
The Open-source RAG Stack
...for production use cases.

Build reliable agents powered by trusted APIs!

Robust and properly tested tools are the key to building powerful agents. Otherwise, an Agent likely holds no practical value.
We have been testing the Postman’s AI Agent Builder (it’s free), which lets you build fully operational and tested Agents faster.
Here’s how:
It provides a no-code visual canvas for building multi-step agent workflows.
It has APIs from 18,000+ companies that can be integrated in a few clicks as an MCP server.
It provides features to compare responses, costs, and performance.
It connects to most top providers like OpenAI, Anthropic, etc.
We will share more hands-on guides on this soon as we test more.
In the meantime, you can try it here →
Thanks to Postman for partnering on today’s issue!
The open-source RAG stack for production use cases
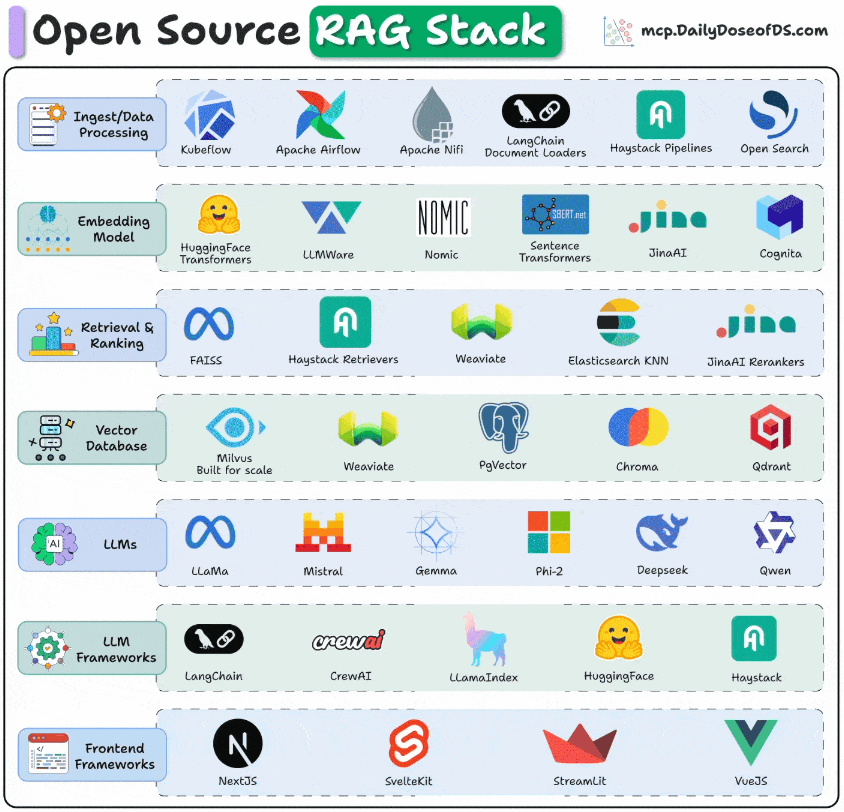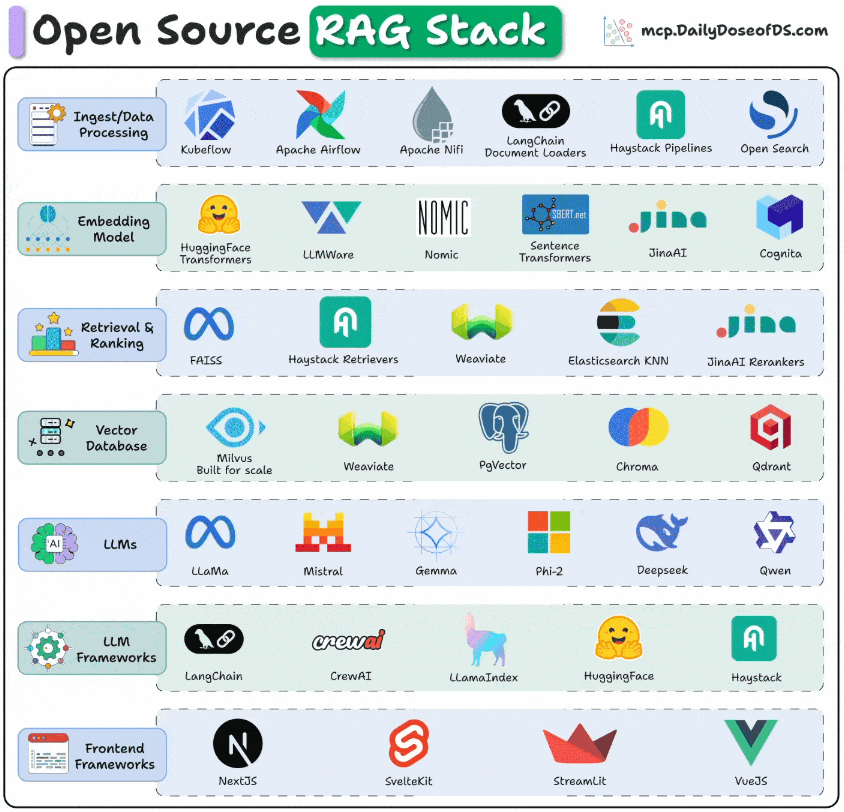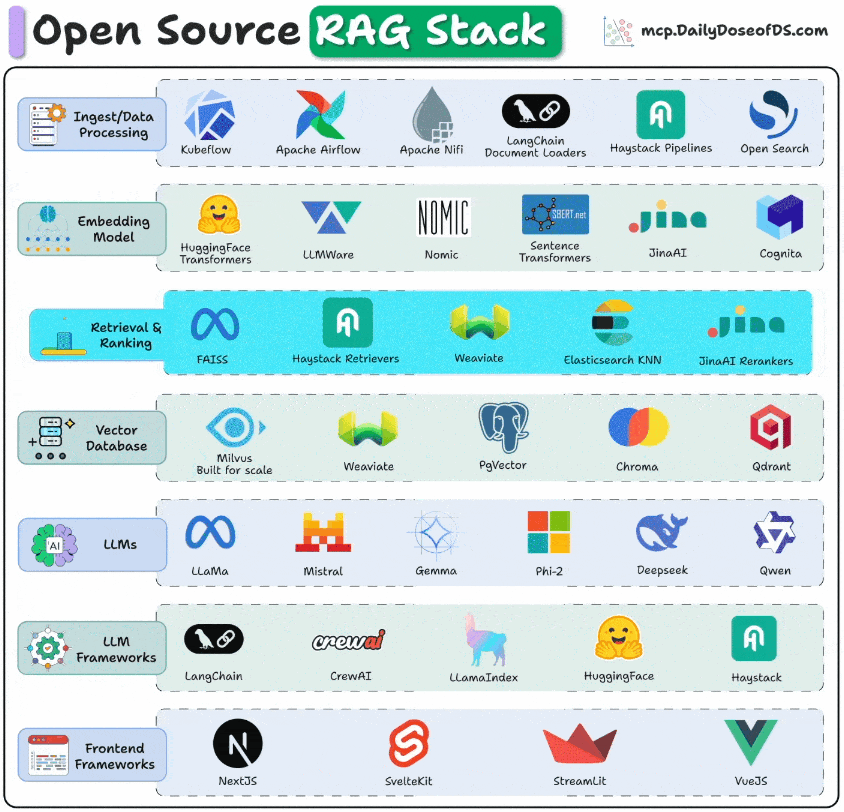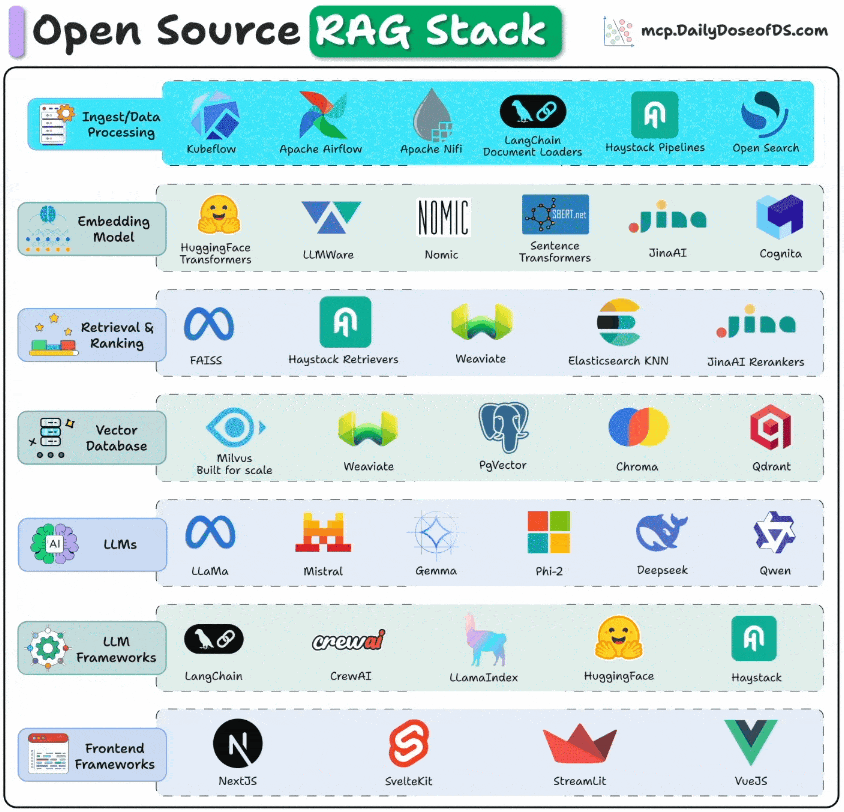
To get production-grade retrieval-augmented generation right, you need to think in layers.
Each layer solves a very specific problem, starting from how data is ingested all the way to how users interact with your app.
The visual below depicts the stack you can use for these key layers to build RAG systems for production.
Frontend frameworks: This is the entry point for users. Frameworks like NextJS, Streamlit, VueJS, etc., are used to build clean UIs.
LLM frameworks for orchestration: This stack connects models, tools, and workflows. LangChain, CrewAI, LlamaIndex, Haystack, and Semantic Kernel manage orchestration.
LLMs: This is the brain or the reasoning engine of the app. Options like Llama, Mistral, Gemma, DeepSeek, Qwen, and Phi-2 bring open-source flexibility.
Retrieval & Ranking: LLM's output is only as good as the context you feed in, while also ensuring you maintain minimal latency. FAISS, Milvus, and Weaviate can help you get the right chunks, while rerankers like JinaAI fine-tune relevance.
Vector databases: This is where you store the vector embedding. Milvus, Chroma, Weaviate, and pgVector power fast similarity search at scale.
Embedding models: The embeddings stored in the vector DB above come from these models. They convert raw text into a list of numbers that capture similarity. Several options are available here, like SentenceTransformers, HuggingFace Transformers, JinaAI, Nomic, etc. MongoDB's voyage-context-3 is not open-source, but it delivers an incredible performance based on my testing. 512d binary quantized embedding outperform 3072d float32 embeddings from OpenAI v3 large.
Ingest & data processing: This is how you get the data into your workflow. Tools like Kubeflow, Airflow, LangChain loaders, and Haystack pipelines help you build them.
If you want to dive into building LLM apps, our full RAG crash course discusses RAG from basics to beyond:
👉 Over to you: What popular open-source stack did we miss?
9 MCP projects for AI Engineers
We have covered several MCP projects in this newsletter so far.
Here’s a recap along with visuals & full code walk-through issues:
#1) 100% local MCP client
An MCP client is a component in an AI app (like Cursor) that establishes connections to external tools. Learn how to build it 100% locally.
#2) MCP-powered Agentic RAG
Learn how to create an MCP-powered Agentic RAG that searches a vector database and falls back to web search if needed.
#3) MCP-powered financial analyst
Build an MCP-powered AI agent that fetches, analyzes & generates insights on stock market trends, right from Cursor or Claude Desktop.
#4) MCP-powered Voice Agent
This project teaches you how to build an MCP-driven voice Agent that queries a database and falls back to web search if needed.
#5) A unified MCP server
This project builds an MCP server to query and chat with over 200+ data sources using natural language through a unified interface powered by MindsDB and Cursor IDE.
#6) MCP-powered shared memory for Claude Desktop and Cursor
Devs use Claude Desktop and Cursor independently with no context sharing. Learn how to add a common memory layer to cross-operate without losing context.
#7) MCP-powered RAG over complex docs
Learn how to use MCP to power an RAG app over complex documents with tables, charts, images, complex layouts, and whatnot.
#8) MCP-powered synthetic data generator
Learn how to build an MCP server that can generate any type of synthetic dataset. It uses Cursor as the MCP host and SDV to generate realistic tabular synthetic data.
#9) MCP-powered deep researcher
ChatGPT has a deep research feature. It helps you get detailed insights on any topic. Learn how you can build a 100% local alternative to it.
👉 Over to you: What other MCP projects would you like to learn about?
Thanks for reading!