
Train Classical ML Models on Large Datasets
Extending the Bagging objective.

Cohere's Command R7B LLM: Lightweight, fast, and built for enterprises [Open-weights]
Cohere just announced Command R7B, a multilingual 7B-parameter open-weight model specialized for enterprise-focused LLM use cases, especially RAG.
Here are some key features:
Lightweight: Runs on low-end GPUs, MacBooks, and even CPUs.
Fast: Built for real-time chatbots and code assistants.
Enterprise-ready: Designed for agentic RAG with in-line citations.
As per official benchmarks, Command R7B outperforms the other similarly sized open-weight models in core business use cases such as RAG, tool use, and AI agents:
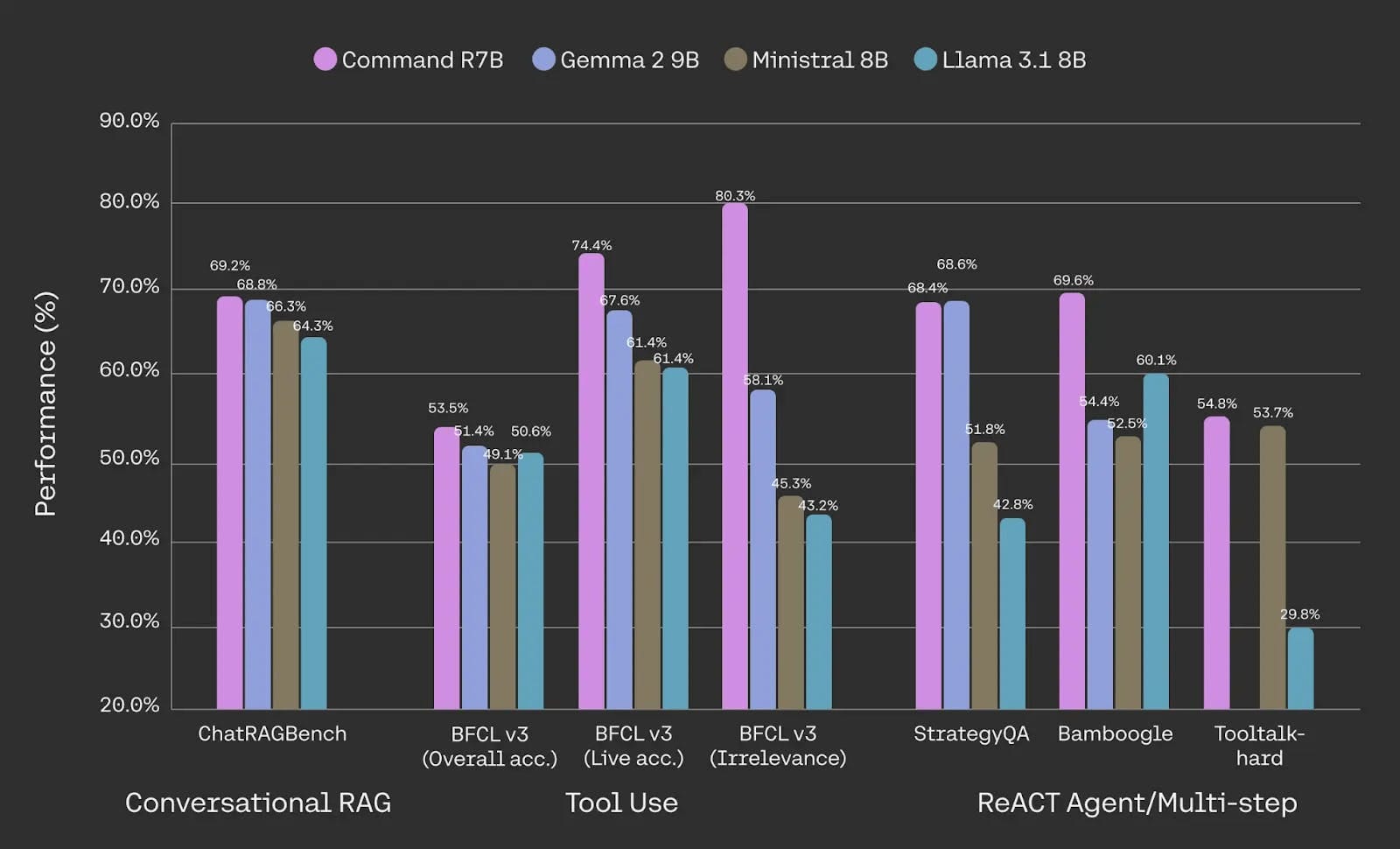
The model is available on HuggingFace here.
Start building with Command R7B today →
Thanks to Cohere for partnering with us today and showing us their latest developments.
Train classical ML models on large datasets
This is the list of sklearn implementations that support a batch API:

It’s pretty small, isn’t it?
This is concerning since, in the enterprise space, the data is primarily tabular.
Classical ML algorithms, such as tree-based ensemble methods, are frequently used for modeling.
However, typical implementations of these models are not “big-data-friendly” because they require the entire dataset to be in memory.
There are two ways to approach this:
The first way is to use big-data frameworks like Spark MLlib to train them. We covered this in detail in this full crash course (102 mins read).
There’s one more way: Random Patches, proposed in the Understanding Random Forests thesis.
Random Patches
Note: This approach will only work in an ensemble setting. So, you would have to train multiple models.
The idea is to sample random data patches (rows and columns) and train a tree model on each patch.
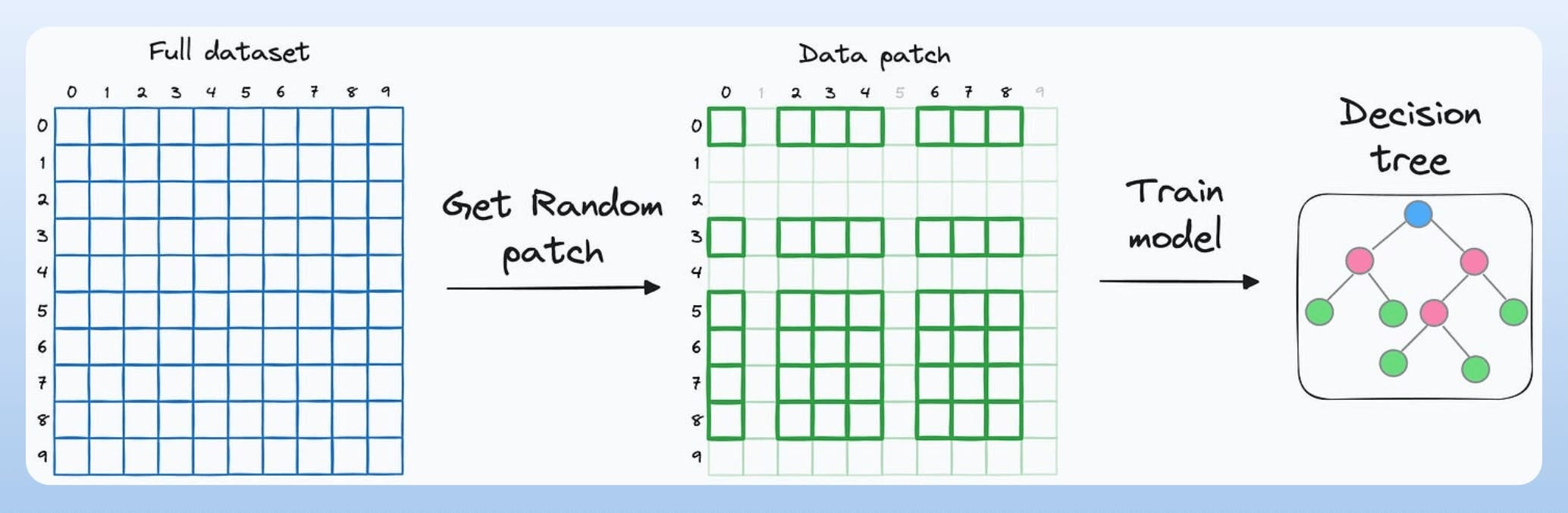
Repeat this step multiple times by randomly generating different data patches to obtain the entire random forest model.
These are the results mentioned in the thesis (check pages 174 and 178) on 13 datasets:
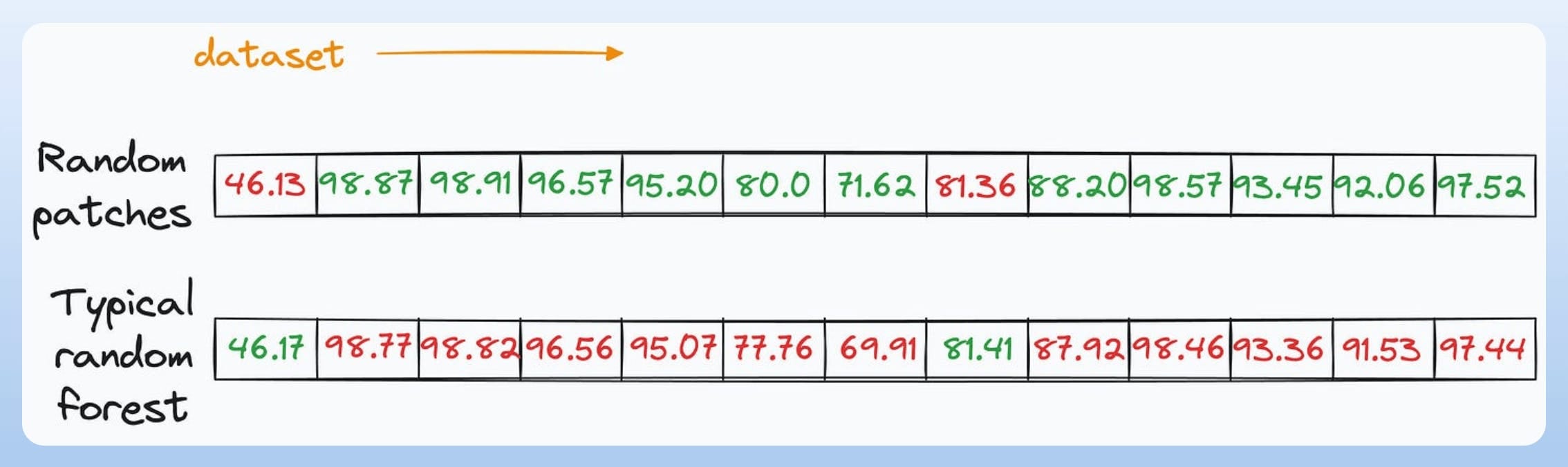
In most cases, the random patches approach performs better than the traditional random forest.
In other cases, there is a marginal difference in performance.
And this is how we can train a random forest model on large datasets that do not fit into memory.
Why does it work?
The idea is similar to what we discussed when we covered Bagging, which eventually allowed us to build our own variant of the Bagging algorithm: Why Bagging is So Ridiculously Effective At Variance Reduction?
In a gist, building trees that are as different as possible guarantees a greater reduction in variance.
In this case, the dataset overlap between two trees will be less than that in a typical random forest.
This aids in the Bagging objective and leads to a more robust model.
To understand this mathematically, read this: Why Bagging is So Ridiculously Effective At Variance Reduction?
👉 Over to you: Do you know any other way to train a random forest on a large dataset?
Also, talking of trees, here's something equally interesting👇
Formulating and Implementing XGBoost From Scratch
If you consider the last decade (or 12-13 years) in ML, neural networks have dominated the narrative in most discussions.
In contrast, tree-based methods tend to be perceived as more straightforward, and as a result, they don't always receive the same level of admiration.
However, in practice, tree-based methods frequently outperform neural networks, particularly in structured data tasks.

This is a well-known fact among Kaggle competitors, where XGBoost has become the tool of choice for top-performing submissions.
One would spend a fraction of the time they would otherwise spend on models like linear/logistic regression, SVMs, etc., to achieve the same performance as XGBoost.
Learn about its internal details by formulating and implementing it from scratch here →