
The Most Underrated Skill in Training Linear Models
...and how to cultivate it.


Yesterday’s post on Poisson regression was appreciated by many of you.
Today, I want to build on that and help you cultivate what I think is one of the MOST overlooked and underappreciated skills in developing linear models.
I can guarantee that harnessing this skill will give you so much clarity and intuition in the modeling stages.
But let’s do a quick recap of yesterday’s post before we proceed.
Recap
Having a non-negative response in the training data does not stop linear regression from outputting negative values.
Essentially, you can always extrapolate the regression fit for some inputs to get a negative output.

While this is not an issue per se, negative outputs may not make sense in cases where you can never have such outcomes.
For instance:
Predicting the number of calls received.
Predicting the number of cars sold in a year, etc.
More specifically, the issue arises when modeling a count-based response, where a negative output wouldn’t make sense.
In such cases, Poisson regression often turns out to be a more suitable linear model than linear regression.
This is evident from the image below:

Please read yesterday’s post for in-depth info: Poisson Regression: The Robust Extension of Linear Regression.
Here, I want you to understand that Poisson regression is no magic.
It’s just that, in this specific use case, the data generation process didn’t perfectly align with what linear regression is designed to handle.
In other words, as soon as we trained a linear regression model above, we inherently assumed that the data was sampled from a normal distribution.
But that was not true in this case.

Instead, it came from a Poisson distribution, which is why Poisson regression worked better.
Thus, the takeaway is that whenever you train linear models, always always and always think about the data generation process.
This goes like this:
Okay, I have this data.
I want to fit a linear model through it.
What information do I get from the label about the data generation process that can help me select an appropriate linear model?
You’d start appreciating the importance of data generation when you’d realize that literally EVERY extension of linear regression (or a member of the generalized linear model family) stems from altering the data generation process.
For instance:
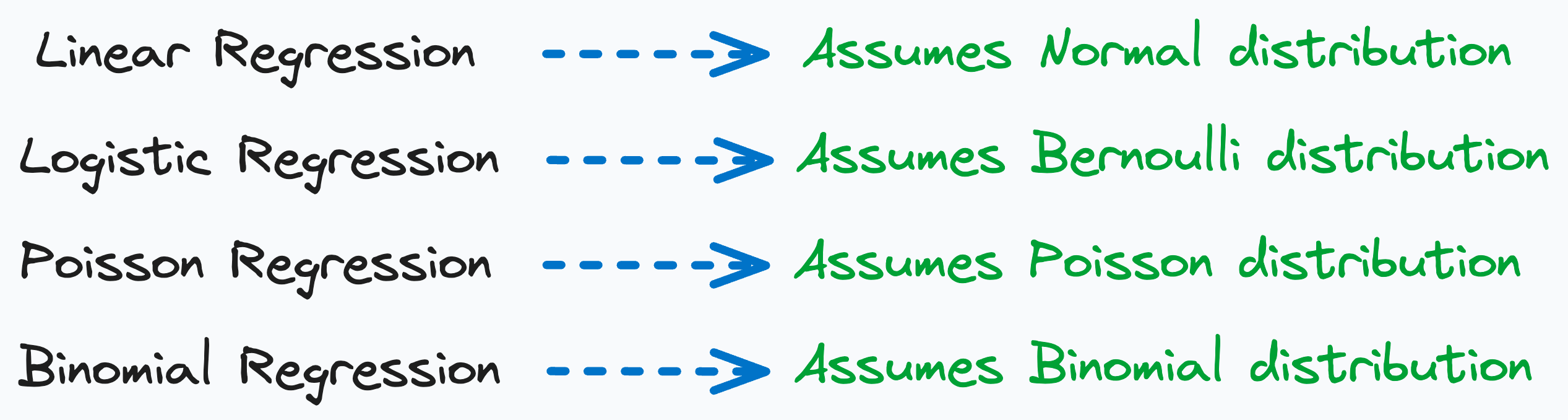
If the data generation process involves a Normal distribution → you get linear regression.
If the data has only positive integers in the response variable, maybe it came from a Poisson distribution → and this gives us Poisson regression. This is precisely what we discussed yesterday.
If the data has only two targets — 0 and 1, maybe it was generated using Bernoulli distribution → and this gives rise to logistic regression.
If the data has finite and fixed categories (0, 1, 2,…n), then this hints towards Binomial distribution → and we get Binomial regression.
See…
Every linear model makes an assumption and is then derived from an underlying data generation process.
Thus, developing a habit of stepping back and thinking about the data generation process will give you so much clarity in the modeling stages.
I am confident this will help you get rid of that annoying and helpless habit of relentlessly using a specific sklearn algorithm without truly knowing why you are using it.
Consequently, you’d know which algorithm to use and, most importantly, why.
This improves your credibility as a data scientist and allows you to approach data science problems with intuition and clarity rather than hit-and-trial.
Hope you learned something new.
👉 If yes, then don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Sponsor the Daily Dose of Data Science Newsletter. More info here: Sponsorship details.
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
what about predicting the price of a home? what distribution would you consider there?
Thanks. You explain it so well.