
The Probe Method: An Intuitive Feature Selection Technique
Introduce a bad feature to remove other bad features.

Real-world ML development is all about achieving a sweet balance between speed, model size, and performance.
We also saw this when we learned about different model compression techniques.
One common way to:
Improve speed,
Reduce size, and
Maintain (or minimally degrade) performance…
…is by using featuring selection.
As the name suggests, the idea is to select the most useful subset of features from the dataset.

While there are many many methods for feature selection, I have often found the “Probe Method” to be pretty reliable, practical and intuitive to use.
The animation below depicts how it works:
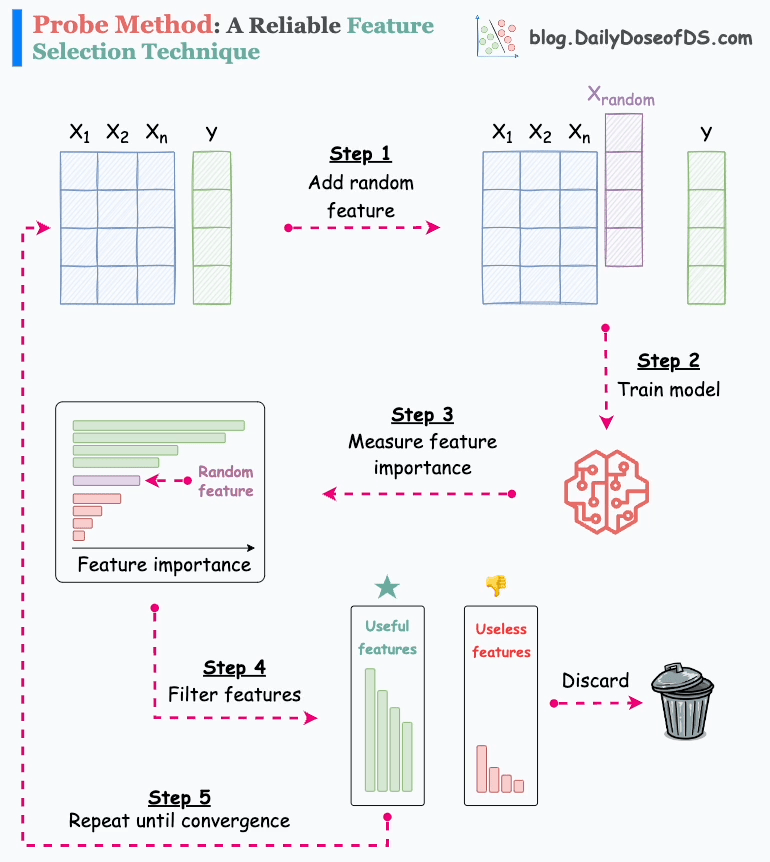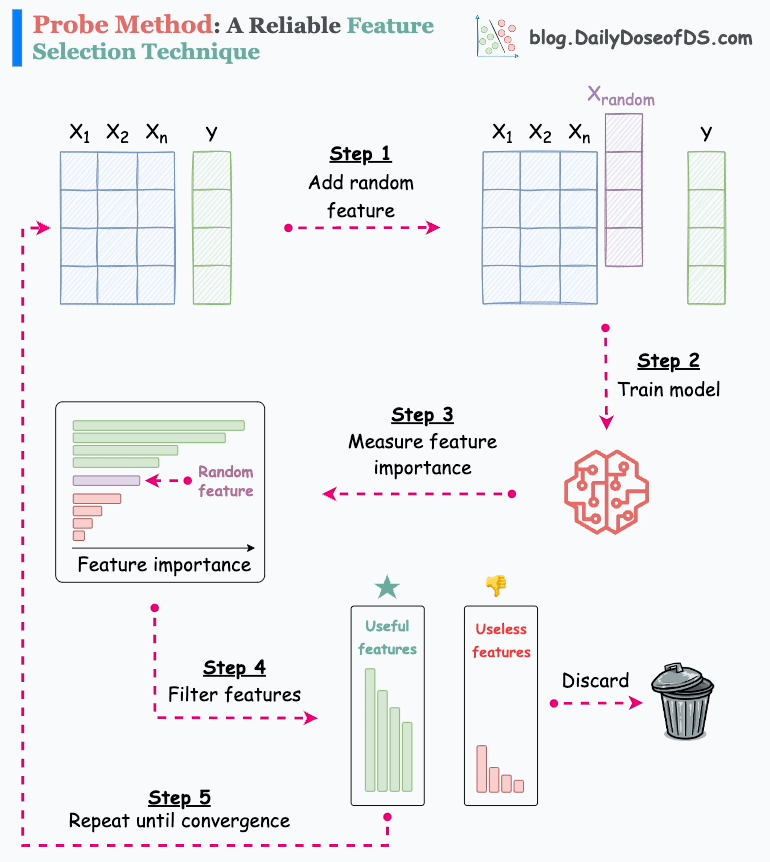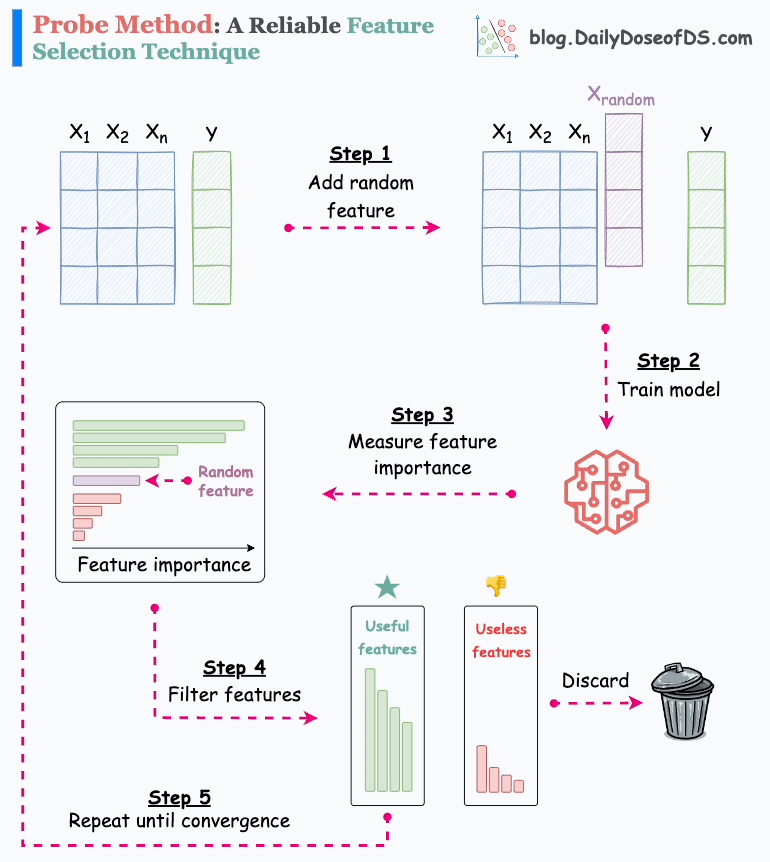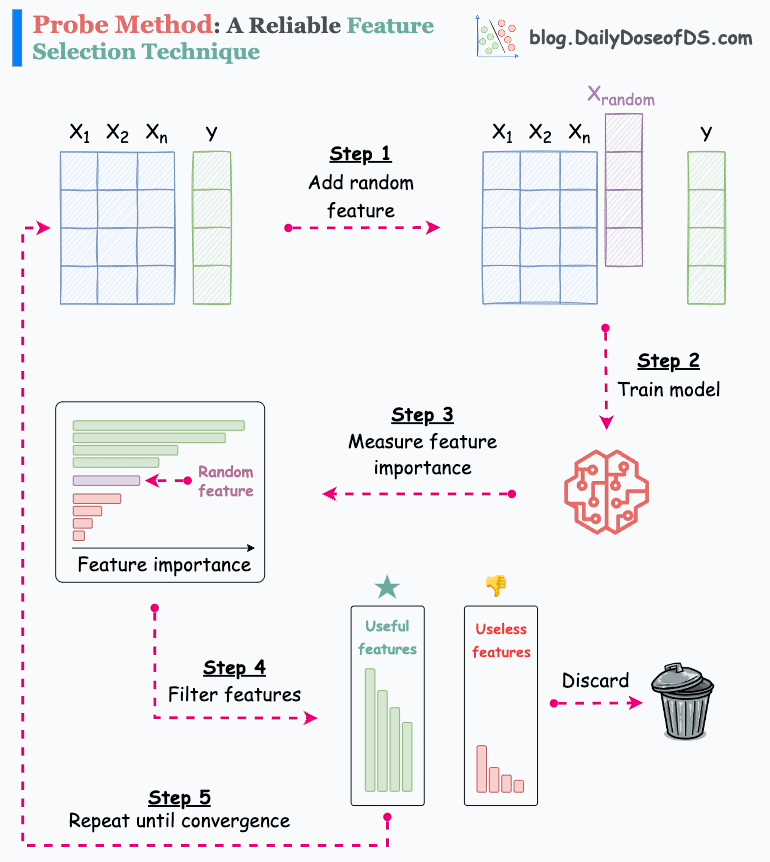
Step 1) Add a random feature (noise).
Step 2) Train a model on the new dataset.
Step 3) Measure feature importance.
Step 4) Discard original features that rank below the random feature.
Step 5) Repeat until convergence.
This whole idea makes intuitive sense as well.
More specifically, if a feature’s importance is ranked below a random feature, it is probably a useless feature for the model.
This can be especially useful in cases where we have plenty of features, and we wish to discard those that don’t contribute to the model.
Of course, one shortcoming is that when using the Probe Method, we must train multiple models:
Train the first model with the random feature and discard useless features.
Keep training new models until the random feature is ranked as the least important feature (although typically, convergence does not result in plenty of models).
Train the final model without the random feature.
Nonetheless, the approach can be quite useful to reduce model complexity.
In fact, after selecting important features, we can further reduce the model size by using model compression techniques, which we discussed here: Model Compression: A Critical Step Towards Efficient Machine Learning.
👉 Over to you: What are some other popular feature selection techniques?
Thanks for reading!
Whenever you are ready, here’s one more way I can help you:
Every week, I publish 1-2 in-depth deep dives (typically 20+ mins long). Here are some of the latest ones that you will surely like:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
A Detailed and Beginner-Friendly Introduction to PyTorch Lightning: The Supercharged PyTorch
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
there is a slightly improved version of the Probe Method.
With the original one there is one problem.
If you have thousand features and you reiterate the Probe Method for a couple of times you'll get different number of useful features. There is some randomness in that process. So you can insert not one but say 3-5 of noise features and drop by the worst of them. It will be the least aggressive and greedy approach possible.
Then repeat, as in the article
What happens if the random feature happens to be a very important feature? Should the engineer make sure that the random feature is far away from some existing feature?