
The Production Harness for AI-Built Apps
...explained with usage.

The production harness for AI-built apps
When an AI agent deletes a production database, the model is almost never the weak link.
This sounds counterintuitive, but the dangerous part is rarely the code the agent writes.
Instead, it is what sits around that code, the access it inherits, and the boundary nobody put in front of it.
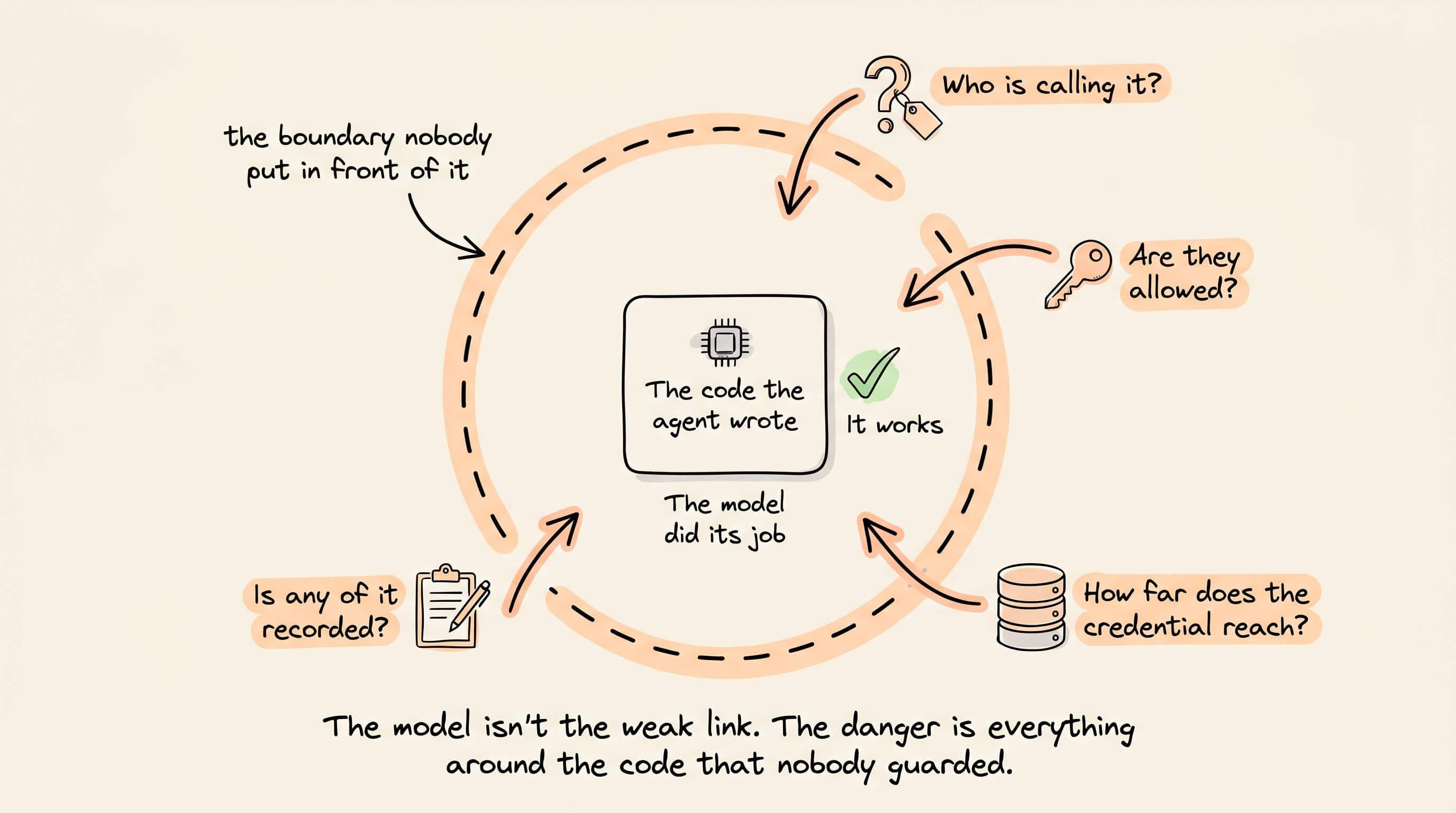
A model will happily generate a button that issues account credits and never question who is allowed to click it, because authorization was never in the prompt.
Today, let’s look at this in action and the solution to avoid this in production!
Our test run
We asked Fable 5 to build a small internal support console with one button that issues an account credit.
It worked on the first run, and on our laptop, the credit was applied to the balance the instant we clicked:
Issuing a credit is an UPDATE against production rows, and it commits real money permanently.
In this case, the agent generated the code end-to-end and stopped. Any caller could reach it, and no role decided whether they were allowed, and nothing was recorded of what they did.
Of course, it built exactly what we asked for. While the model knows well that a button moving money in production needs an access check, it just didn’t add one because the prompt didn’t ask it to.
Why does this happen?
In one widely-reported case, eleven ALL-CAPS warnings not to touch production did not stop an agent from deleting the database.
Instructions live inside the same context that the model is free to override, so they are guidance, not enforcement.
Ideally, these controls should live in the platform the app runs on, not in the app.
Because the moment each app handles its own permissions, you get a hundred tools with a hundred different rules and no central way to manage them. That sprawl is what Shadow AI really means.
The boundary should belong to the runtime where:
Credentials are scoped server-side
Access runs through shared permission groups
And writes are gated and logged centrally.
An agent can’t emit that, because it lives outside the app it builds.
Solution
A smart approach to this is now actually implemented in Retool.

Essentially, instead of asking the model to add the boundary it was never going to add, you can keep building wherever you are fastest (Claude Code, Cursor, Codex, etc) and let the Retool runtime supply the boundary on the way to production.
To demonstrate this, we took the same app from earlier and dropped its React bundle into Retool:
Once done, it parsed the components, pulled them in, and walked us through pointing the app’s data calls at a Retool resource, the governed connection that fronts the real database, everything automatically.
We wrote none of the access control ourselves.
Note: Setup wise, we only signed up for Retool to get production infrastructure for the app. The React code was generated on its own, with no knowledge that Retool would later run it, which is the most important point here.
Nothing in the build was written for Retool, and it still imported cleanly.
That said, there’s a Retool MCP server if you’d rather have the runtime guide the build from inside your coding agent, but we didn’t use it here. The import worked on a plain, Retool-unaware bundle.
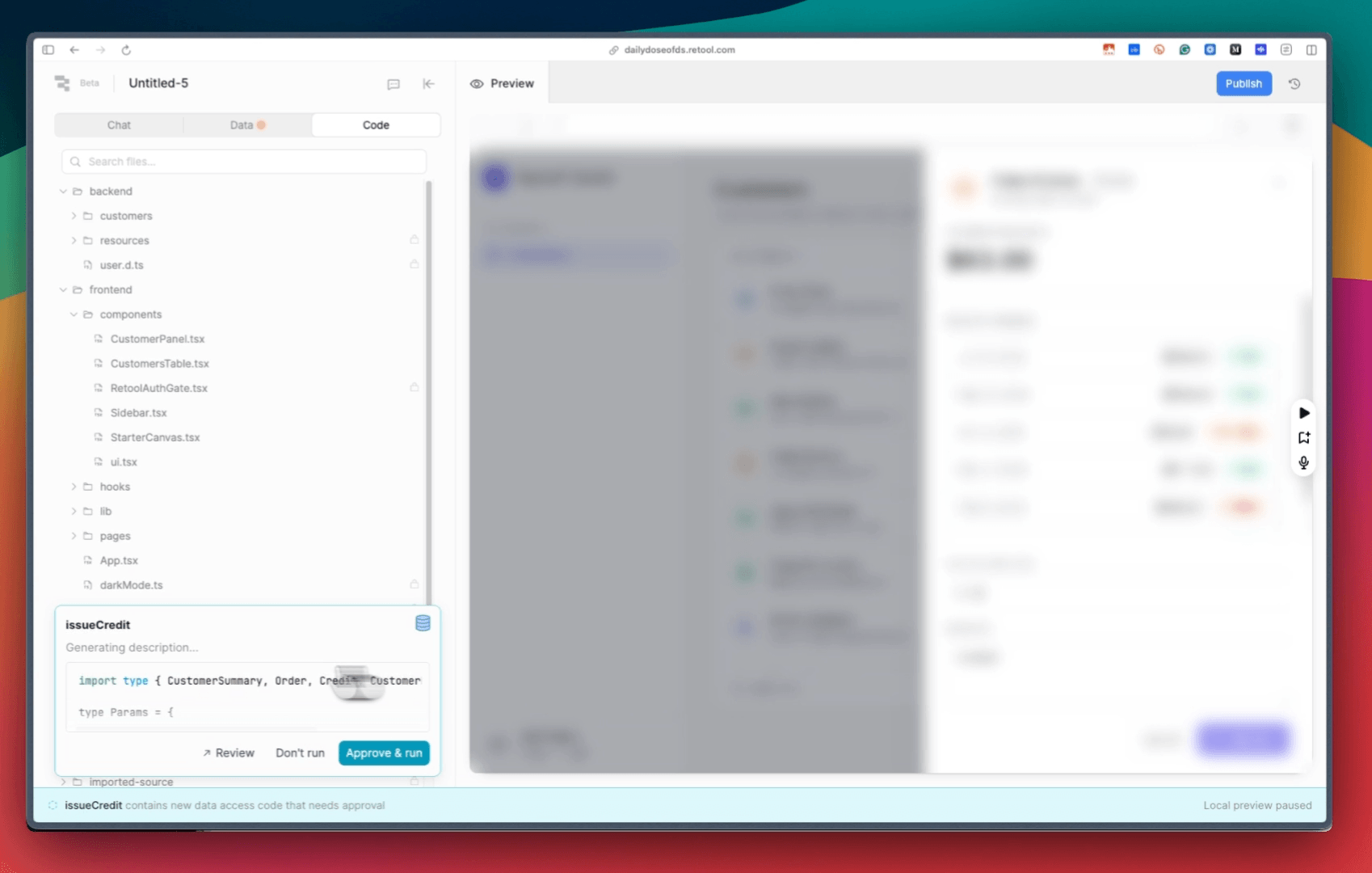
The moment those data calls ran through the resource, the app inherited identity, permissions, and an audit trail from the runtime.
As depicted in the video above, the credit call was now routed through the resource layer.
Moreover, SSO resolved the caller to a real identity. And permission groups decided whether their role can issue credit.
The mutating query trips an approval gate that is on by default, so the write waits for a human instead of committing silently. Each run lands in an audit log with a name and a timestamp.
Nothing in the app changed. It’s the same credit button with the same function behind it. What changed is that the write now runs through Retool’s boundary.
The model makes writing the code almost free.
It does almost nothing for the identity, permissions, and audit trail that make that code safe to run in production, because those come from where the app runs, not from the model.
With Retool, you can build the app anywhere you like and push it to Retool’s runtime to make it safe to ship. None of this slows down the building process.
You can try it out yourself here →
Thanks to Retool for partnering with us today!
HarnessX: A harness that compiles itself
Every harness improvement so far has come from a human editing code by hand.
Anthropic strips planning steps out of Claude Code when a stronger model ships. Manus rebuilt its agent five times in six months, removing complexity each round.
The entire engineering runs on human judgment about what to change and when. HarnessX is a way that allows the system to make those edits itself:
The trick is to treat the harness as a first-class object, the way we already treat model weights.
Once it’s a typed, editable artifact, it can be optimized from its own execution traces.
And evolving a harness maps cleanly onto reinforcement learning.
The harness is the state.
An edit is the action.
The trace plus a score is the feedback.
A new version is the update.
Once you see it that way, the failure modes also become easily evident, like reward hacking, catastrophic forgetting, and under-exploration.
And they are the same problems that break model training, showing up the moment a system starts editing its own scaffolding.
But the good thing is that because the failure modes are known ahead of time, the defenses are part of the design rather than patches added later.
Every edit goes through a loop before it is applied:
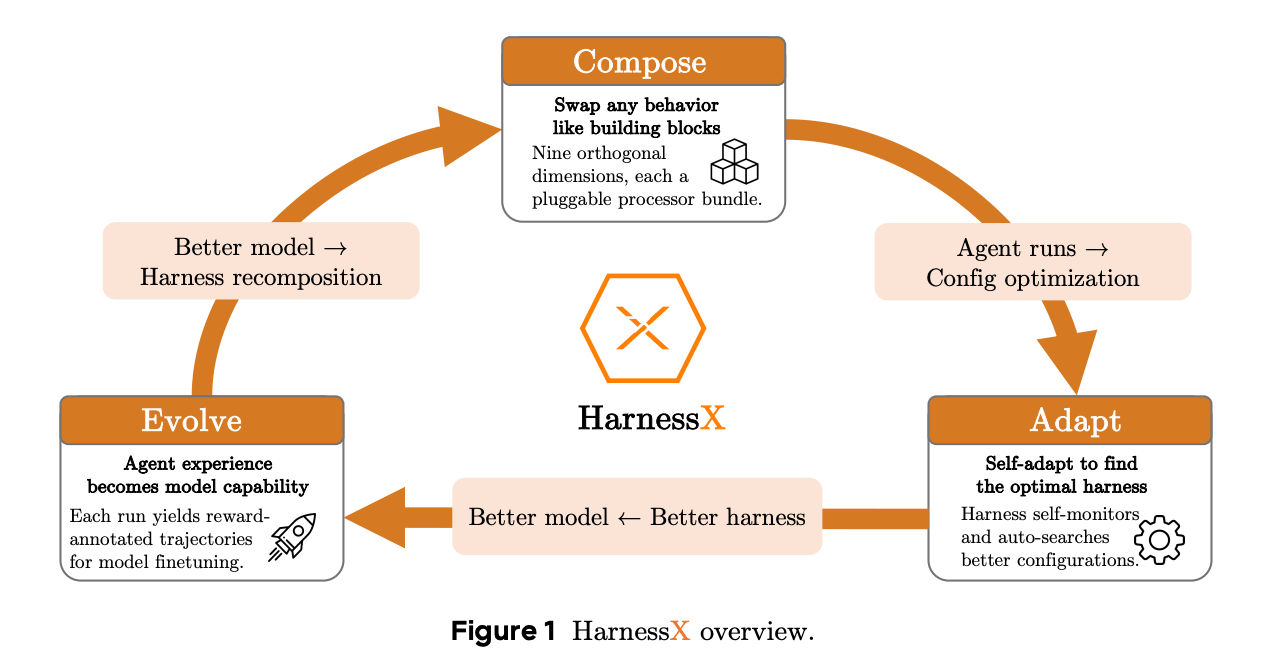
One stage compresses the execution traces into a specific failure.
The next plans a single change.
The third writes the edit.
The fourth runs it and checks the result.
A deterministic gate decides what should persist, so a new version replaces the current one only if it scores higher on the evaluation set; otherwise, it is dropped and the loop reruns.
This self-editing process only works because of how the harness is built. It is composed of typed processors that attach at fixed points in the execution lifecycle, so the system can replace one without breaking the others.
That is why we mentioned “A harness that compiles itself” in the title.
Since every candidate is type-checked before it runs, a malformed edit fails at assembly instead of mid-task.
Across five benchmarks and three model families, evolved harnesses gained 14.5% on average. The gains scaled inversely with baseline strength.
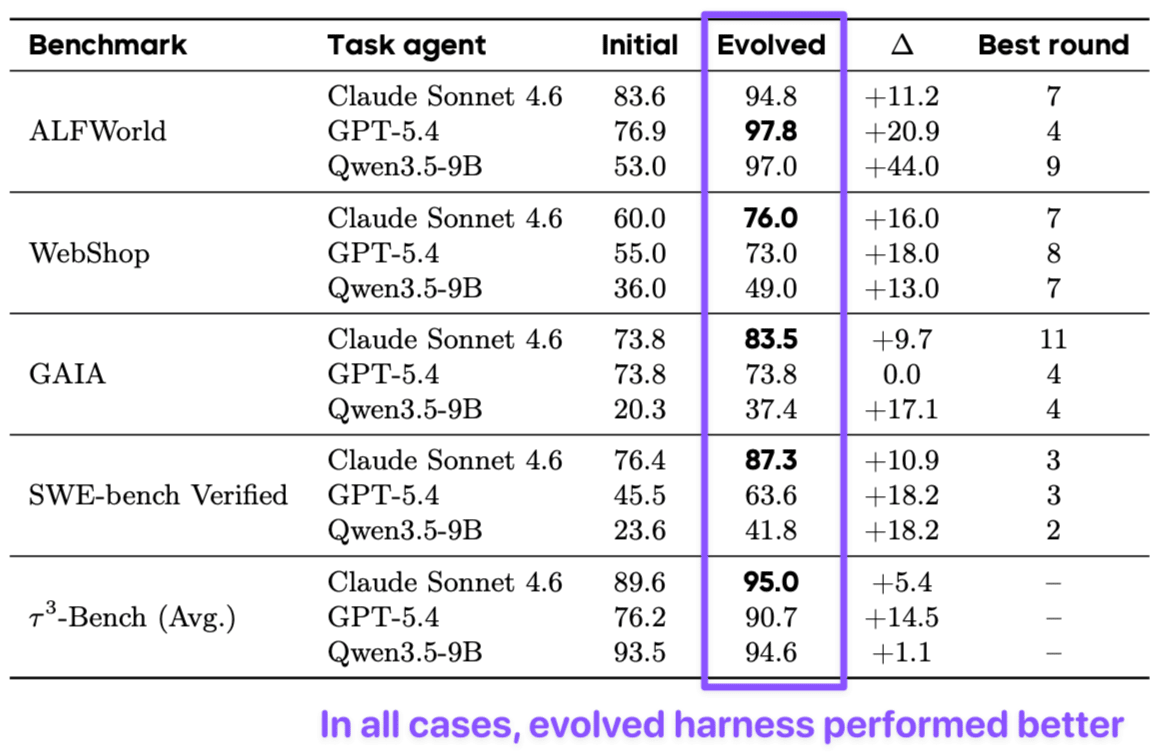
On ALFWorld, the weakest agent improved by 44%. The same evolution moved a stronger model 11%, and a near-ceiling benchmark moved 1.1%.
An evolved harness recovers behavior that a weak model cannot produce on its own. The weights are fixed throughout. Only the harness changes.
This is the next phase of harness engineering. The field moved from weights to context, to hand-built harnesses, and the harness was the last component still edited by hand.
In case you missed it, we wrote a deep dive on agent harness engineering a while back, covering the orchestration loop, tools, memory, context management, and everything that turns a stateless LLM into a capable agent.
And you can read the HarnessX paper here →
Multi-head attention in Transformers
Before Transformers, models struggled to understand context. Multi-Head Attention changed everything.
How it works:
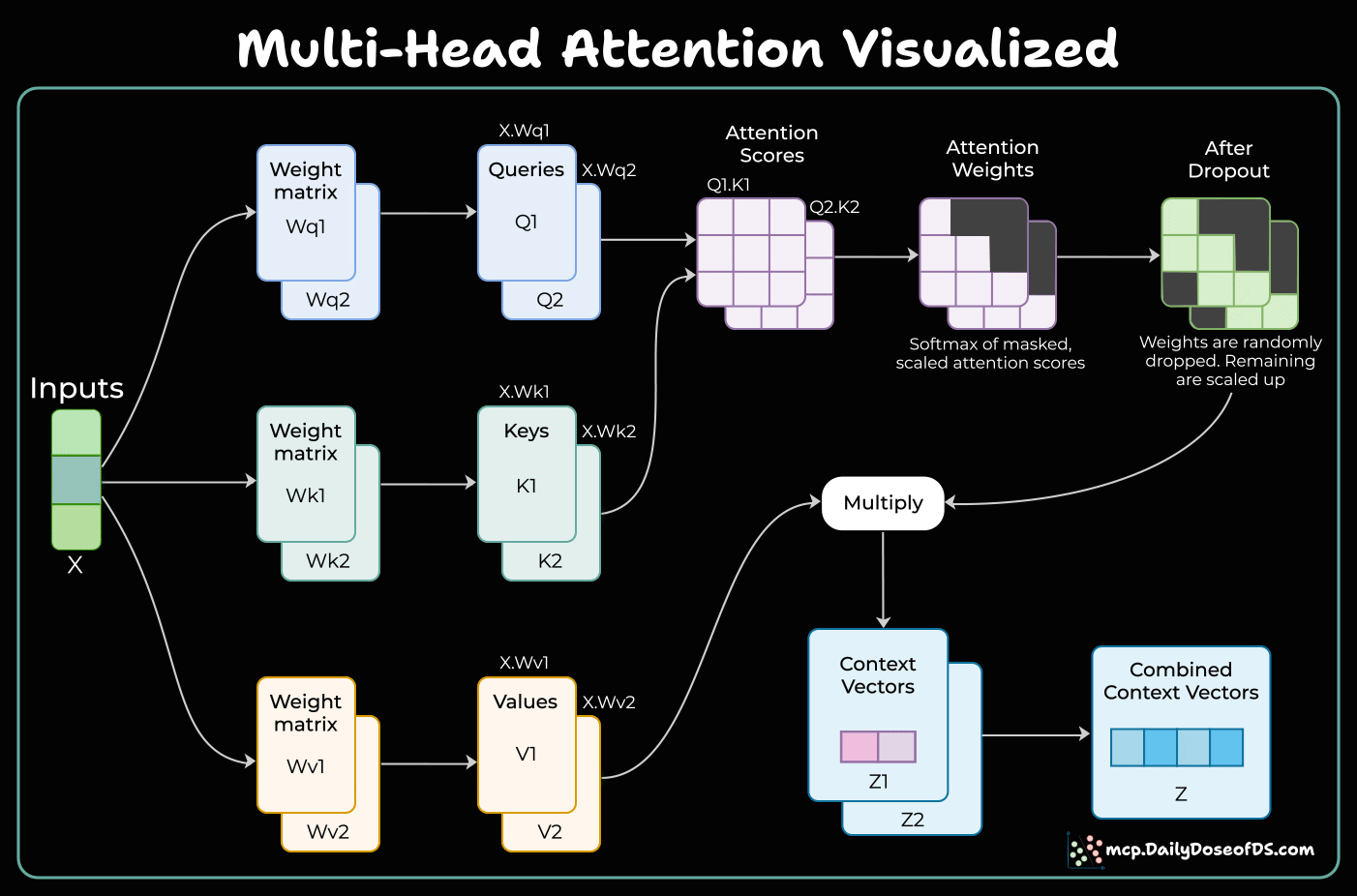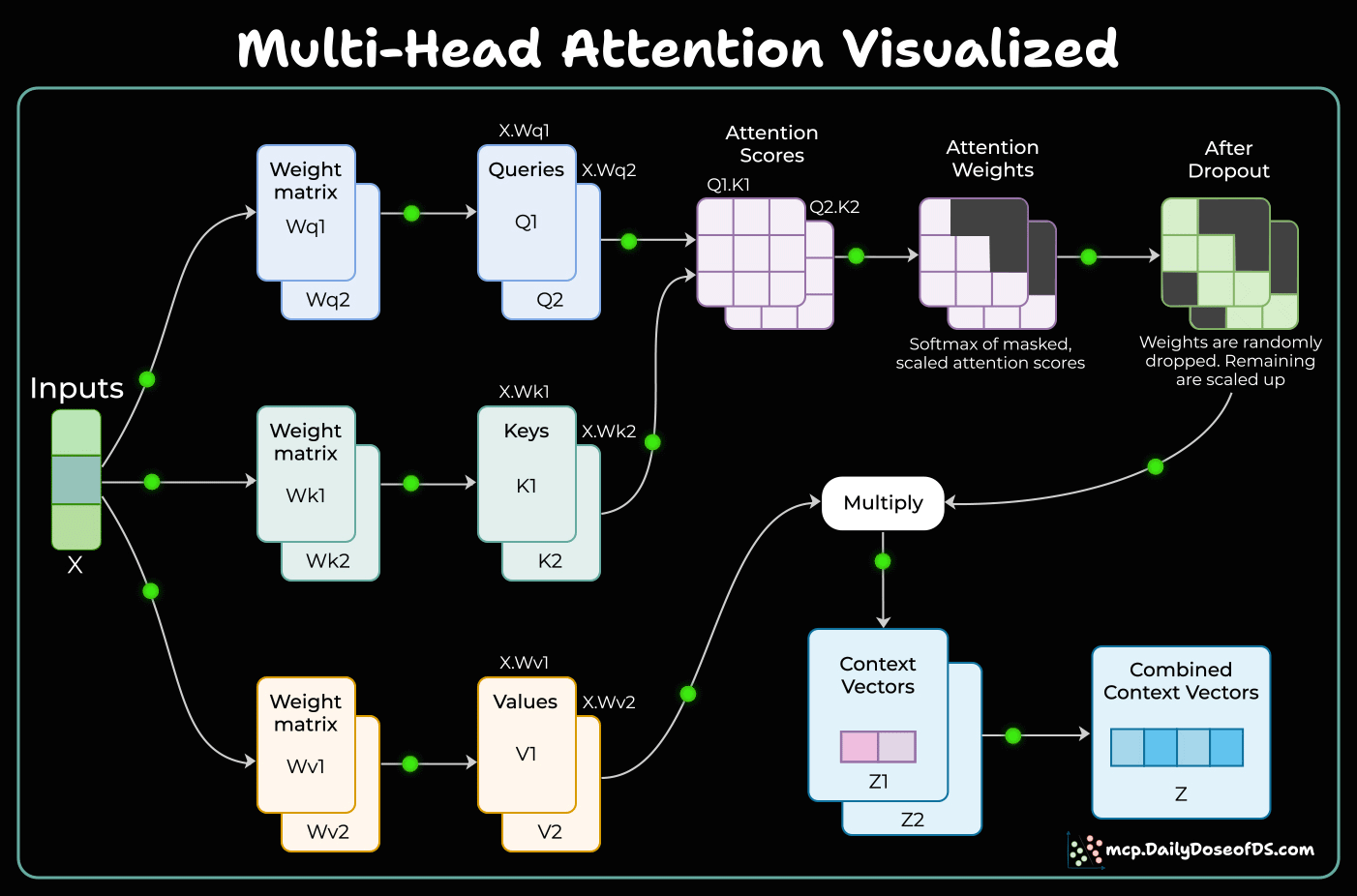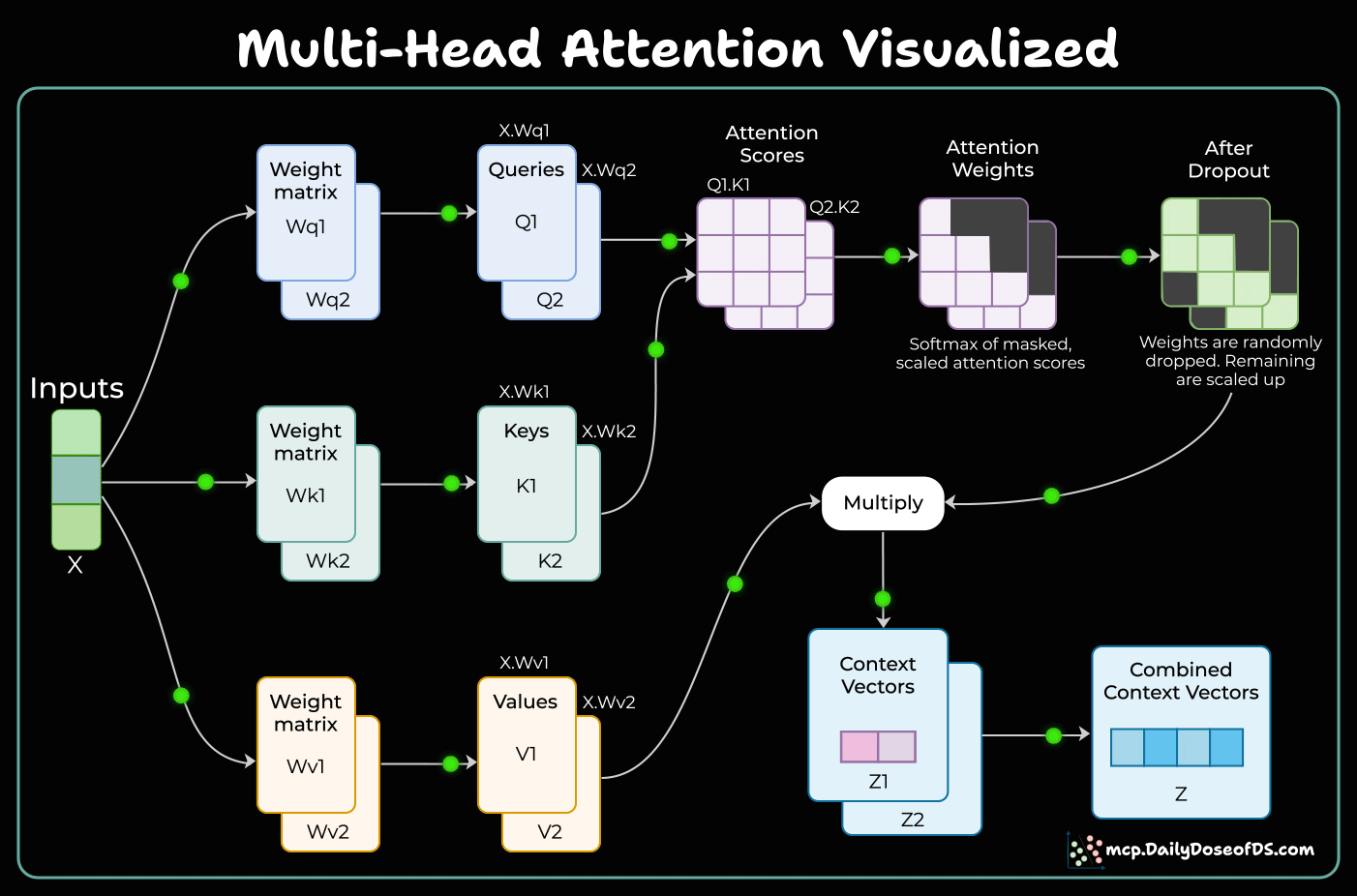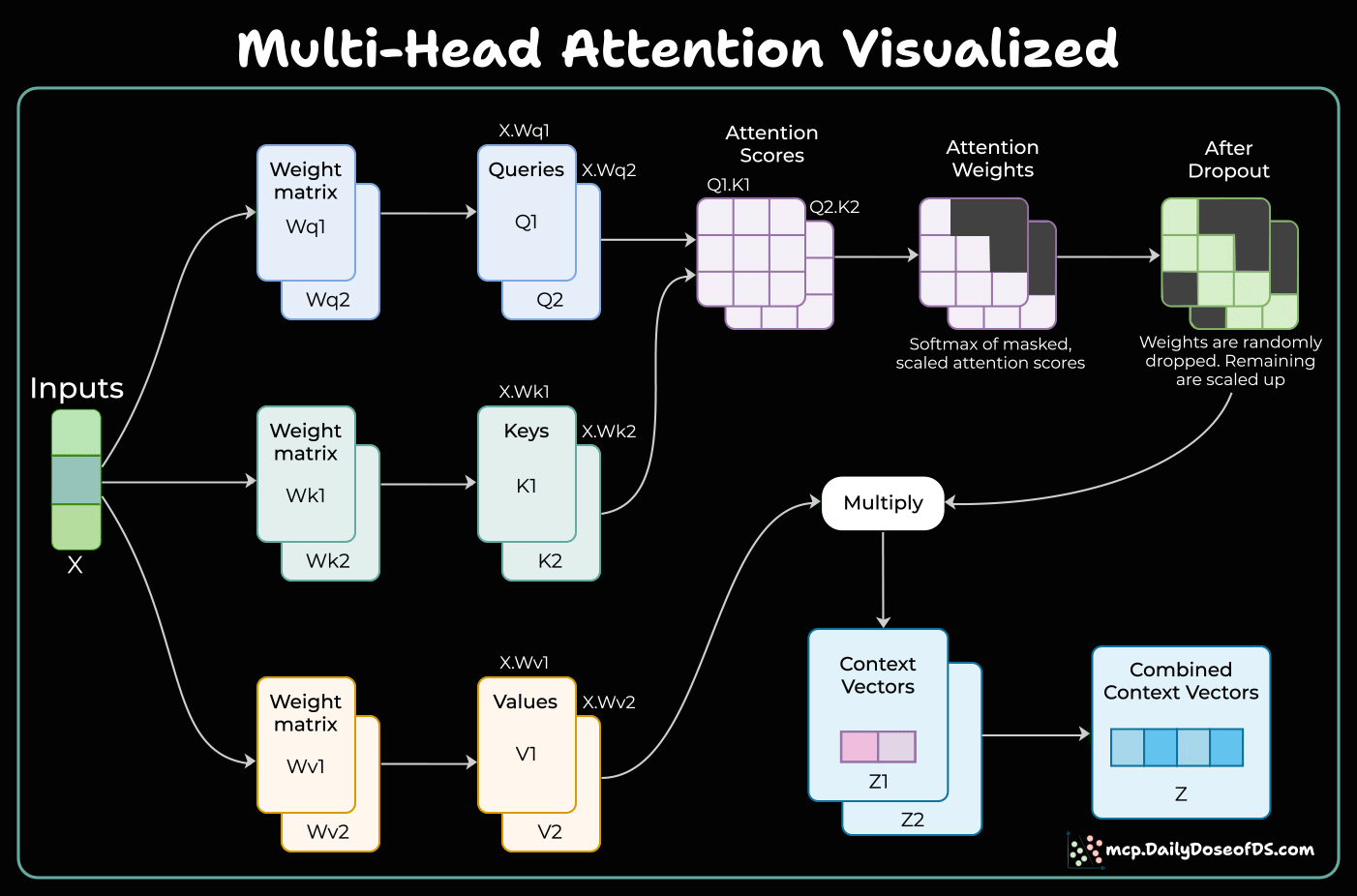
Input gets transformed into Queries, Keys, and Values
Each attention head focuses on different relationships - one captures grammar, another tracks long-distance dependencies
Attention scores determine which words matter to each other
Scores get normalized and combined into context vectors
The magic happens when you run multiple heads in parallel. Each head discovers unique patterns, and together they give the model a complete understanding.
This matters because traditional models like RNNs process sequences step-by-step, losing context. Multi-Head Attention sees everything at once and understands relationships that would otherwise be invisible.
This is why modern AI can write code, translate languages, and understand nuance.
For further practical reading, we implemented Llama 4 from scratch, which is a mixture of experts, in this article →
It covers:
Character-level tokenization
Multi-head self-attention with rotary positional embeddings (RoPE)
Sparse routing with multiple expert MLPs
RMSNorm, residuals, and causal masking
And finally, training and generation.
Thanks for reading!