
Train and Test-time Data Augmentation
More data from existing data.


Data augmentation strategies are typically used during training time.
The idea is to use some clever techniques to create more data from existing data, which is especially useful when you don’t have much data to begin with:
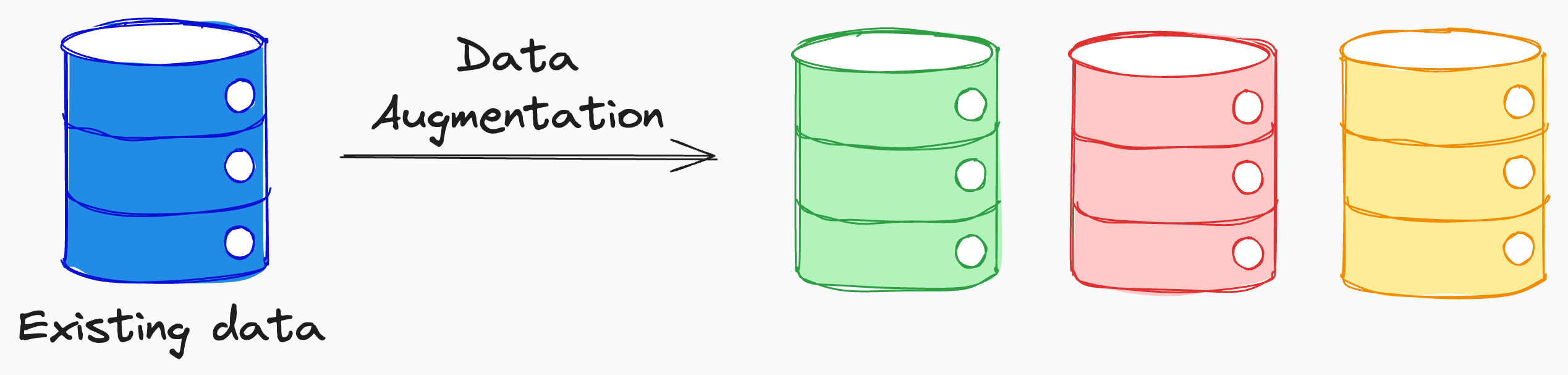
Let me give you an example.
These days, language-related ML models have become quite advanced and general-purpose. The same model can translate, summarize, identify speech tags (nouns, adjectives, etc.), and much more.
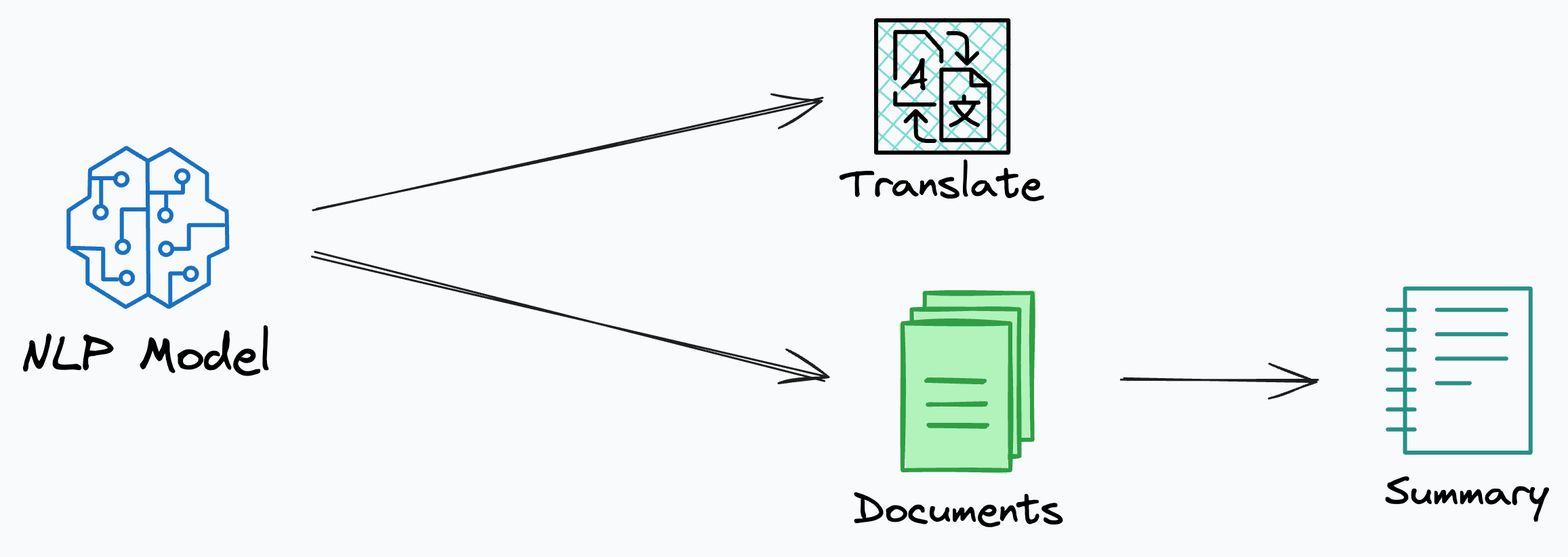
But earlier, models used to be task-specific (we have them now as well, but they are fewer than we used to have before).
A dedicated model that would translate.
A dedicated model that would summarize, etc.
In one particular use case, I was building a named entity recognition (NER) model, and the objective was to identify named entities.
An example is shown below:

I had minimal data — around 8-10k labeled sentences. The dataset was the CoNLL 2003 NER dataset if you know it.
Here’s how I approached data augmentation in this case.
Observation: In NER, the factual correctness of the sentences does not matter.
Revisiting the above example, it would not have mattered if I had the following sentence in the training data:

The sentence is factually incorrect, of course, but that does not matter.
The only thing that matters to the model is that the output labels (named entity tags in this case) must be correct.
So using this observation, I created many more sentences by replacing the named entities in an existing sentence with other named entities in the whole dataset:

For such substitutions, I could have used named entities from outside. However, it was important to establish a fair comparison with other approaches.
This technique (along with a couple more architectural tweaks) resulted in state-of-the-art performance. Here’s the research paper I wrote.
Moving on…
The above discussion was about training data augmentation.
But there’s also test-time augmentation.
To tell you more about it, I have invited Banias Baabe. He’s a Data Scientist at MHP (A Porsche Company) and a really good friend of mine.
Banias shares some really cool data science and Python tips daily on LinkedIn so do check him out: Banias on LinkedIn.
Here is Banias’ data science newsletter.

Make sure to subscribe and follow him :)
Over to Banias.
Test Time Augmentation
Test Time Augmentation (TTA) is when we apply data augmentation during testing.
More specifically, instead of showing just one test example to the model, we show multiple versions of the test example by applying different operations.
The model makes probability predictions for every version of the test example, which are then averaged to generate the final prediction:

Essentially, TTA creates an ensemble of predictions by considering multiple augmented versions of the same input, which leads to a more robust final prediction.
In fact, in this paper, the authors proved that the average model error with TTA never exceeds the average error of the original model, which is great.
As you may have guessed, the only catch is that it increases the inference time.
Data augmentation takes some time.
Generating multiple predictions increases the overall prediction run-time.
So, when a low inference time is important to you, think twice about TTA.
That’s it from Banias, I hope you loved it.
To summarize, if you can compromise a bit on inference time, TTA can be a powerful way to improve predictions from an existing model without having to engineer a better model.
In addition to TTA, we covered 11 powerful techniques to supercharge ML models here.
👉 Over to you: What are some other ways to improve model performance?
Thanks for reading!
Are you preparing for ML/DS interviews or want to upskill at your current job?
Every week, I publish in-depth ML dives. The topics align with the practical skills that typical ML/DS roles demand.
Join below to unlock all full articles:
Here are some of the top articles:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
A Detailed and Beginner-Friendly Introduction to PyTorch Lightning: The Supercharged PyTorch
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Join below to unlock all full articles:
👉 If you love reading this newsletter, share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
 | A guest post by
|
Wow, the NER 'factual correctness' insight is gold. So clever for small datasests, multumesc!