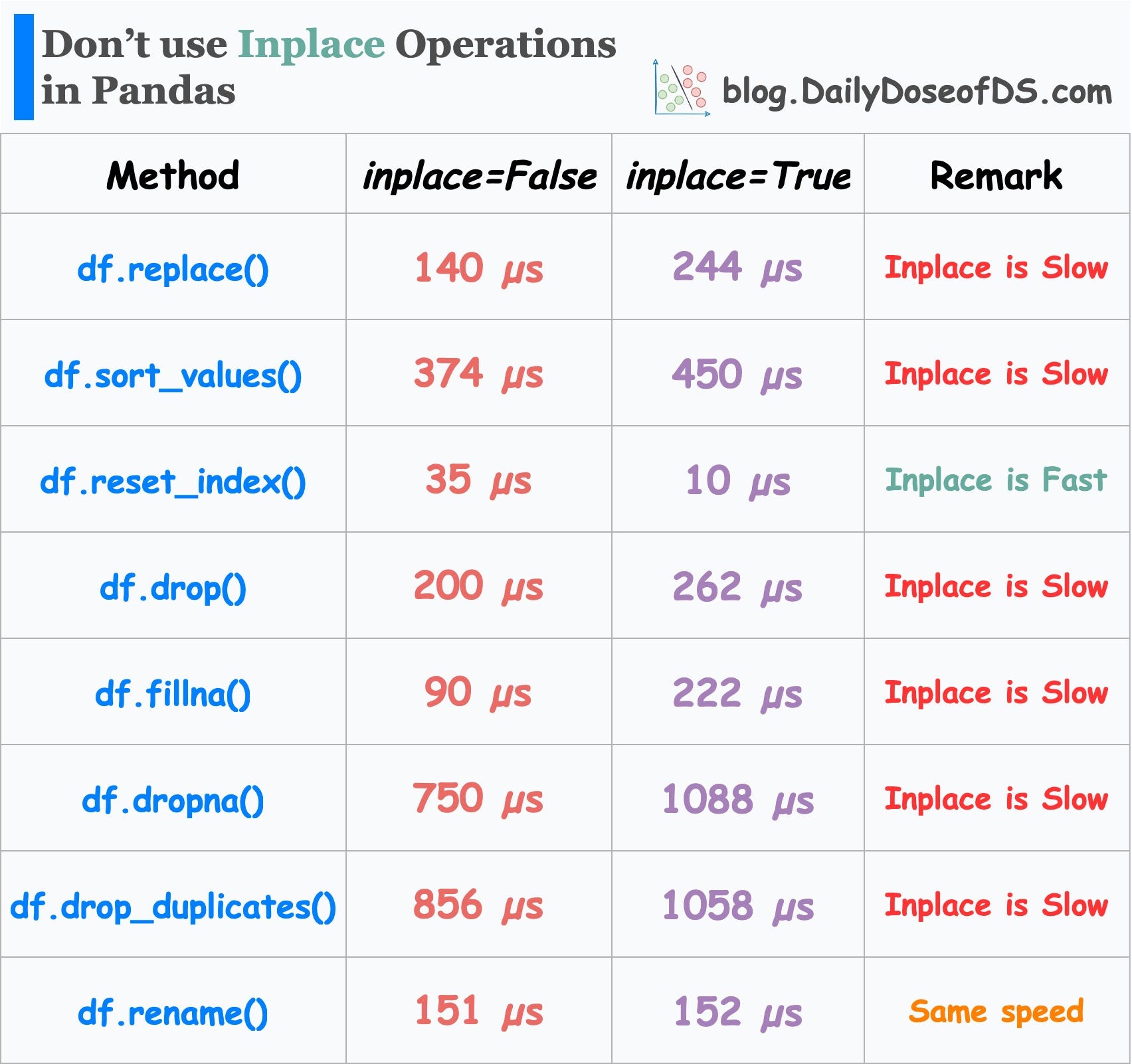
It is clear that in most cases, inplace operations are slow.
Why does this happen?
Contrary to common belief, Pandas’ inplace operations NEVER prevent the creation of a new copy.
It is just that these operations assign the copy back to the same address.
But during this assignment step, Pandas has to perform some additional checks — SettingWithCopy, for instance, to ensure that the DataFrame is being modified correctly.
This, at times, can be an expensive operation.
Yet, in general, there is no guarantee that an inplace operation is faster, which is also validated by the results above.
What’s more, one thing I particularly dislike about inplace operations is that they inhibit method chaining as depicted below:

As a result, I never prefer using inplace operations in Pandas.
👉Over to you: Despite this, are there still any situations where you prefer using inplace operations in Pandas?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
And in lots of cases you get the cursed SettingWithCopyWarning.