
The Motivation Behind Using KernelPCA over PCA for Dimensionality Reduction
...and when to not use KernelPCA.

Before we begin…
Today is a special day as this newsletter has completed 500 days of serving its readers.
It started on 3rd Oct 2022, and it’s unbelievable that we have come so far. Thanks so much for your consistent readership and support.

Today, I am offering a limited-time discount of 50% off on full memberships.
If you have ever wanted to join, this will be the perfect time, as this discount will end in the next 36 hours.
Join here or click the button below to join today:
Thanks, and let’s get to today’s post now!
During dimensionality reduction, principal component analysis (PCA) tries to find a low-dimensional linear subspace that the given data conforms to.
For instance, consider the following dummy dataset:

It’s pretty clear from the above visual that there is a linear subspace along which the data could be represented while retaining maximum data variance. This is shown below:

But what if our data conforms to a low-dimensional yet non-linear subspace.
For instance, consider the following dataset:

Do you see a low-dimensional non-linear subspace along which our data could be represented?
No?
Don’t worry. Let me show you!
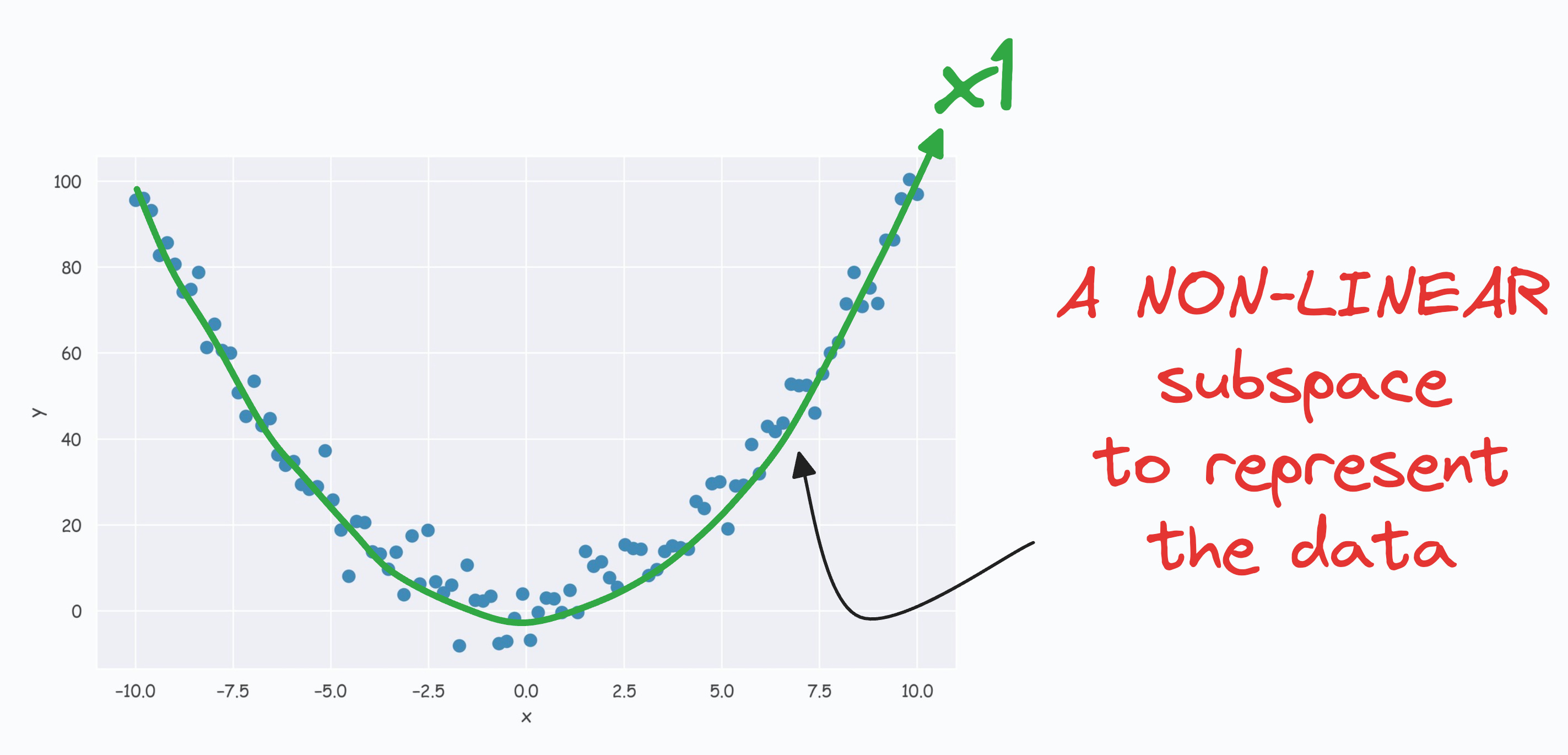
The above curve is a continuous non-linear and low-dimensional subspace that we could represent our data given along.
Okay…so why don’t we do it then?
The problem is that PCA cannot determine this subspace because the data points are non-aligned along a straight line.
In other words, PCA is a linear dimensionality reduction technique.
Thus, it falls short in such situations.
Nonetheless, if we consider the above non-linear data, don’t you think there’s still some intuition telling us that this dataset can be reduced to one dimension if we can capture this non-linear curve.

KernelPCA (or the kernel trick) precisely addresses this limitation of PCA.
The idea is pretty simple:
Project the data to another high-dimensional space using a kernel function, where the data becomes linearly representable. Sklearn provides a KernelPCA wrapper, supporting many popularly used kernel functions.
Apply the standard PCA algorithm to the transformed data.
The efficacy of KernelPCA over PCA is evident from the demo below.
As shown below, even though the data is non-linear, PCA still produces a linear subspace for projection:

However, KernelPCA produces a non-linear subspace:
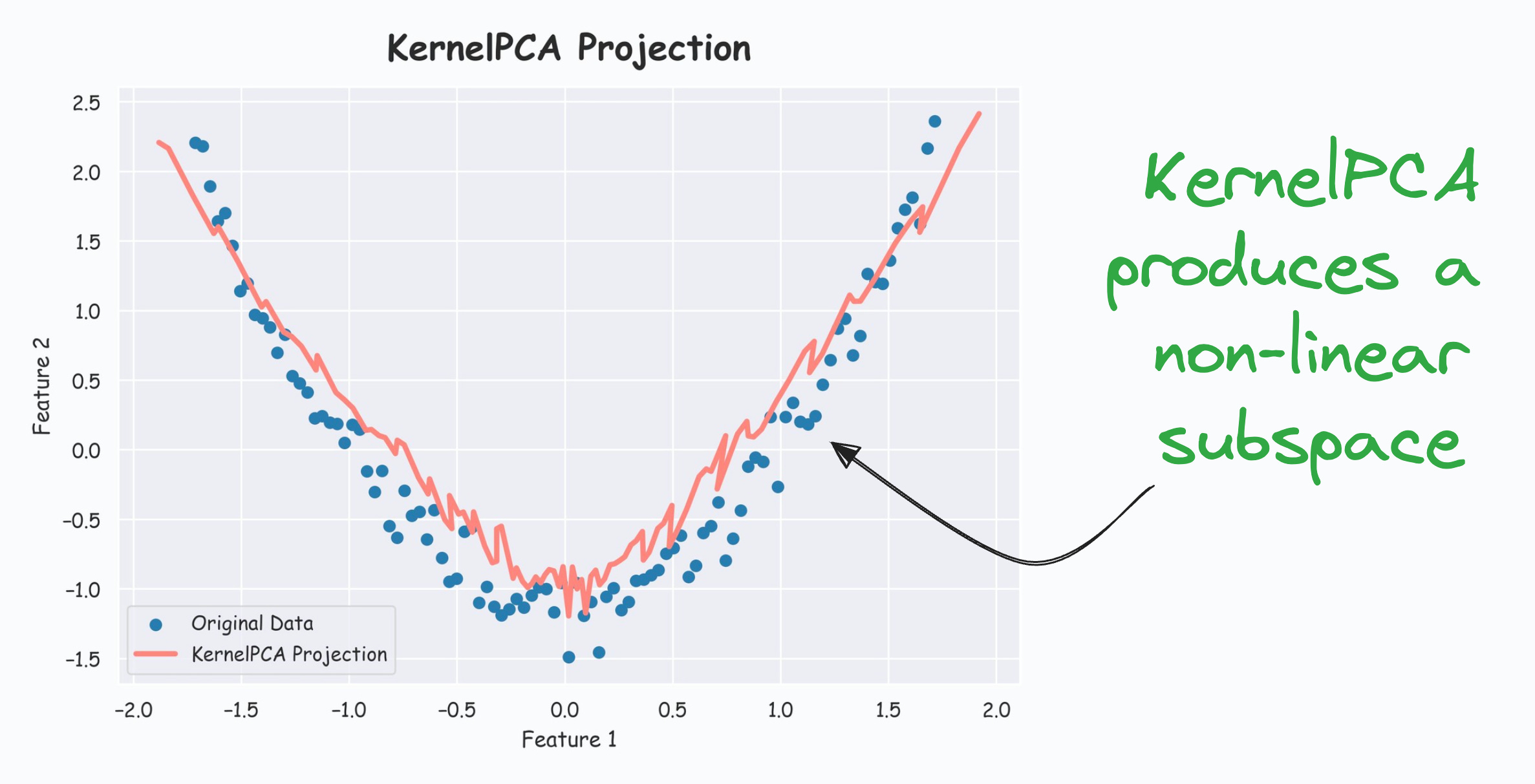
Isn’t that cool?
What’s the catch, you might be wondering?
The catch is the run time.
Please note that the run time of PCA is already cubically related to the number of dimensions.

KernelPCA involves the kernel trick, which is quadratically related to the number of data points (n).
Thus, it increases the overall run time.
This is something to be aware of when using KernelPCA.
👉 Over to you: What are some other limitations of PCA?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Hi Avi, Thank you for the articles you share. I have a question related to Kernel PCA. Please correct me if my understanding is correct:
For non-linear data in dimension d, to apply PCA, we need to project that data to an even higher dimension d’ to make it linear. Once the data is linear, we use our PCA to reduce the dimensionality from d’ to a dimension less than d.