
The Utility of Vector Databases in LLMs
...and what made them so special almost overnight?

Build LLM apps on audio data with AssemblyAI LeMUR
AssemblyAI LeMUR is a framework that allows you to build LLM apps on speech data in <2 minutes and <10 lines of code.
This can include summarizing the audio, extracting some specific insights from the audio, doing Q&A on the audio, etc. A demo on Andrew Ng’s podcast is shown below:
First, transcribe the audio, which generates a
transcriptobject.

Next, prompt the transcript to generate an LLM output.

LeMUR can ingest over 1,000,000 tokens (~100 hours of audio) in a single API call.
Try LeMUR in AssemblyAI’s playground below:
Thanks to AssemblyAI for sponsoring today’s issue.
Why Vector Databases?
Vector databases are not new.
They have existed for a long time and have been at the core of recommender systems and search engines, which we use almost daily.
But have a look at these Google search trends for the topic “Vector database” over the last five years:

A technology that was almost of no interest has exploded in the last year or so.
In fact, companies that never existed two years ago have raised millions to develop dedicated vector databases or augment traditional databases (SQL or NoSQL) with vector search capabilities.
These are some dedicated vector databases that have gained traction lately:
Pinecone raised $138M.
Chroma DB raised $20M.
Zilliz (the company behind Milvus) raised $113M.
Qdrant raised $37.8M.
Weaviate raised $67.7M.
And there are many more…
The obvious question at this point is…
What made Vector databases so special almost overnight?
Let’s understand!
The problem
Unstructured data is everywhere.

The voice notes you receive → Unstructured data.
The images in your phone → Unstructured data.
The emails in your inbox → Unstructured data.
The lines in this article → Unstructured data.
The videos you watch → Unstructured data.
This data is important, of course. It would be good if we could query this data to extract information, just like we can query a traditional SQL database.
Sample query: “From a library of photos, select all photos with a mountain.”
However, storing this data in a traditional DBMS is difficult because it is designed to store structured data with well-defined schemas.
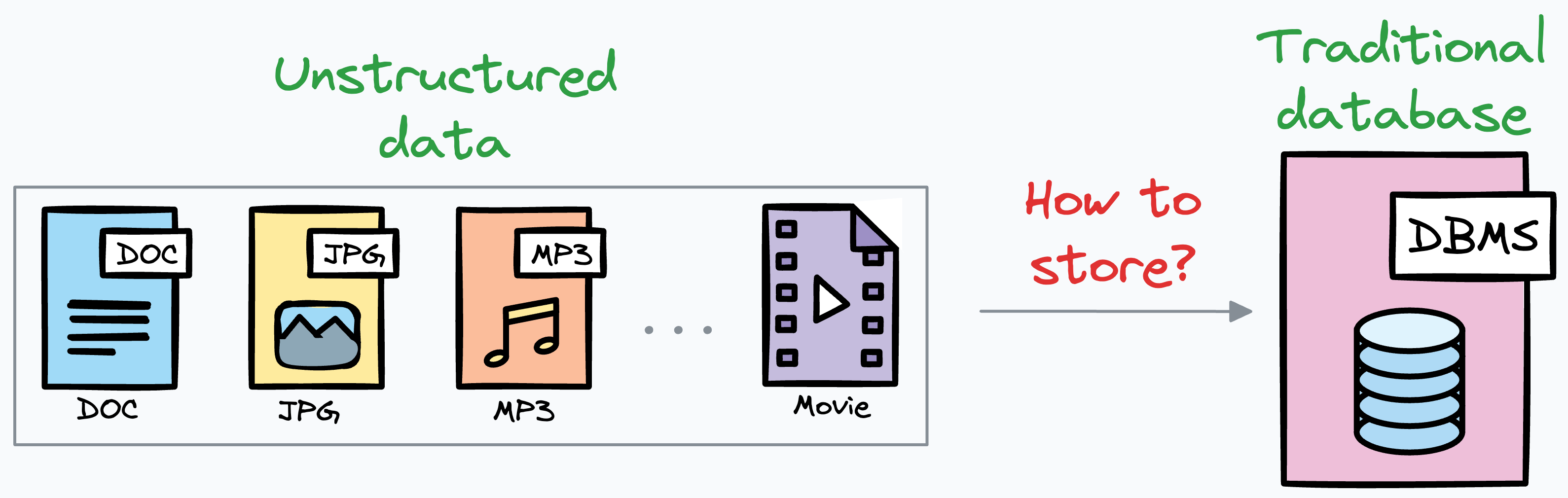
Simply put, how would we even define columns to store audio/video/image/text?
There’s one more issue.
Consider the sample query written above.
There are possibly 20+ ways of writing this query:
Pictures with mountains.
Photos with mountains.
Pics with a mountain.
Mountain pictures.
Mountain pics
and more…
In other words, there’s no standard syntax (like SQL’s — Select * From TABLE where Condition) to query such data.
Makes sense so far?
The solution
So someone came up with the idea of encoding unstructured data into high-dimensional vectors (using ML techniques) and storing those vectors in a table format (we are simplifying a bit here).
This numerical vector is called an embedding, and it captures the features and characteristics of the underlying data being embedded.
Consider word embeddings, for instance.
When we analyze them, the representations of fruits are found close to each other, cities form another cluster, and so on.
A database specifically designed to store vectors is a vector database (there’s one more point that we shall discuss shortly).
This solves both problems we discussed earlier:
We found a way to store unstructured data ✅
Embeddings can handle linguistic diversity at query time ✅
Vector databases with LLMs
Vector databases are profoundly used in conjunction with LLMs.
It is an inexpensive way to make an LLM practically useful as it allows the model to generate text on something it was never trained on.
How?
Some background details
LLMs can not be trained on every piece of information in the world.
Consider LLaMA 2 — an open-source LLM by Meta.
When they trained it, they did not have access to:
Information generated after the data snapshot date.
The internal docs of your company.
Your private datasets
and more.
For instance, if the model was trained on data until 8th August 2024 (this is the snapshot date), it will have no clue what happened after that:

To solve this:
Either one could continue to train the model on new data or fine-tune it on the internal dataset. But this is challenging because these models are 100s of GB in size.
Or they could use a vector database, which eliminates fine-tuning requirements.
This is how it works:
Encode and store the additional data in a vector database. Each vector will capture semantic information about the encoded text.
When the LLM wants to generate text, query the vector database to retrieve vectors that are similar to the prompt’s vector. We can use a similarity search here.
Pass the retrieved information along with the prompt to the LLM.
Done!
The idea is called RAG, and it is demonstrated below:
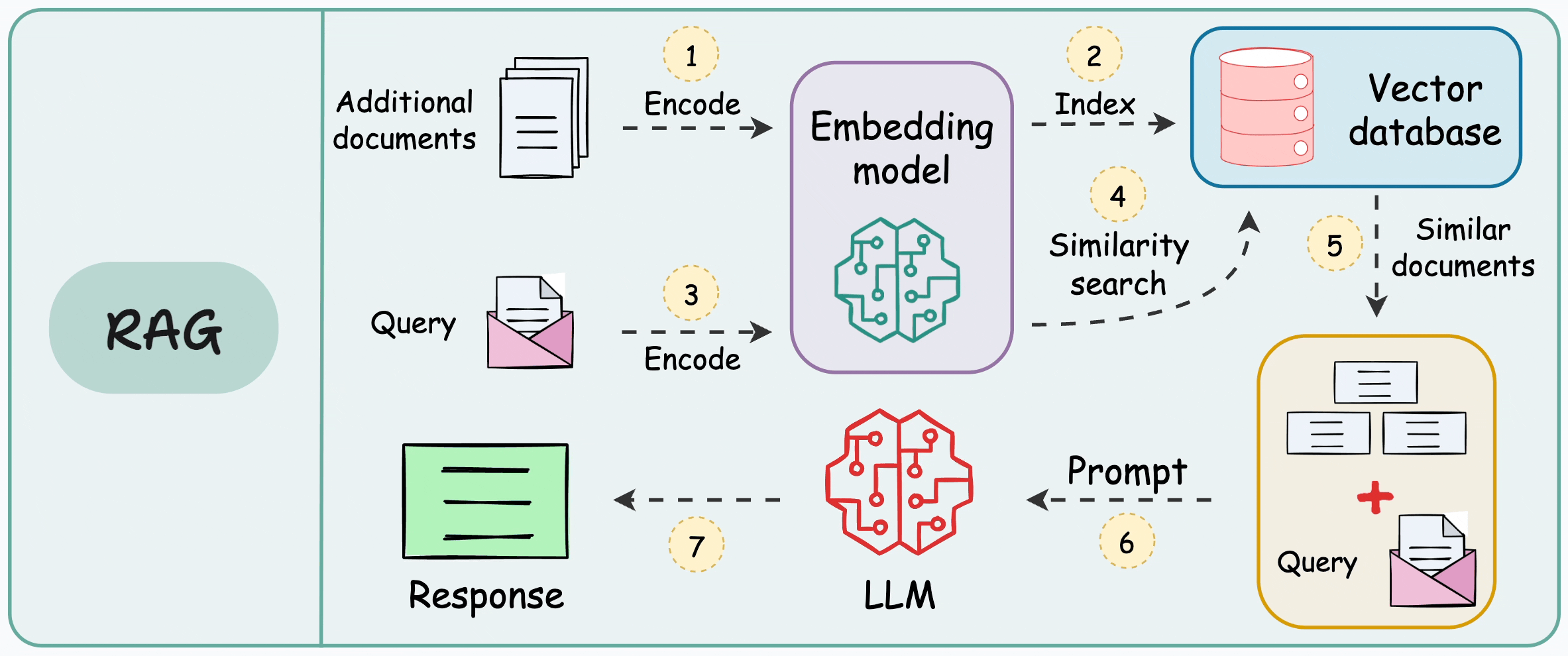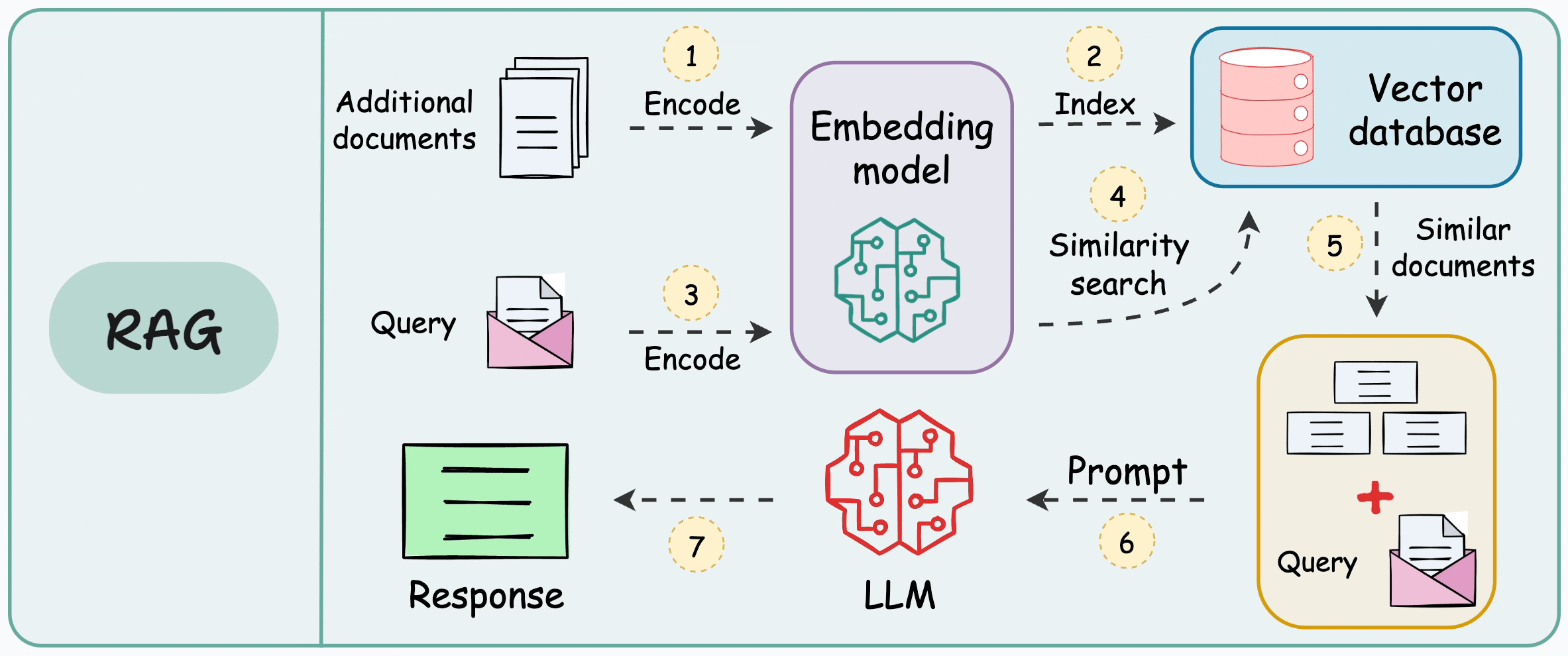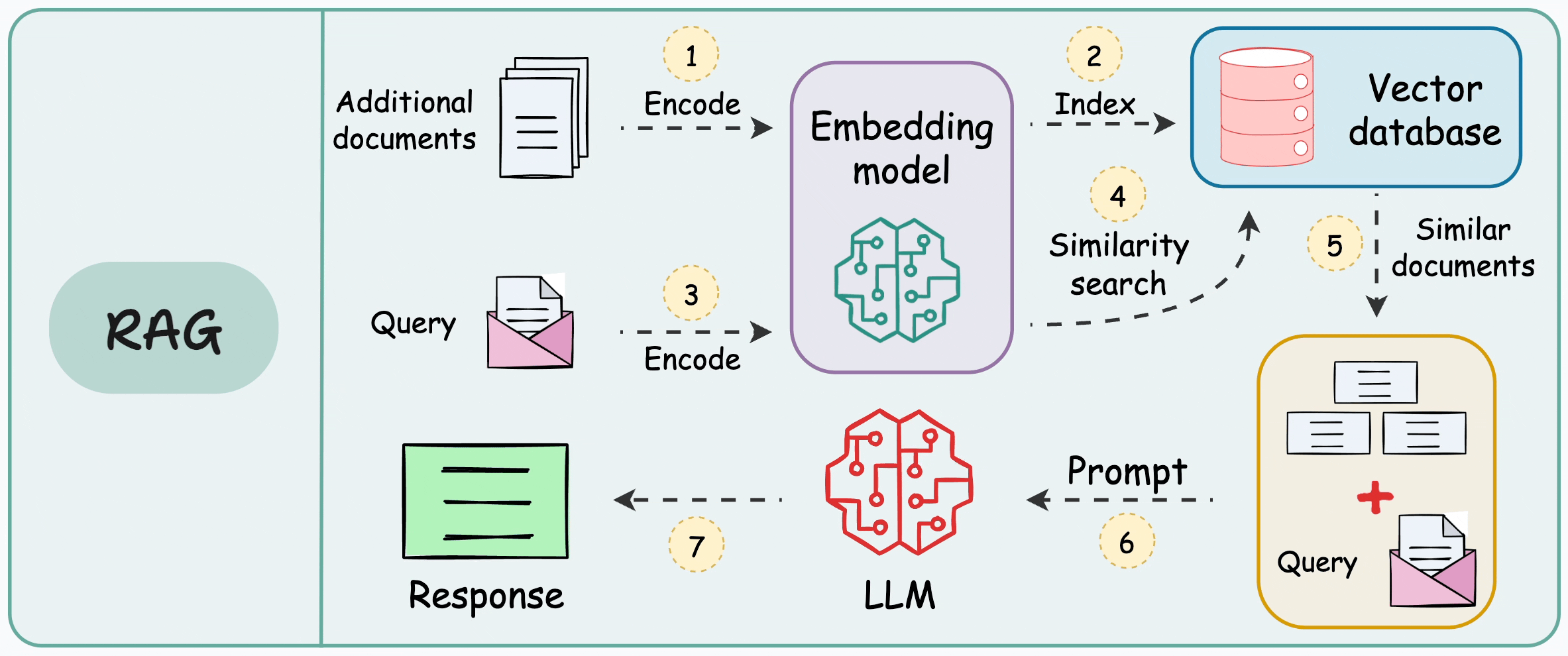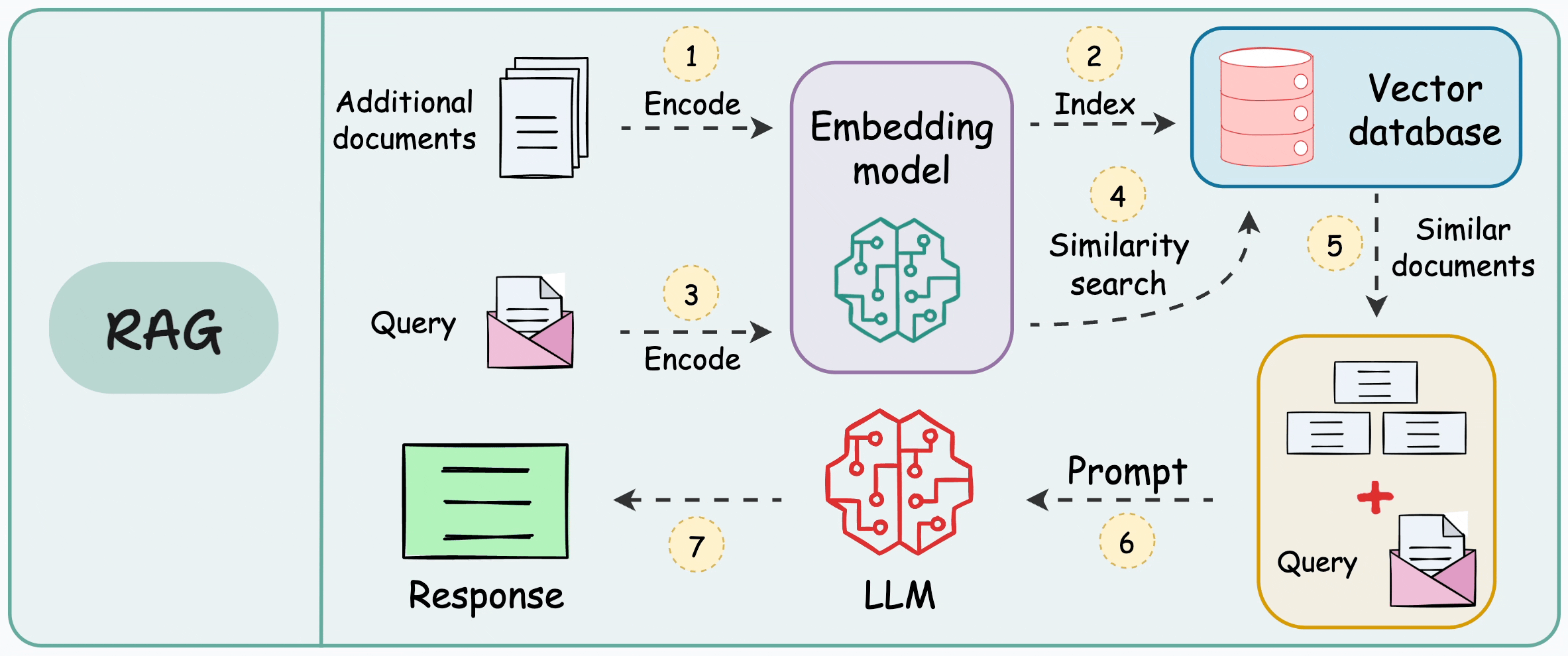
By injecting relevant details into the prompt, LLM can generate more precise answers even if it was not explicitly trained on that data.
Now, you might have understood why vector databases have exploded in recent years.
In essence, a vector database makes the LLM much more “real-time” in nature because, ideally, you may want to interact with the data that was generated just 2 seconds after the data snapshot time.
This is not possible with fine-tuning. This approach will never be “real-time.”
But when using a vector database, all we have to do is dump the incoming data into it, and query it when needed.
Investing a few hundred dollars a month in a vector database can prevent tens of thousands of dollars in fine-tuning costs.
All businesses love to save (or make) more money.
They saw this opportunity for cost saving, which led to a ridiculous increase in demand, which further led to the incorporation of companies valued at hundreds of millions of dollars.
Concluding remark
Of course, vector databases are great!
But like any other technology, they do have pros and cons.
Just because vector databases sound cool, it does not mean that you have to adopt them everywhere you wish to query vectors.
For small-scale applications with a limited number of vectors, simpler solutions like NumPy arrays and doing an exhaustive search will suffice.
There’s no need to move to vector databases unless you see any benefits, such as latency improvement in your application, cost reduction, and more.
👉 Over to you: The context window of LLMs is increasing rapidly. Do you think this will make RAGs obsolete?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 84,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Hi avi. I'll have to disagree with you here. People dramatically overestimate the performance improvements from vector DBS. Even with very high scales, more traditional ir techniques can be a great foundation (using vector embeddings more for precision one we have filtered the most useless parts). And here, more normal DBs are good enough for storing vectors