
The No-code Data Science Tool Stack
8 powerful no-code data science tools in a single frame.

I am a big fan of no-code tools. They are extremely useful in eliminating repetitive code across projects—thereby boosting productivity.
The below visual depicts 8 powerful (and my favorite) no-code tools for data science tasks:
They automate many redundant steps in data science projects and help you perform data science tasks without any code.
Let’s discuss them one by one.
Gigasheet:

Browser-based no-code tool to analyze data at scale.
Use AI to conduct data analysis
It’s like a combination of Excel + Pandas with no scale limitations.
You can analyze datasets as large as 1B rows.
Get started: Gigasheet.
Mito:

Create a spreadsheet interface in Jupyter Notebook.
Use Mito AI to conduct data analysis.
Automatically generates Python code for each analysis
Get started: Mitosheet.
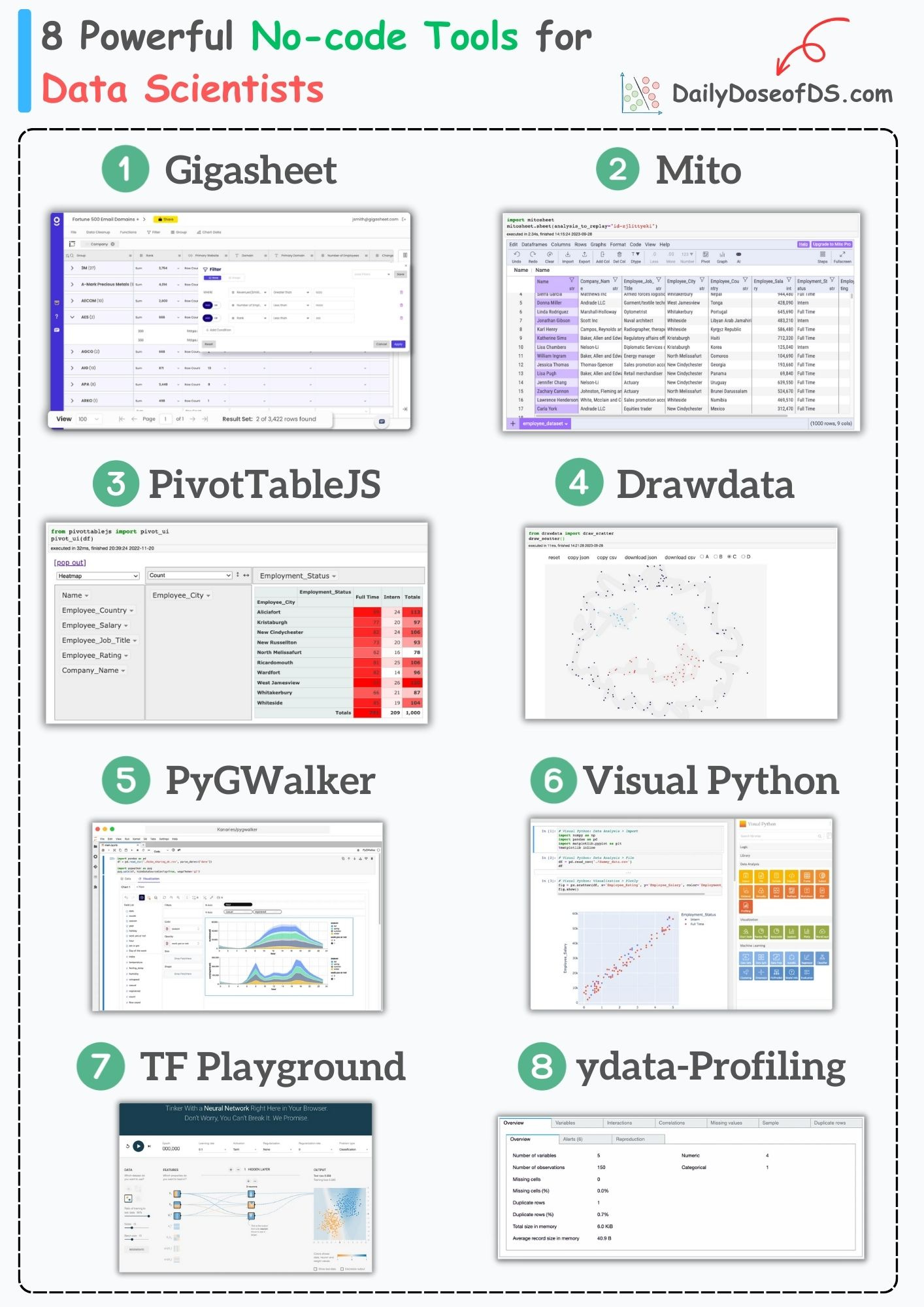
PivotTableJS:
Create Pivot tables, aggregations, and charts using drag-and-drop.
Add heatmaps to tables.
Works within Jupyter Notebook.
Get started: PivotTableJS.
Drawdata:

Draw any 2D scatter dataset by dragging the mouse.
Export the data as DataFrame, CSV, or JSON.
Create a histogram and line plot by dragging the mouse.
Get started: Drawdata.
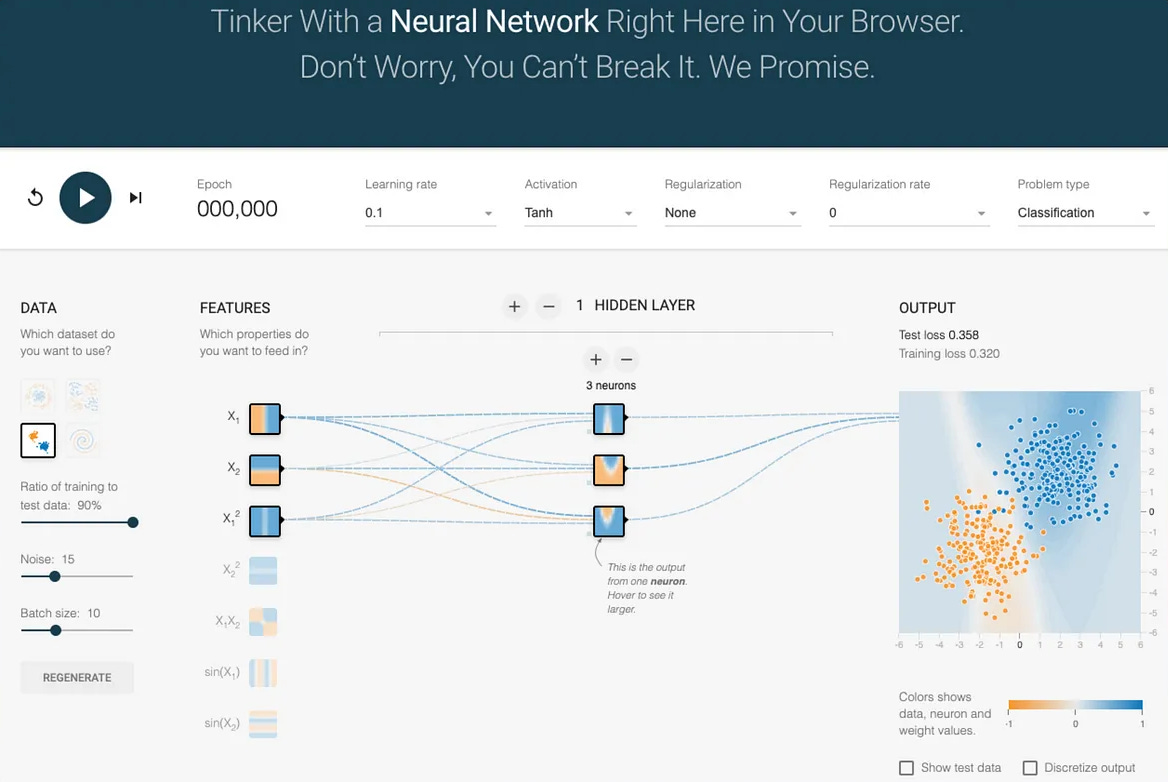
PyGWalker:

Open a tableau-style interface in Jupyter notebook
Analyze a DataFrame as you would in Tableau.
Get started: PyGWalker.
Visual Python:

A GUI-based Python code generator.
Import libraries, perform data I/O, create plots, write code for ML models, etc. by clicking buttons.
Get started: Visual Python.
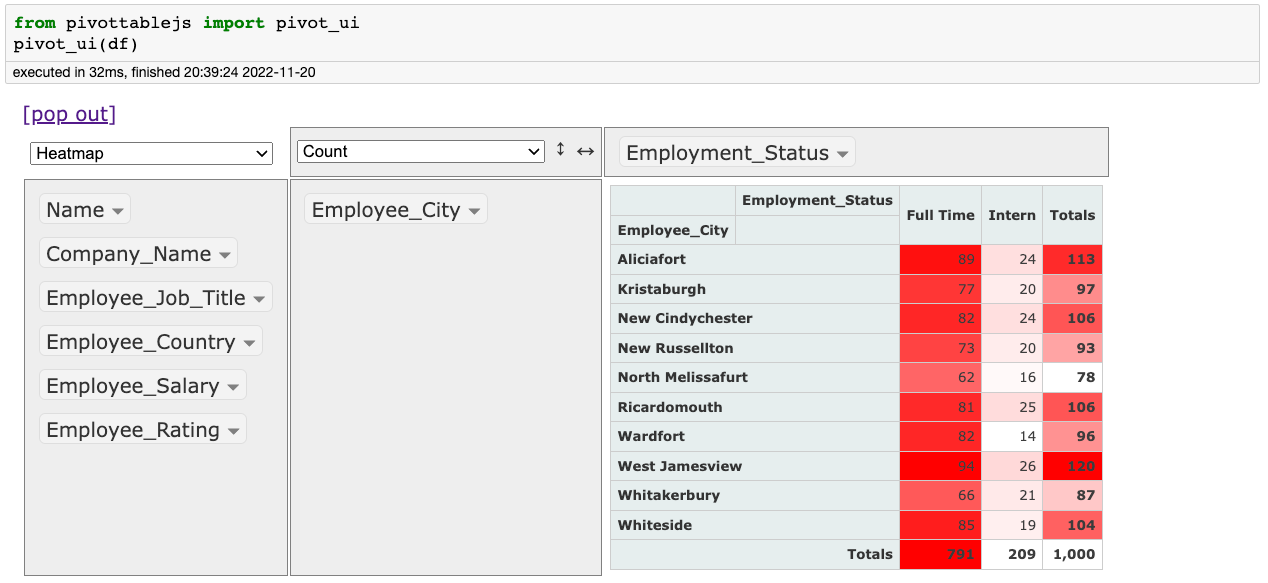
Tensorflow Playground:
Of course, this is not an entirely DS-oriented tool, but many can use it to build a better understanding of neural networks. Provides an elegant UI to build, train, and visualize neural networks.
Browser-based tool.
Change data, model architecture, hyperparameters, etc., by clicking buttons.
Get started: Tensorflow Playground.
ydata-profiling:

Generate a standardized EDA report for your dataset.
Works in a Jupyter notebook
Covers info about missing values, data statistics, correlation, data interactions, etc.
Get started: ydata-profiling.







👉 Over to you: Have I missed any other cool data science no-code tools?
Whenever you are ready, here’s one more way I can help you:
Every week, I publish 1-2 in-depth deep dives (typically 20+ mins long). Here are some of the latest ones that you will surely like:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)