
Top AI Labs Share an Agent Memory Trick Most Miss
...Microsoft, Google, Meta all do it.

The more your agent remembers, the less it knows.
The idea above sounds counterintuitive, but it is actually a direct result of how agent memory is built today.
Agent memory inherits the cognitive shape of its store.
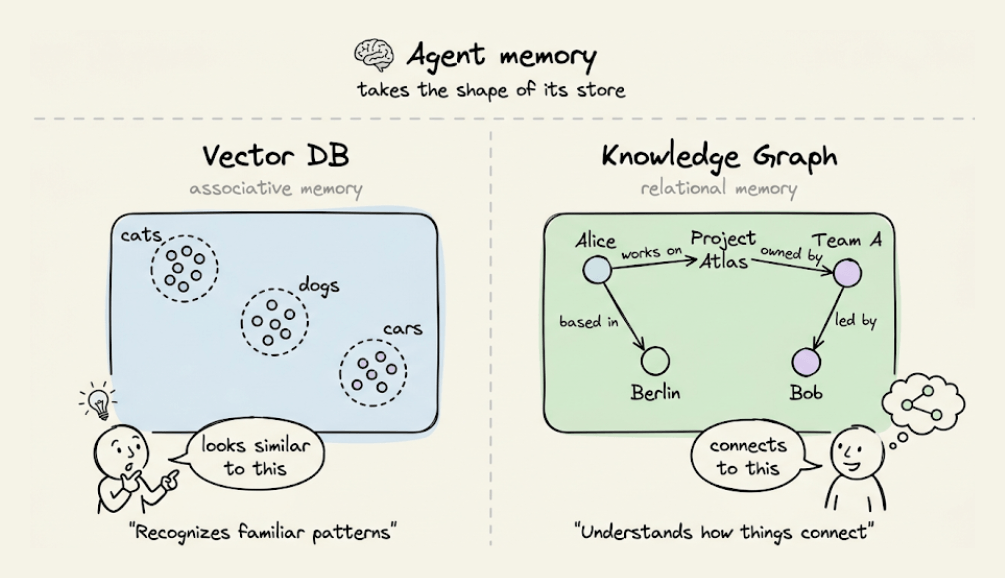
A vector DB gives it associative memory to recognize familiar patterns.
A graph gives it relational memory to understand how things connect.
Most agents run on the first and skip the second.
Here’s an example that explains the failure it leads to:
Say a study assistant stores three facts about a student in a vector DB:
Mark is in grade 10.
Grade 10 has final exams in March.
The library closes 2 weeks before final exams.
Mark asks: “Will the library be open next week?”
The vector DB likely returns the first and third facts, because the query mentions Mark and the library.
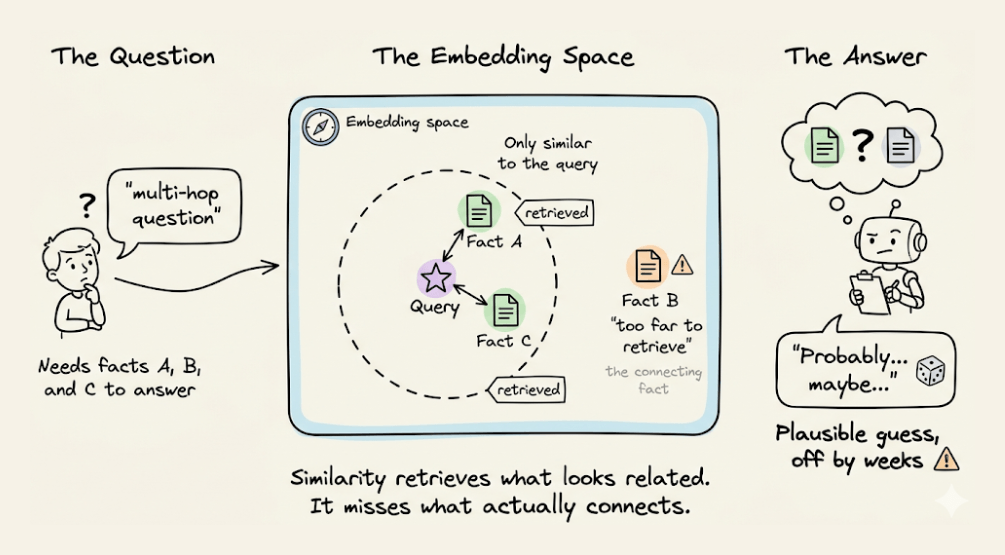
But it skips the middle fact, which links Mark’s grade to the exam time, because that fact mentions neither Mark nor the library.
It sits in embedding space too far from the query to make it to the retrieved context.
So the Agent answers with partial info, or it fills the gap with a plausible guess that sounds right but might be off by weeks.
This is not a corner case, but it’s actually what real queries look like. Any question that spans two or more hops exceeds what a similarity search can do.
Increasing context windows and retrieving more context is one solution.
But accuracy drops over 30% when the relevant fact sits in the middle of a long context, which is the well-known “lost in the middle” problem.
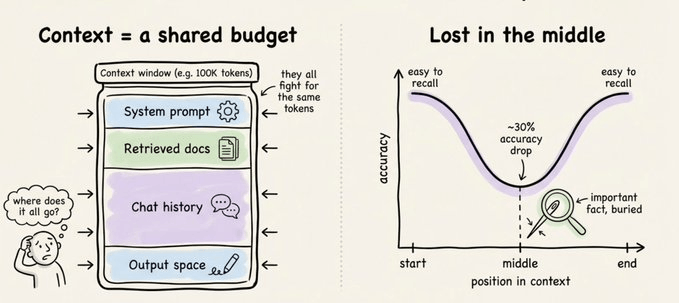
A bigger window is not the same as better memory. It just gives the model more room to miss things.
To actually solve this problem, you need to stop treating memory as a single store and start treating it as three complementary layers, each doing a job the others cannot.
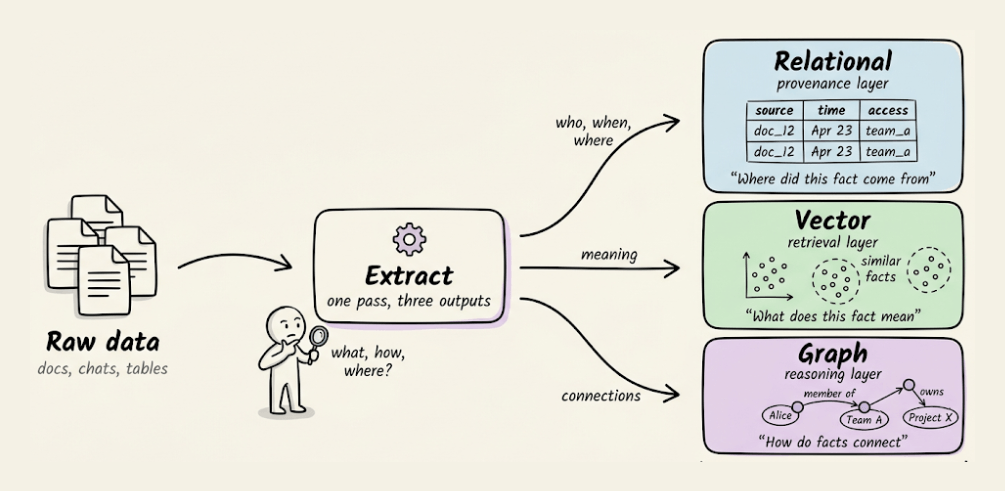
Relational: It stores where a fact came from, when it was stored, and who has access. This is the provenance layer.
Vector: It stores what a fact means and what it is semantically similar to. This is the retrieval layer.
Graph: It stores how facts connect, what depends on what, and who relates to whom. This is the reasoning layer.
All three are important and complementary:
A vector DB alone gives similarity without relationships.
A graph alone gives relationships without semantic search.
A relational store alone tracks where data came from but cannot reason over it.
If you want to see this in practice, Cognee (open-source) implements this approach.
It runs an ECL pipeline (Extract, Cognify, Load) that writes into all three stores in a single pass and keeps them synchronized as new data arrives.
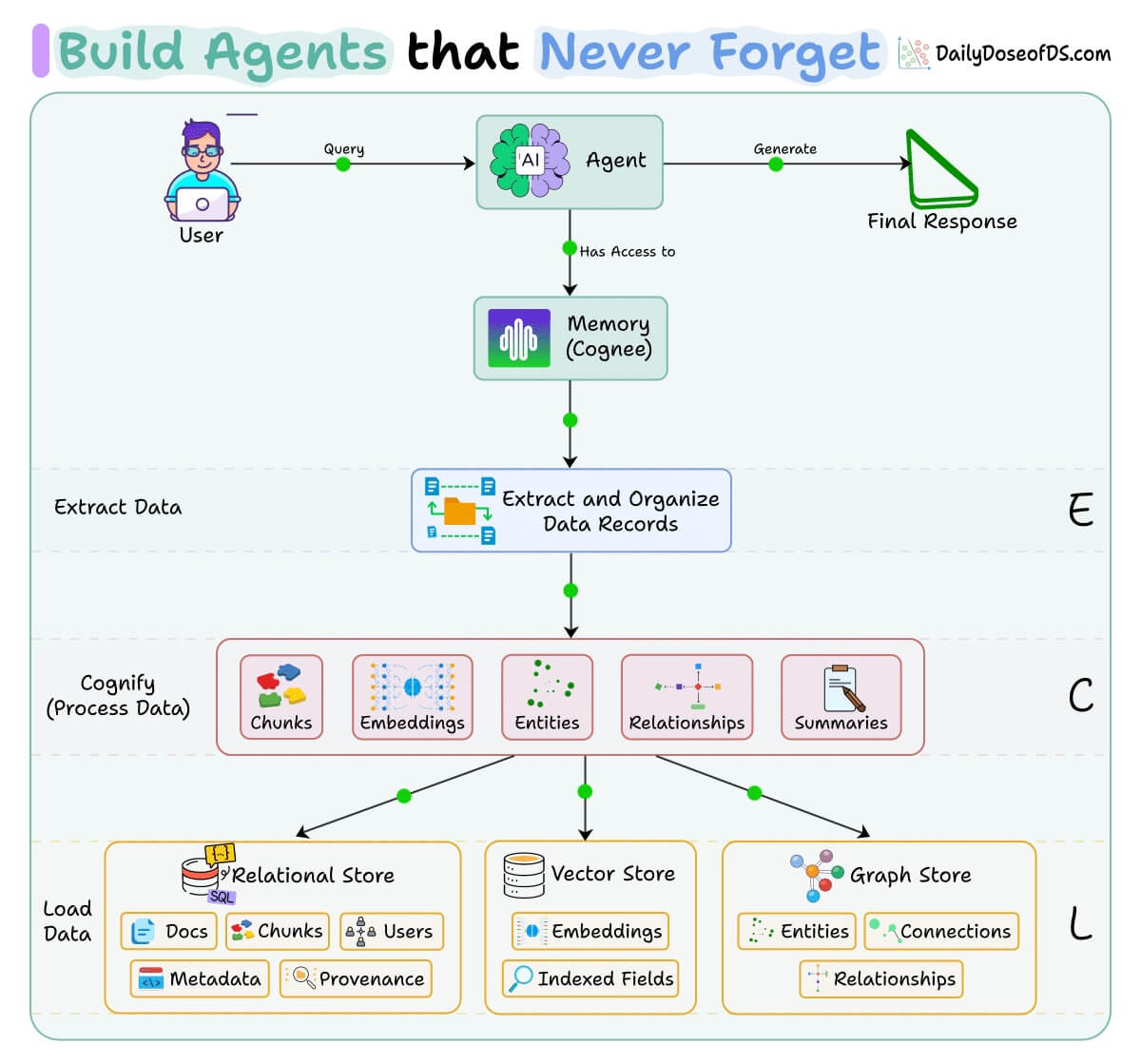
So the vectors and graph edges are built together during indexing, not glued together later.
On top of this, there are two things Cognee does differently from most memory tools:
1) Smarter entity resolution:
You can give Cognee a domain vocabulary file, and it uses it to merge duplicate mentions automatically.
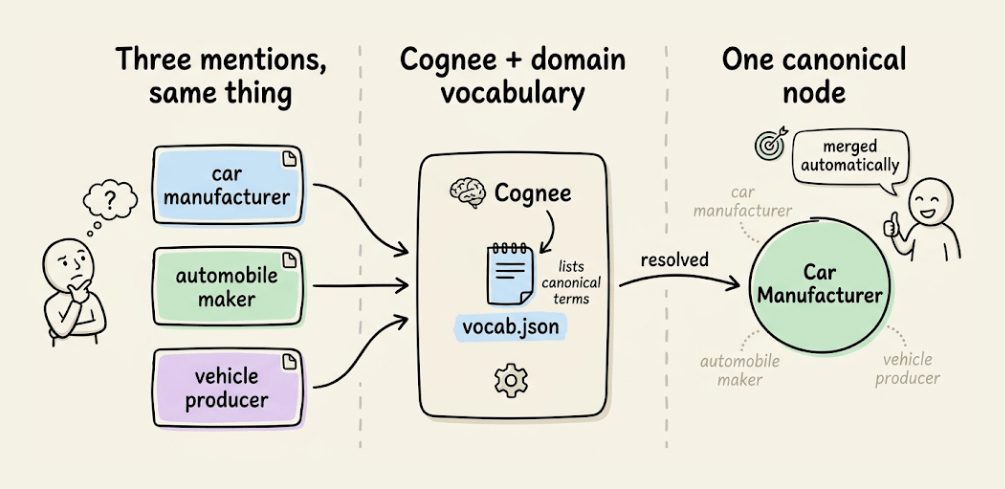
So “car manufacturer,” “automobile maker,” and “vehicle producer” collapse into one canonical node instead of being available as three separate entries.
2) Local-first defaults:
The default stack runs on a single pip install and stays fully local. You can switch to Postgres and Neo4j for production without changing the API.
We wrote a first-principles walkthrough of agent memory that takes the same problem and works through every layer of the stack, ending in a real working agent built on Cognee.
And you can find the Cognee GitHub repo here →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
Clearly explained