
The No. 1 Deep Researcher Beats Claude and ChatGPT Using a Counterintuitive Trick
It's fully open-source with 30k stars.

Innovative AI for everyone

Strands Agents, the open source agent harness SDK from AWS gives you a model-driven way to build production-ready agents in just a few lines of code.
Any model, any cloud. You get context management, execution limits, and observability before writing a line of config.
Swap backends when you scale, and your code stays the same.
Hooks let you intercept any step in the agent loop to log, validate, or redirect it. Guardrails catch mistakes before they run.
Build your first agent harness →
Thanks to Amazon Web Services (AWS) for partnering today!
The No. 1 Deep Researcher Beats Claude and ChatGPT Using a Counterintuitive Trick
The No. 1 deep researcher beats Claude and ChatGPT with a trick neither uses.
We studied the open-source architecture behind it.
A counterintuitive thing we found is that the orchestrator agent that runs the entire research strategy has no search access.
It can’t query the web or open URLs.
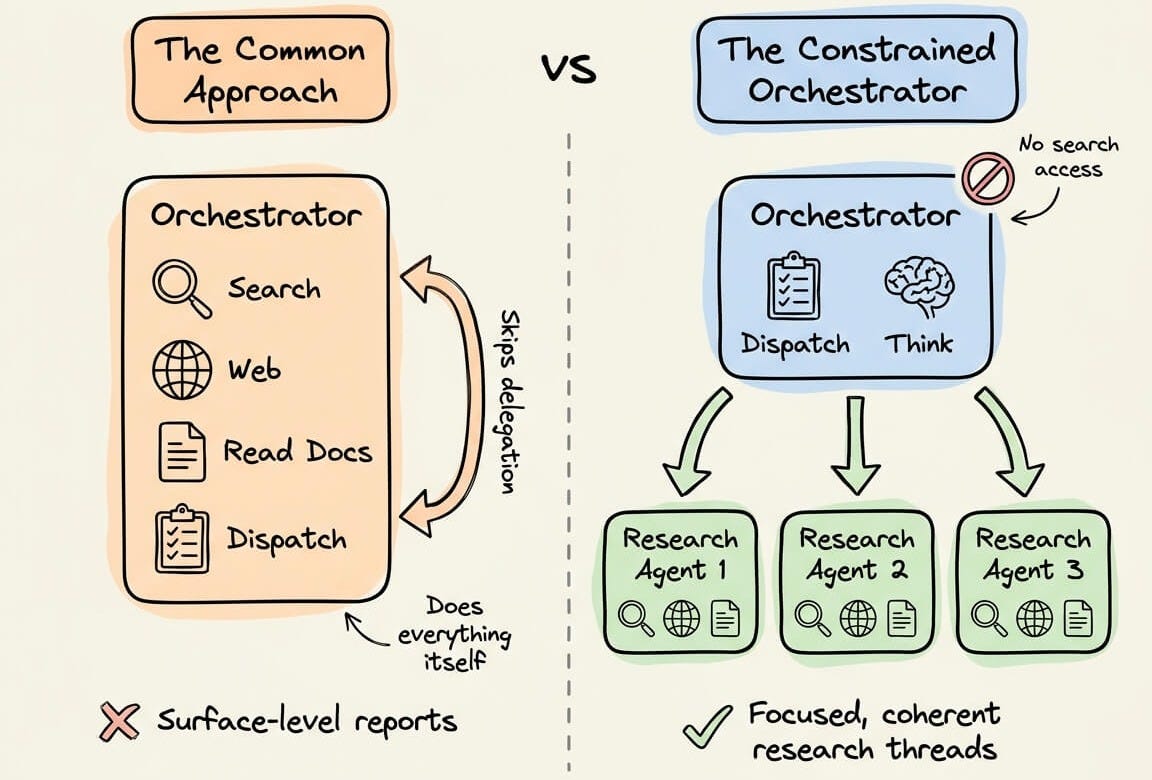
This looks wrong at first glance. Every other deep research system gives its coordinator far more capability.
For instance:
OpenAI’s approach trains a single model for many consecutive tool calls. It searches, reads, reasons, and writes the report in a long sequential chain.
↳ The researchers behind the No. 1 system (Onyx; GitHub Repo) observed that this causes the model to spend cycles on low-value searches instead of maintaining a high-level research strategy.
Anthropic and Google use an orchestrator-researcher pattern similar to Onyx’s system. The key difference is how aggressively Onyx constrains the orchestrator.
Most orchestrators have access to search and retrieval tools alongside dispatch capabilities. And the moment an orchestrator can search, it will.
So instead of decomposing a query into focused research threads, it starts answering the question itself.
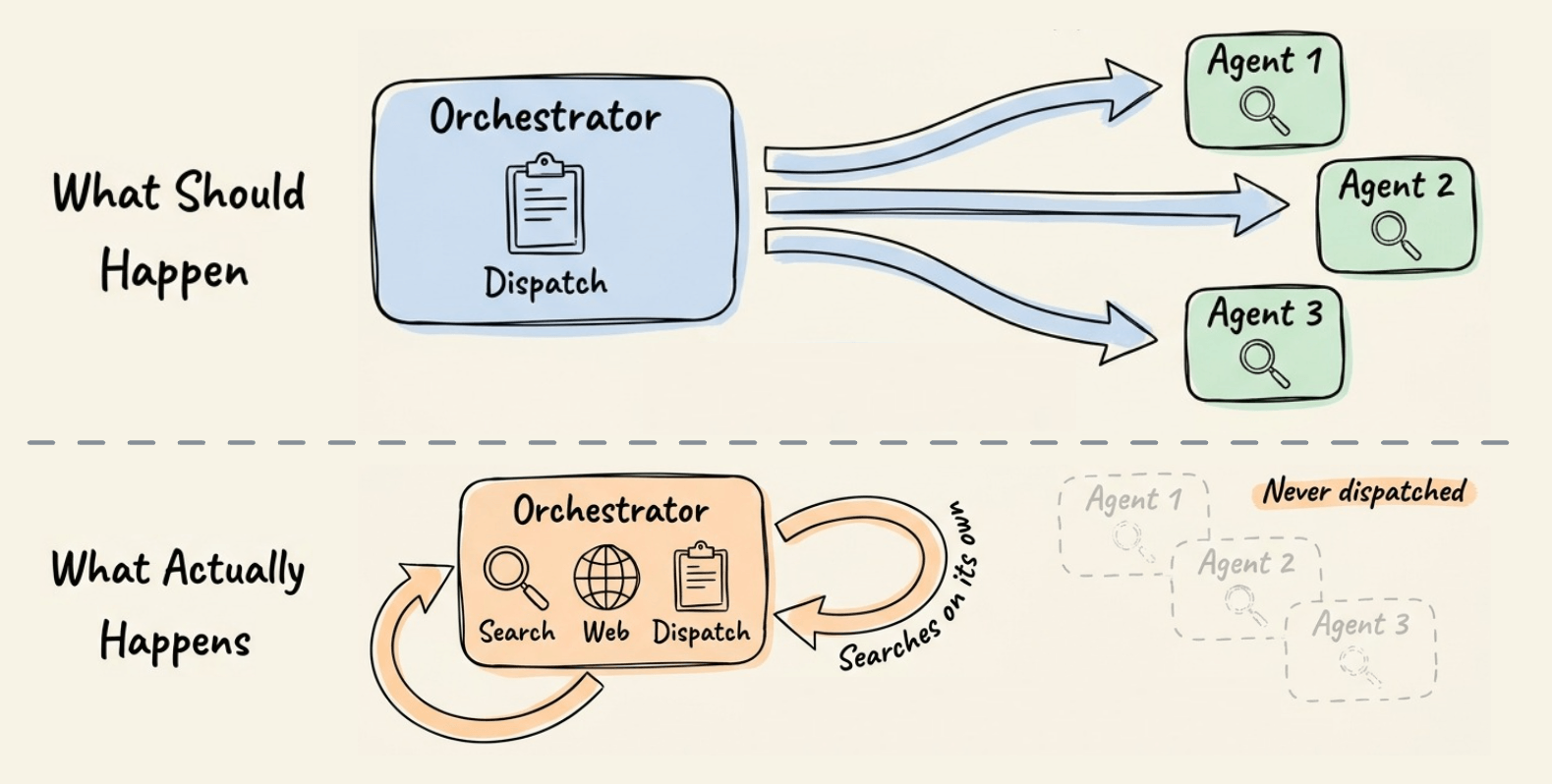
It pulls a few results, skips proper task decomposition, and produces a surface-level report from whatever it found first.
Stripping search from the orchestrator forces it to write self-contained and coherent task briefs for each research agent.
The researchers also kept the architecture only two levels deep. When info passes through multiple agents, each one subtly distorts it through summarization/reinterpretation. Keeping it to two levels prevents this.
These two constraints sit inside a larger three-phase pipeline (the visual below maps this):
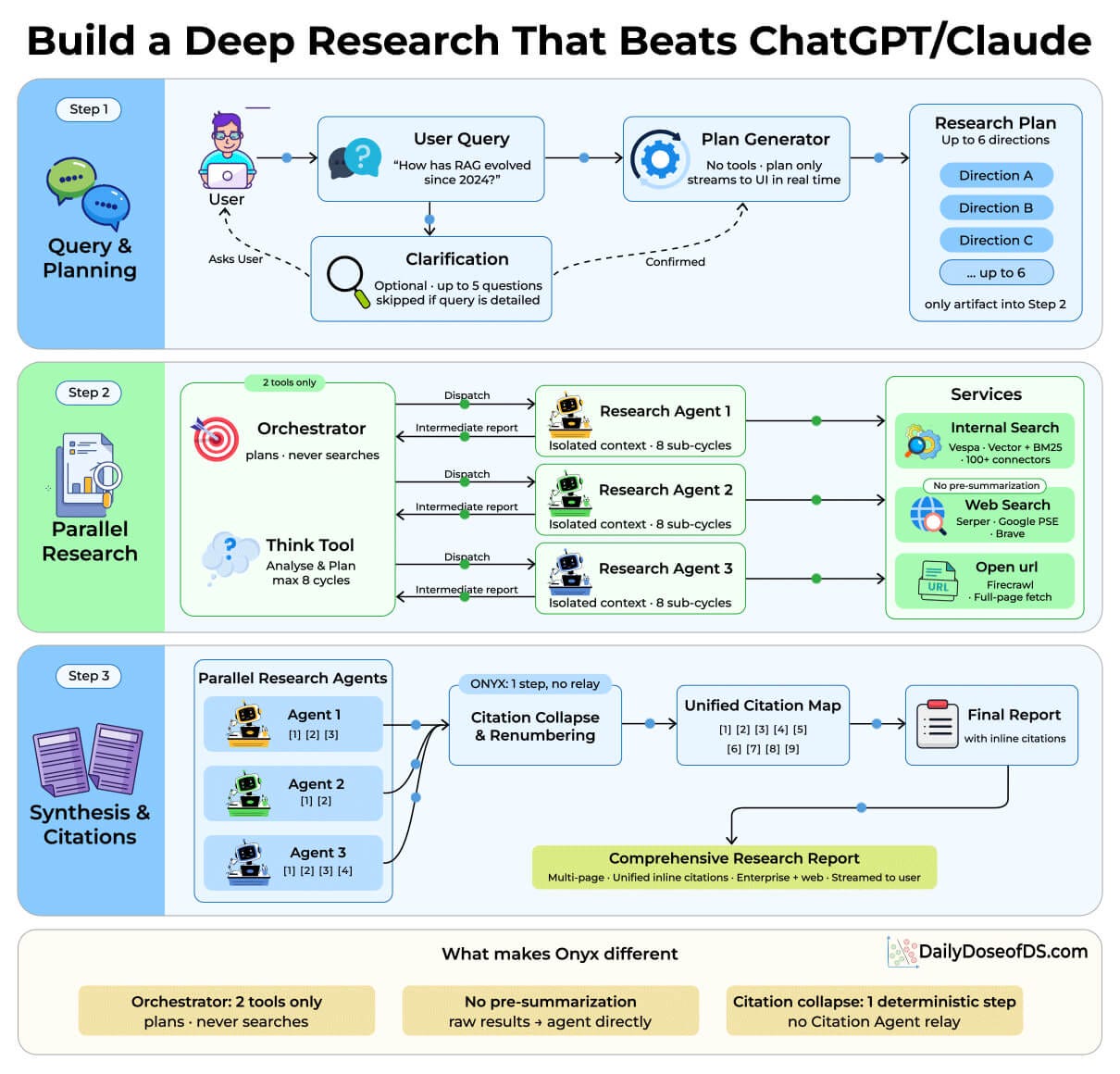
Phase 1 decomposes the query into up to 6 research directions. No tool access prevents the model from prematurely answering.
Phase 2 dispatches 3 isolated research agents. Each runs up to 8 sub-cycles of search, read, and think, to produce an intermediate report with citations. The agents can also search internal enterprise docs (Confluence, Slack, 100+ connectors) with document-level permissions enforced, unlike proprietary solutions.
Phase 3 runs a deterministic step that renumbers and deduplicates to produce a report with a unified citation map.
This pattern has been ranked No. 1 on DeepResearch Bench. The whole implementation is available on GitHub, and you can try it yourself.
Here’s the Onyx Repo → (don’t forget to star it ⭐ )
👉 Over to you: Which one is your go-to deep researcher right now?
Thanks for reading!
Hey Avi, thanks for the post! One question: What's the difference between the Constrained Orchestrator and a forked LLM Council where one AI acts over the loop as team leader (who isn't allowed to research themselves) and sends off the other AIs to do independent research before convening thesis defense style?