
Traditional RAG vs. HyDE
...explained visually.

One critical problem with the traditional RAG system is that questions are not semantically similar to their answers.
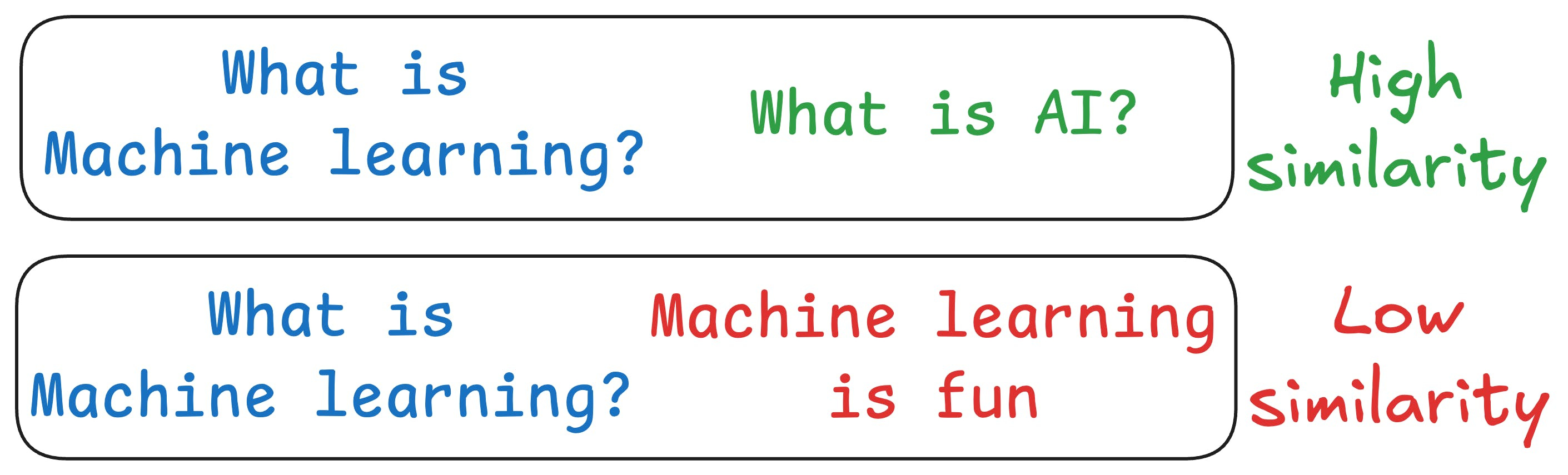
As a result, several irrelevant contexts get retrieved during the retrieval step due to a higher cosine similarity than the documents actually containing the answer.
HyDE solves this.
The following visual depicts how it differs from traditional RAG and HyDE.
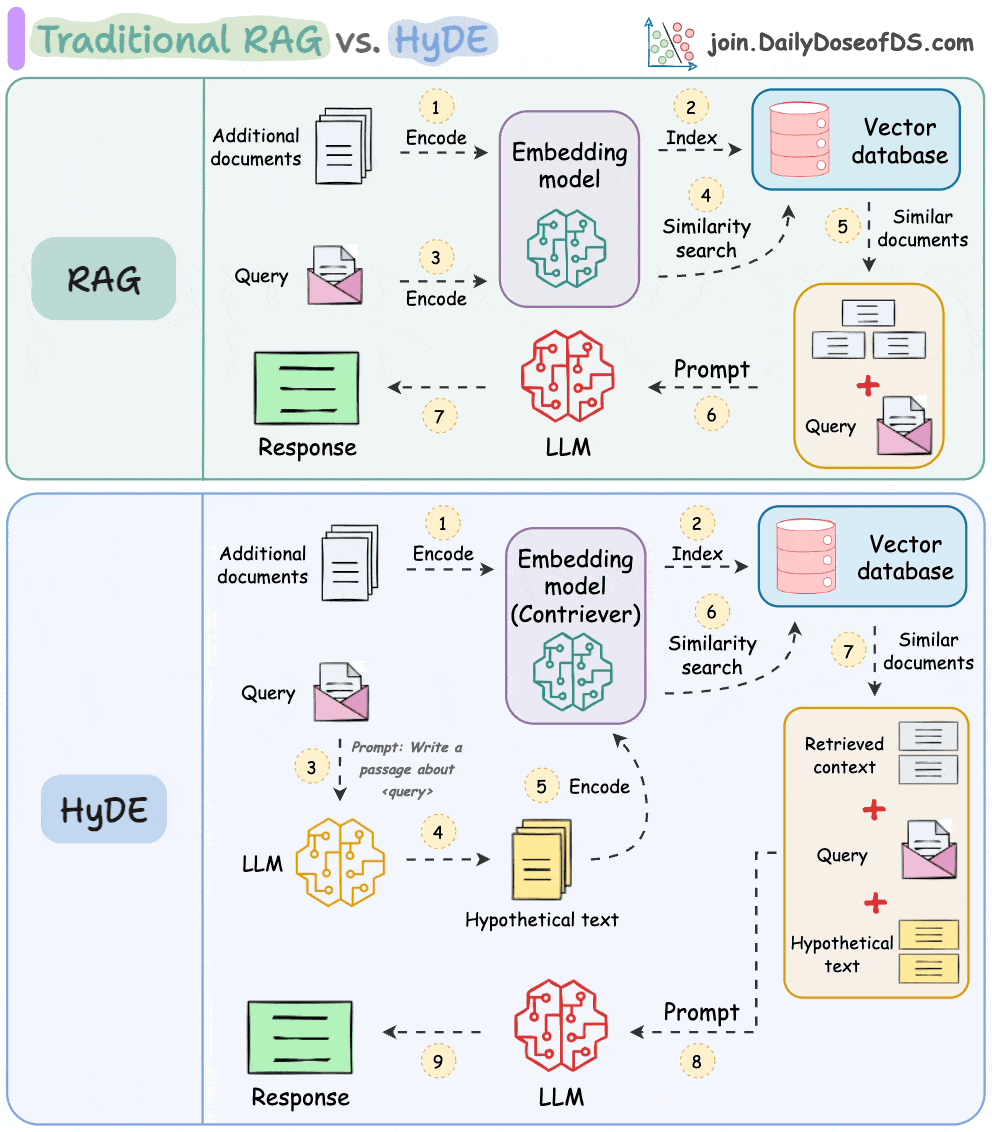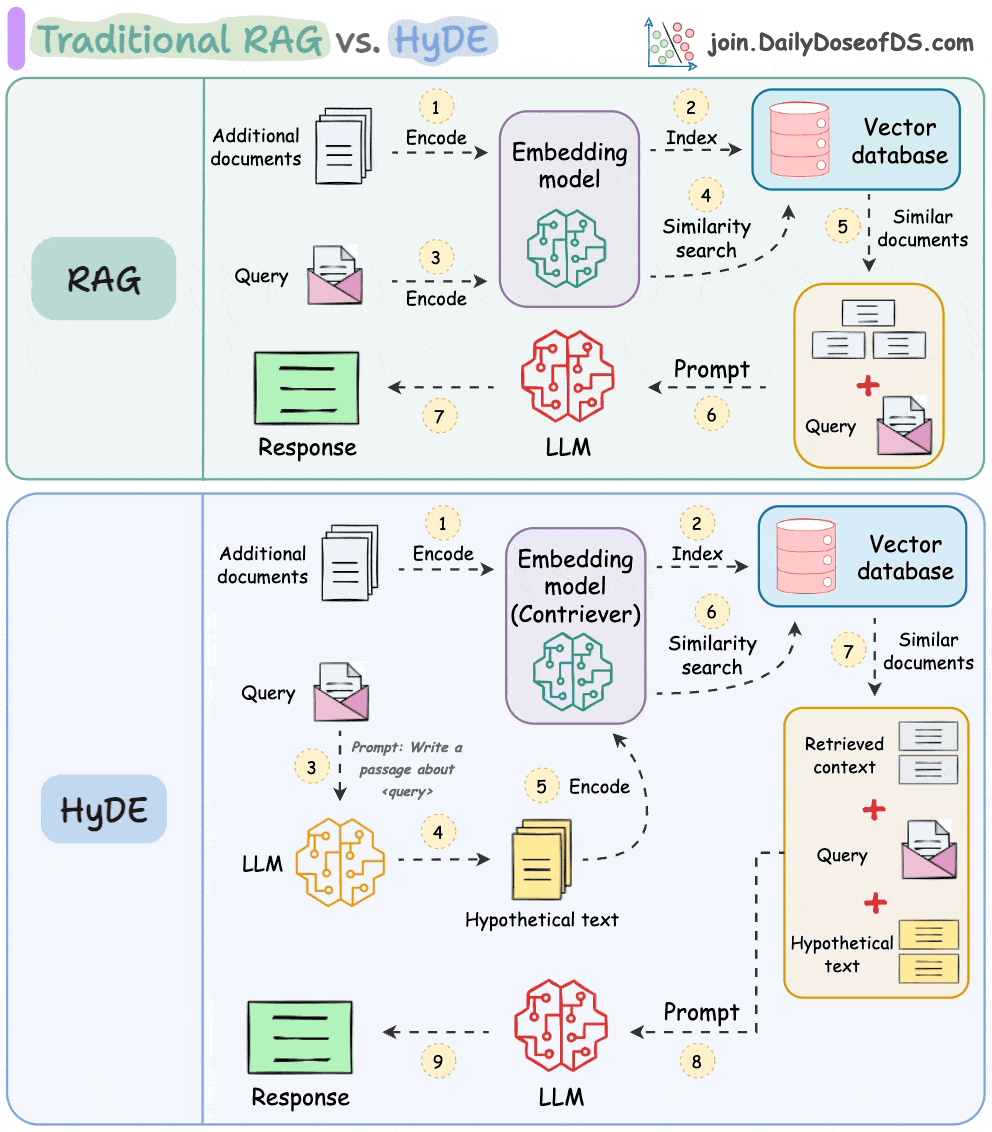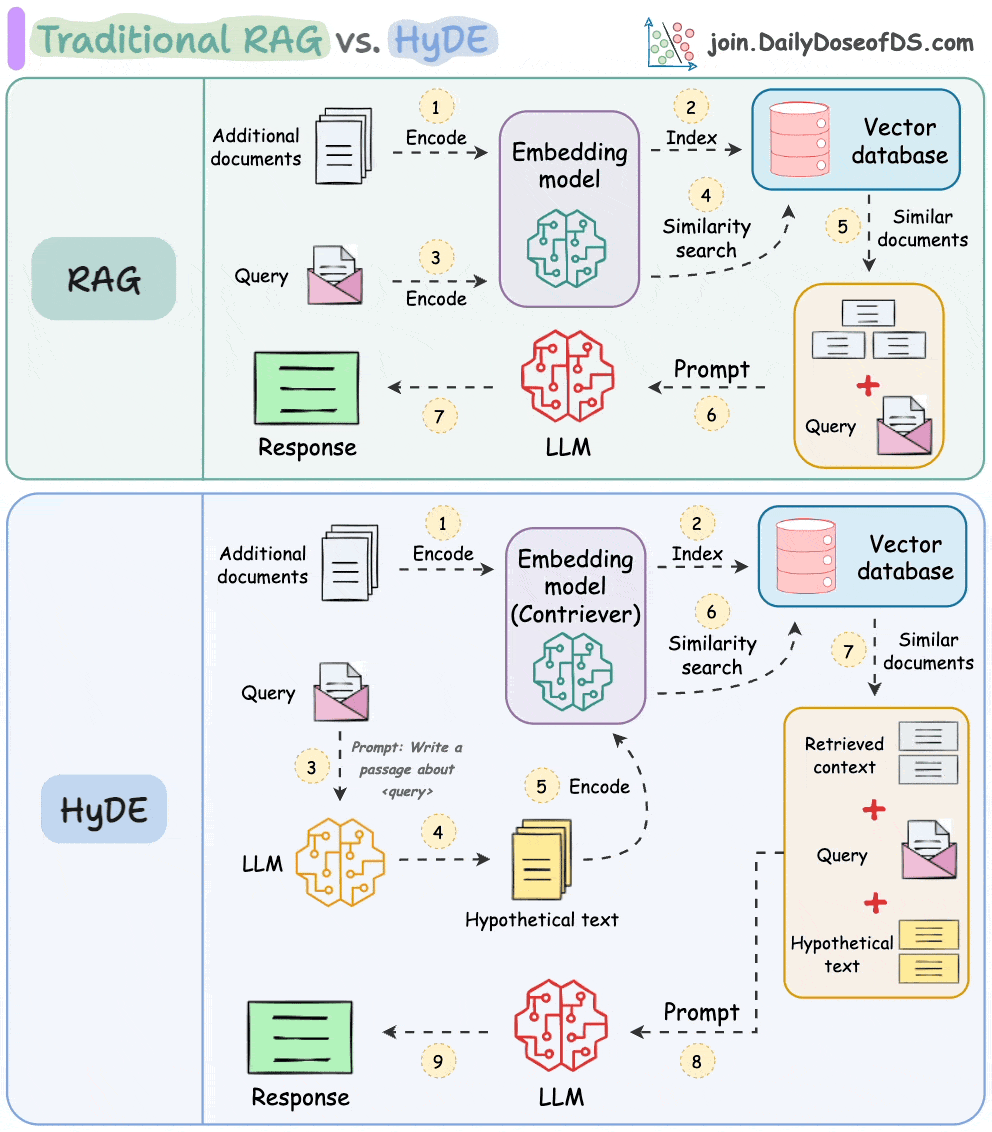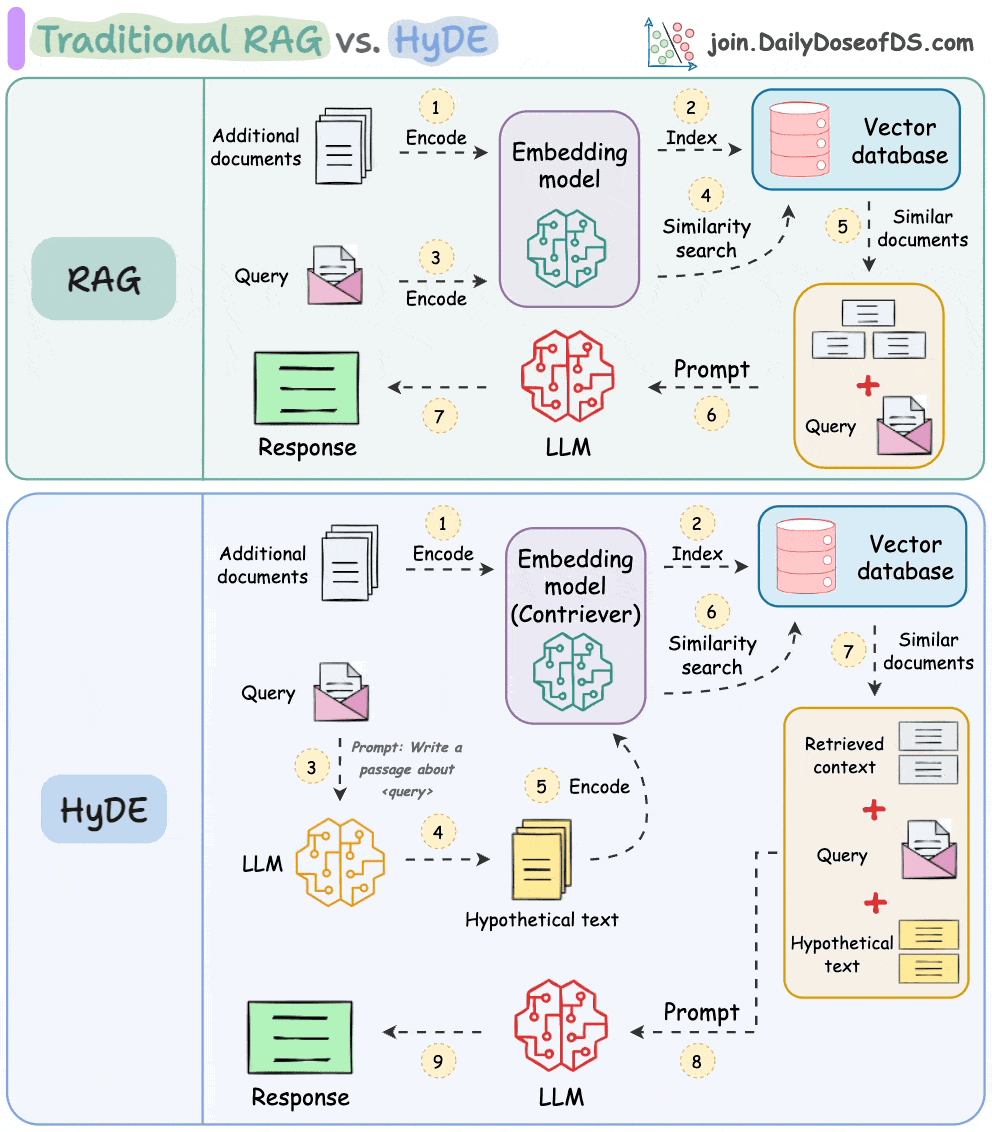
Let's understand this in more detail today.
On a side note, we started a beginner-friendly crash course on RAGs recently with implementations. Read the first three parts here
Motivation
As mentioned earlier, questions are not semantically similar to their answers, which leads to several irrelevant contexts during retrieval.
HyDE handles this as follows:
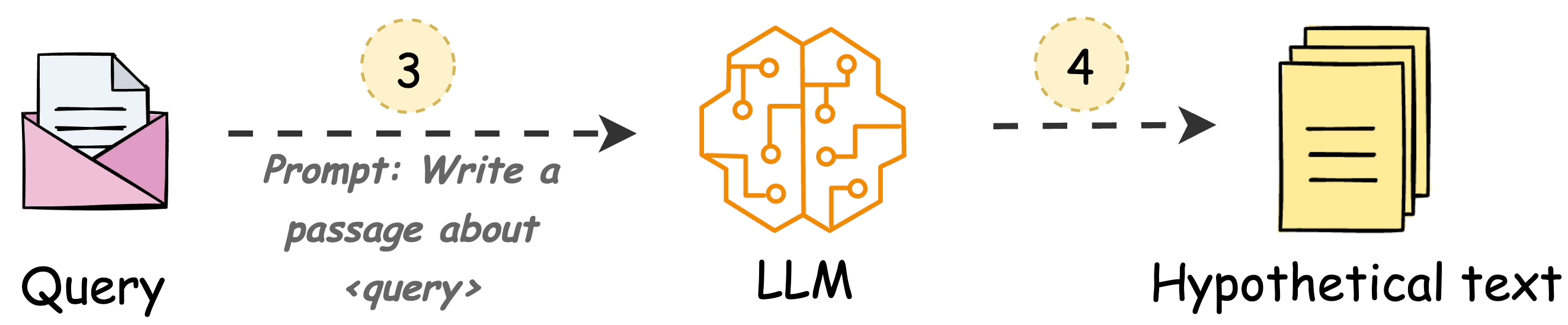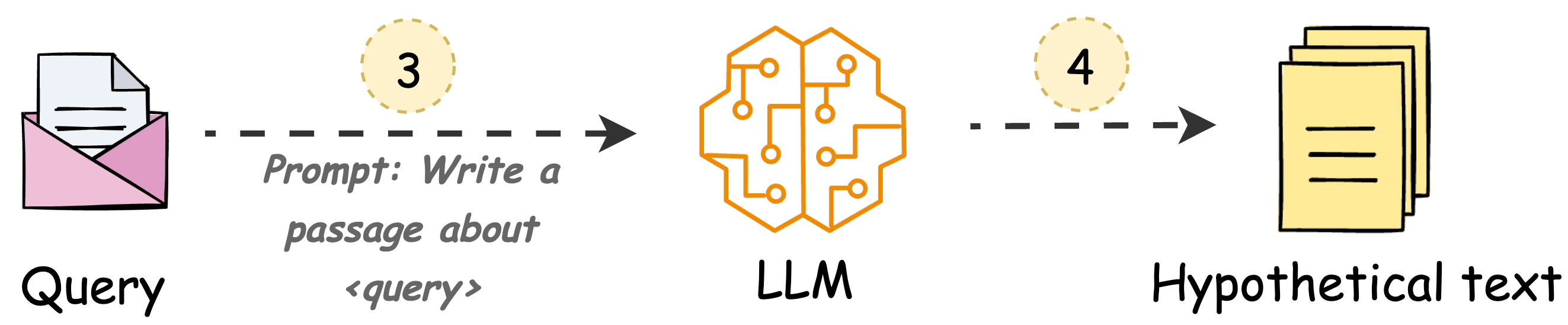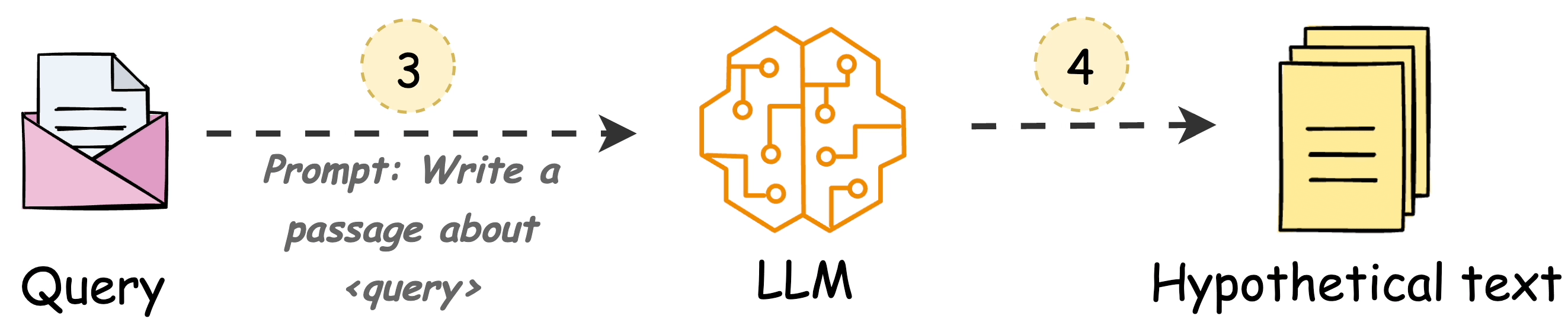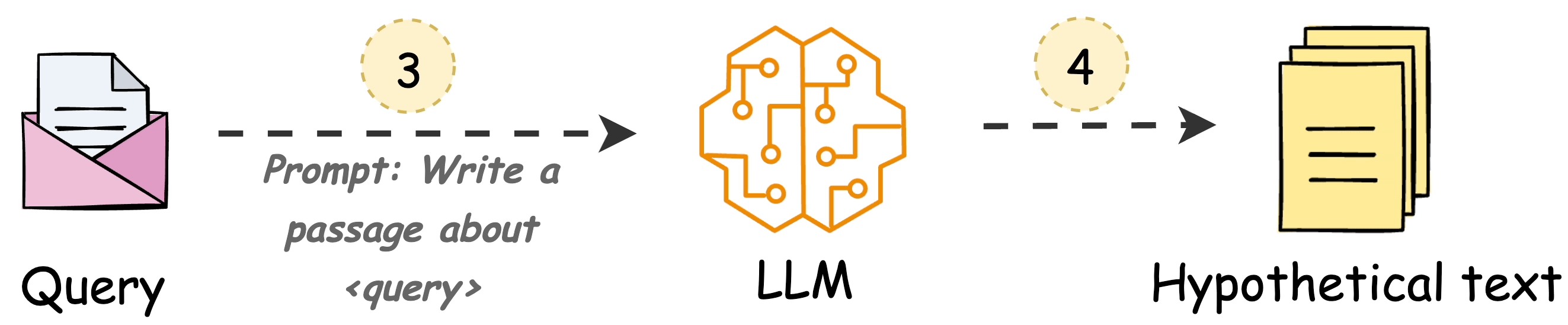
Use an LLM to generate a hypothetical answer
Hfor the queryQ(this answer does not have to be entirely correct).Embed the answer using a contriever model to get
E(Bi-encoders are famously used here, which we discussed and built here).Use the embedding
Eto query the vector database and fetch relevant context (C).Pass the hypothetical answer
H+ retrieved-contextC+ queryQto the LLM to produce an answer.
Done!
Now, of course, the hypothetical generated will likely contain hallucinated details.
But this does not severely affect the performance due to the contriever model—one which embeds.
More specifically, this model is trained using contrastive learning and it also functions as a near-lossless compressor whose task is to filter out the hallucinated details of the fake document.
This produces a vector embedding that is expected to be more similar to the embeddings of actual documents than the question is to the real documents:

Several studies have shown that HyDE improves the retrieval performance compared to the traditional embedding model.
But this comes at the cost of increased latency and more LLM usage.
We will do a practical demo of HyDE shortly.
In the meantime...
We started a beginner-friendly crash course on building RAG systems. Read the first three parts here:
👉 Over to you: What are some other ways to improve RAG?
P.S. For those wanting to develop “Industry ML” expertise:

We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn how to build real-world RAG apps, evaluate, and scale them: A crash course on building RAG systems—Part 3 (With Implementation).
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality.
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 110,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
We will do a practical demo of HyDE shortly - Can you do this as a deep multi part walk through like you did on RAG 1, 2, 3. This concept will really help to solve some current issues i am working on