
The Probe Method: A Reliable and Intuitive Feature Selection Technique
Introduce a bad feature to remove other bad features.

Real-world ML development is all about achieving a sweet balance between speed, model size, and performance.
One common way to:
Improve speed,
Reduce size, and
Maintain (or minimally degrade) performance…
…is by using featuring selection.
As the name suggests, the idea is to select the most useful subset of features from the dataset.

Here, I have often found the “Probe Method” to be pretty reliable and practical.
The animation below depicts how it works:
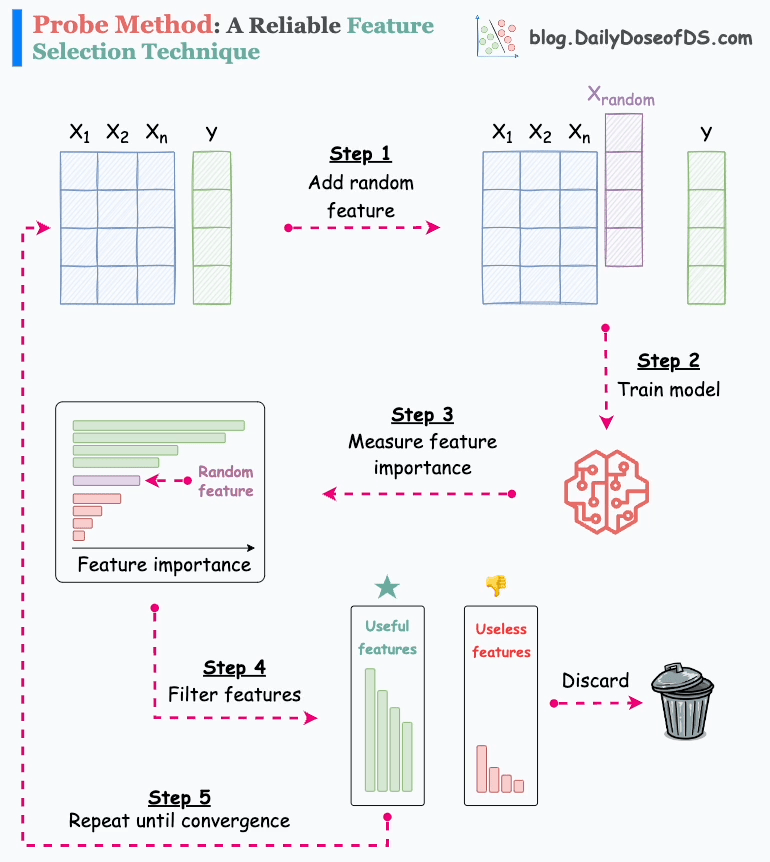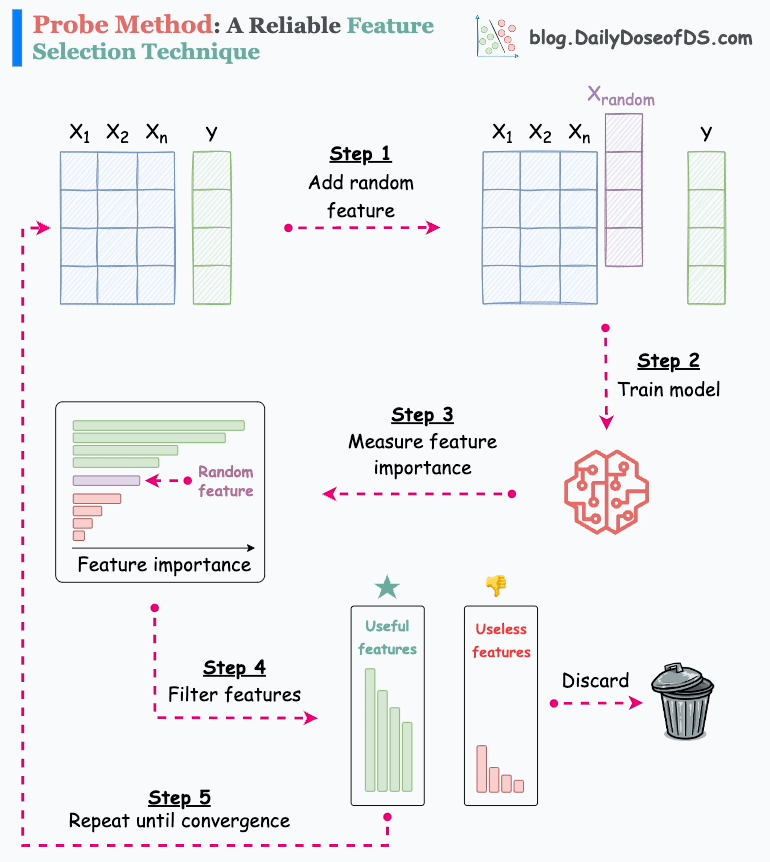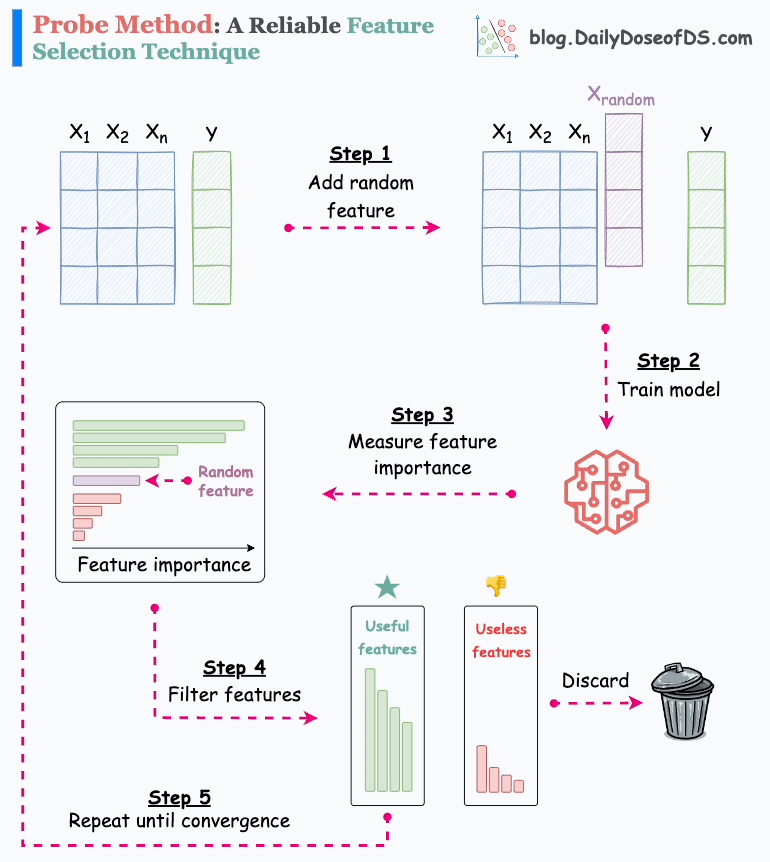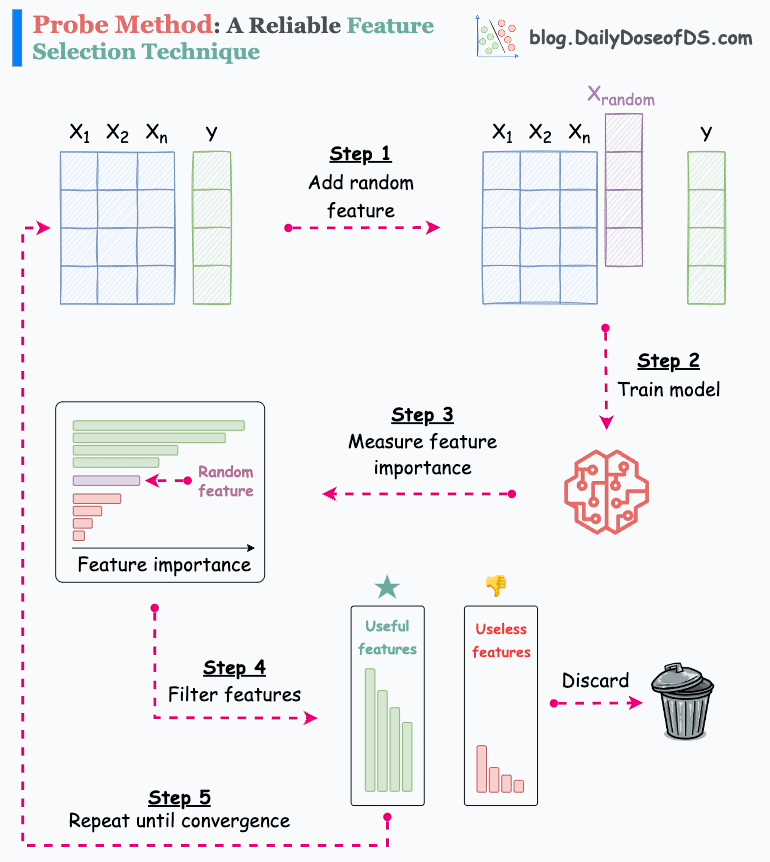
Step 1) Add a random feature (noise).
Step 2) Train a model on the new dataset.
Step 3) Measure feature importance.
Step 4) Discard original features that rank below the random feature.
Step 5) Repeat until convergence.
This makes intuitive sense as well.
If a feature’s importance is ranked below a random feature, it is possibly a useless feature for the model.
This can be especially useful in cases where we have plenty of features and we wish to discard those that don’t contribute to the model.
Of course, one shortcoming is that when using the Probe Method, we must train multiple models:
Train the first model with the random feature and discard useless features.
Keep training new models until the random feature is ranked as the least important feature (although typically, convergence does not result in plenty of models).
Train the final model without the random feature.
Nonetheless, the approach can be quite useful to reduce model complexity.
Once done, you can further reduce the model size by using model compression techniques, which we discussed here: Model Compression: A Critical Step Towards Efficient Machine Learning.
👉 Over to you: What are some other popular feature selection techniques?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
As always, thanks for reading :)
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Where Did The Assumptions of Linear Regression Originate From?
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
There is a chance (however small) that the random feature will have moderate or high importance and cause us to drop useful features. I would want to run the process 100+ times and drop the features that are identified the most often. But this would require many model fits. Overall, I would prefer to calculate the permutation importances once and see if there's a clear threshold for features worth keeping.
Thank you for this post. How do you draw these nice animated arrows? Is there a library for exaclidraw or do you use any other tool?