
Train Classical ML Models on Large Datasets
Extend the Bagging objective to any ML algorithm.

An open-source alternative to Anthropic’s most viral feature!
Until now, Anthropic’s Generative UI capabilities only existed inside its own products.
Open Generative UI by CopilotKit is an open-source implementation of that same pattern that works in any app.
The agent generates HTML/SVG at runtime, and CopilotKit streams it token-by-token into a sandboxed iframe inside the app’s chat.
So the user can watch the UI assemble itself in real time, not after the full response is ready.
The sandbox is fully isolated with no access to the parent app, the DOM, or user data. So if the agent hallucinates broken markup or unexpected JavaScript, nothing leaks outside the iframe.
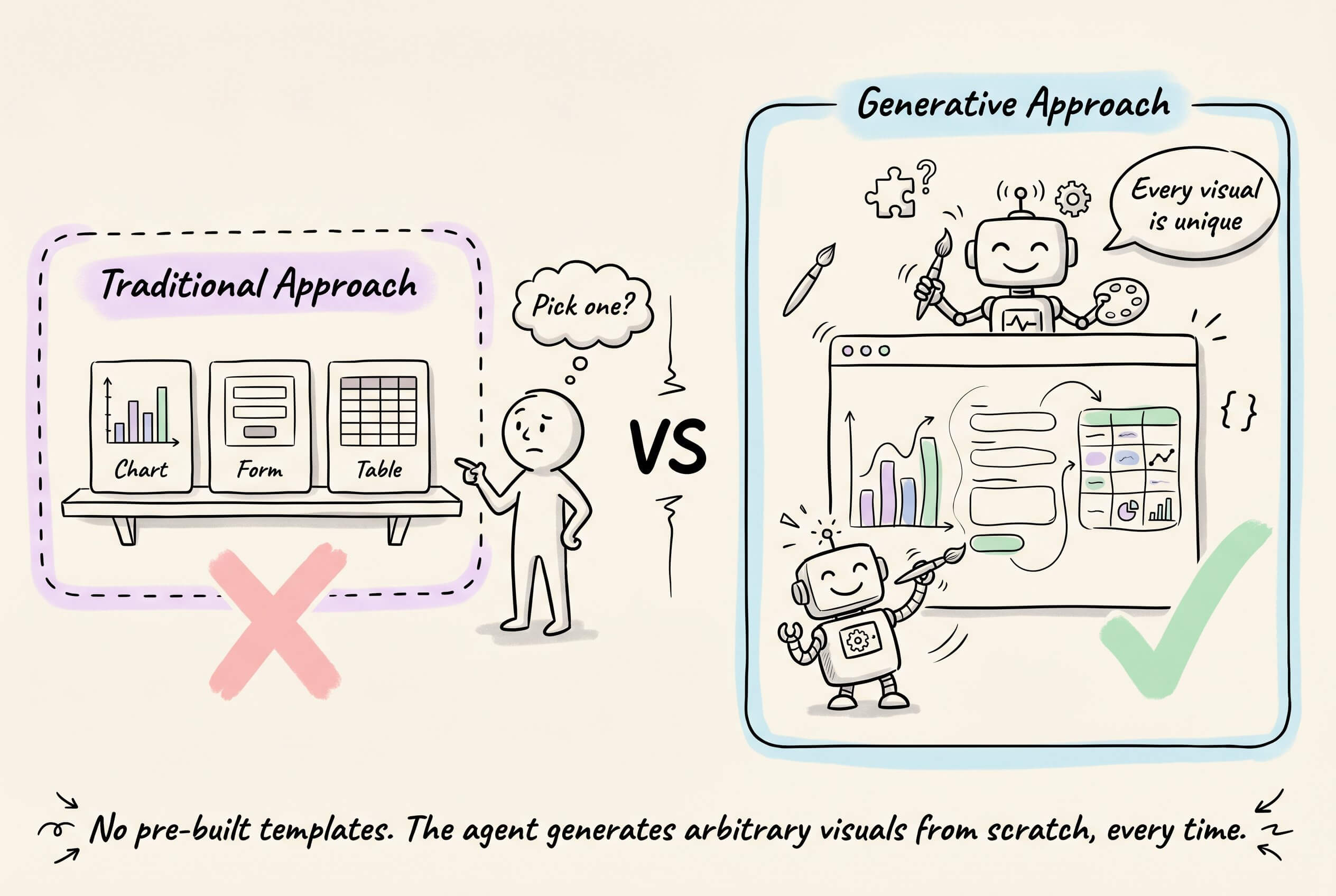
Under the hood, the agent does not select from pre-built components. Instead, it generates arbitrary visuals from scratch every time.
The output is unconstrained by default, but you can shape it by defining prompt-based skills that teach the agent specific visual formats or guidelines.
For instance, a skill prompt can guide the agent toward producing a Chart.js dashboard with proper axis labels and responsive sizing, or an interactive 3D model with rotation controls.
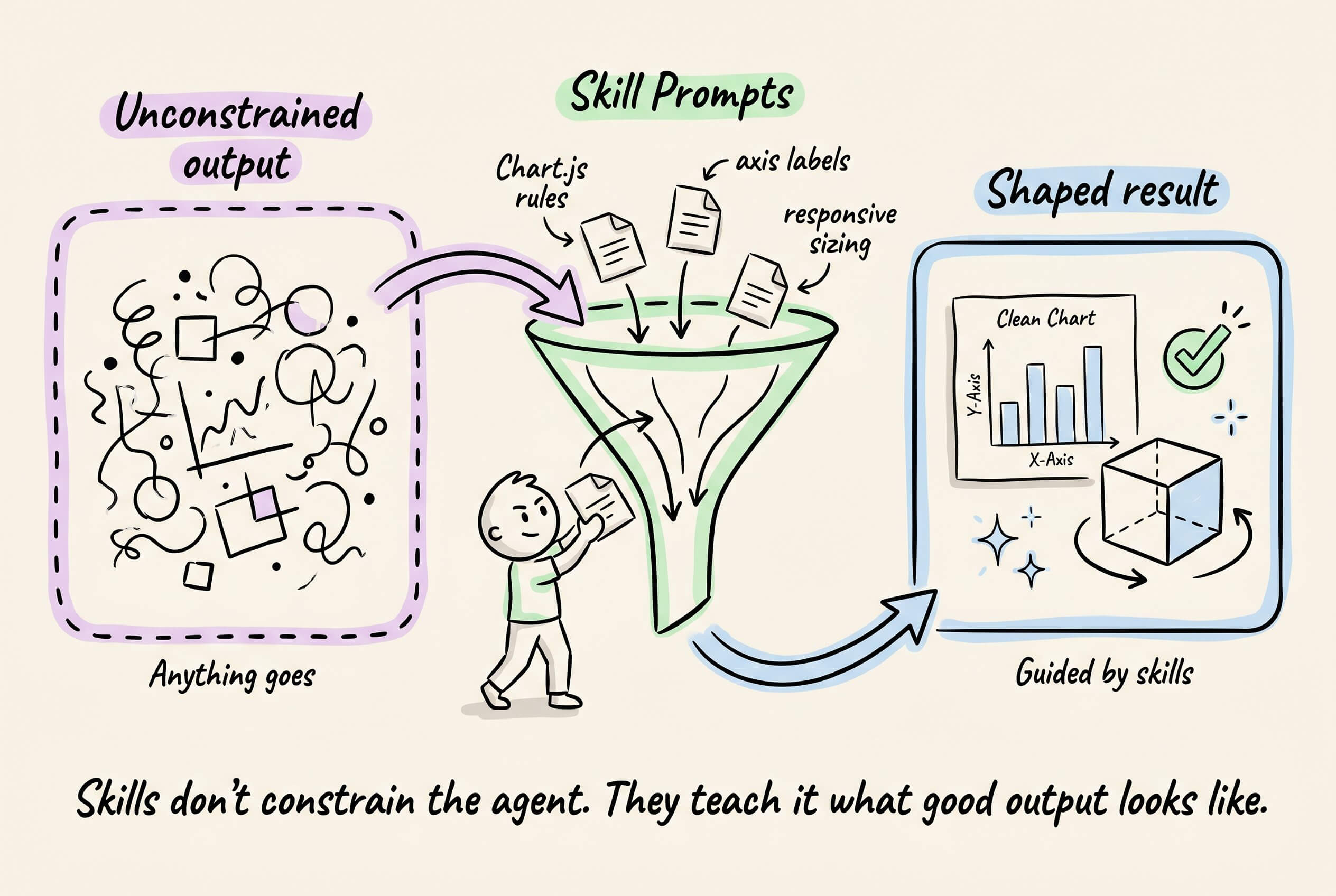
The graphic below depicts this, and the output quality you see actually comes from the skills layer.
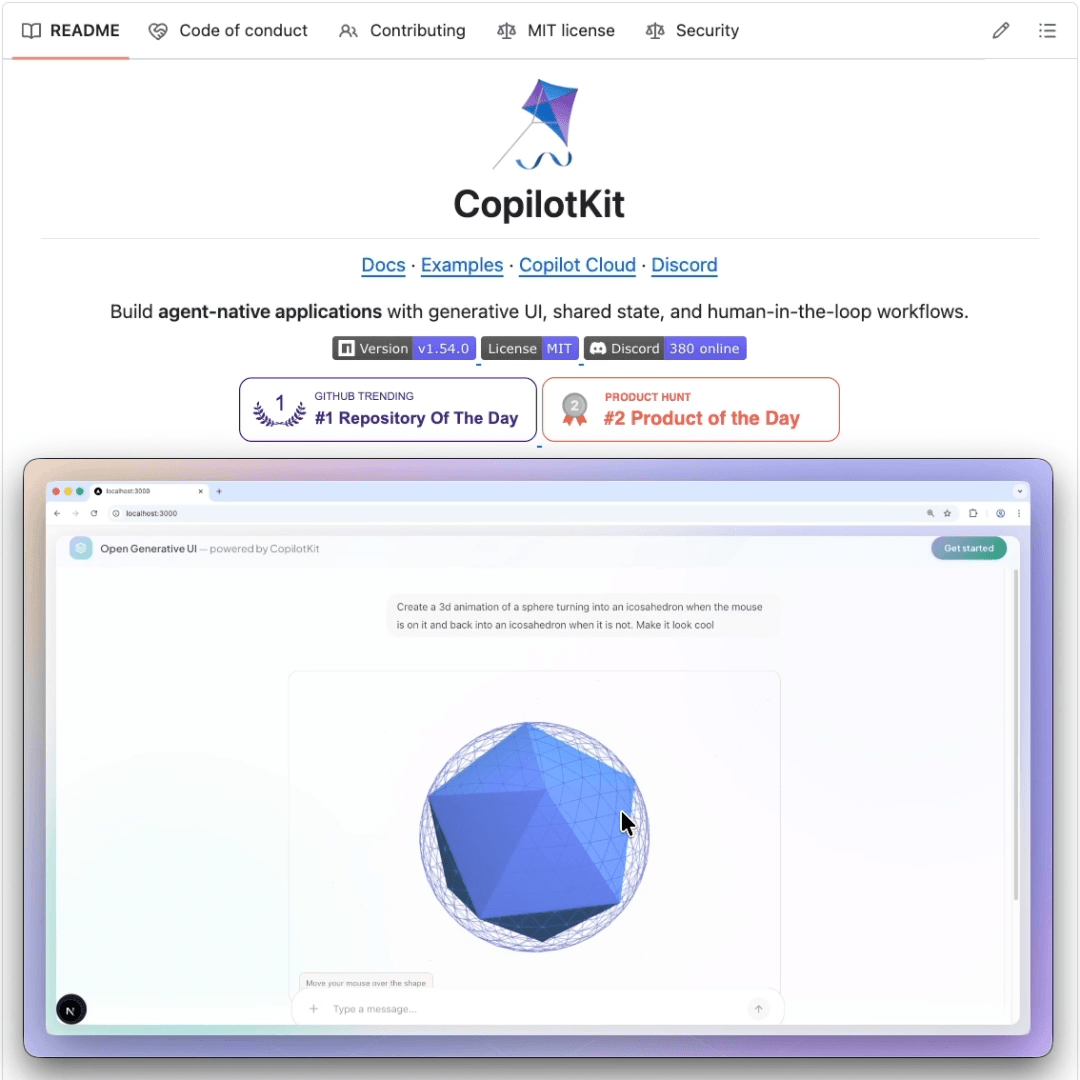
Open Generative UI runs on AG-UI, so it works out of the box with LangGraph, CrewAI, Mastra, Google ADK, AWS Strands, and more.
It also ships with a standalone MCP server that plugs into Claude Code, Cursor, or any MCP-compatible client.
And the entire stack is built on top of CopilotKit, the open-source frontend framework for agents and generative UI. 30k+ GitHub stars, with SDKs for React, Next.js, Angular, and Vue.
Here’s a live demo gallery if you want to test this yourself →
CopilotKit GitHub repo (30k+ stars) →
Train classical ML models on large datasets
The list of sklearn implementations that support a batch API is quite small:

This is concerning since, in the enterprise space, the data is primarily tabular.
Classical ML algorithms, such as tree-based ensemble methods, are frequently used for modeling.
However, typical implementations of these models are not “big-data-friendly” because they require the entire dataset to be in memory.
There are two ways to approach this:
The first way is to use big-data frameworks like Spark MLlib to train them. We covered this in detail →
There’s one more way: Random Patches. Let’s learn below.
Random Patches
Note: This approach will only work in an ensemble setting. So, you would have to train multiple models.
The idea is to sample random data patches (rows and columns) and train a tree model on each patch.
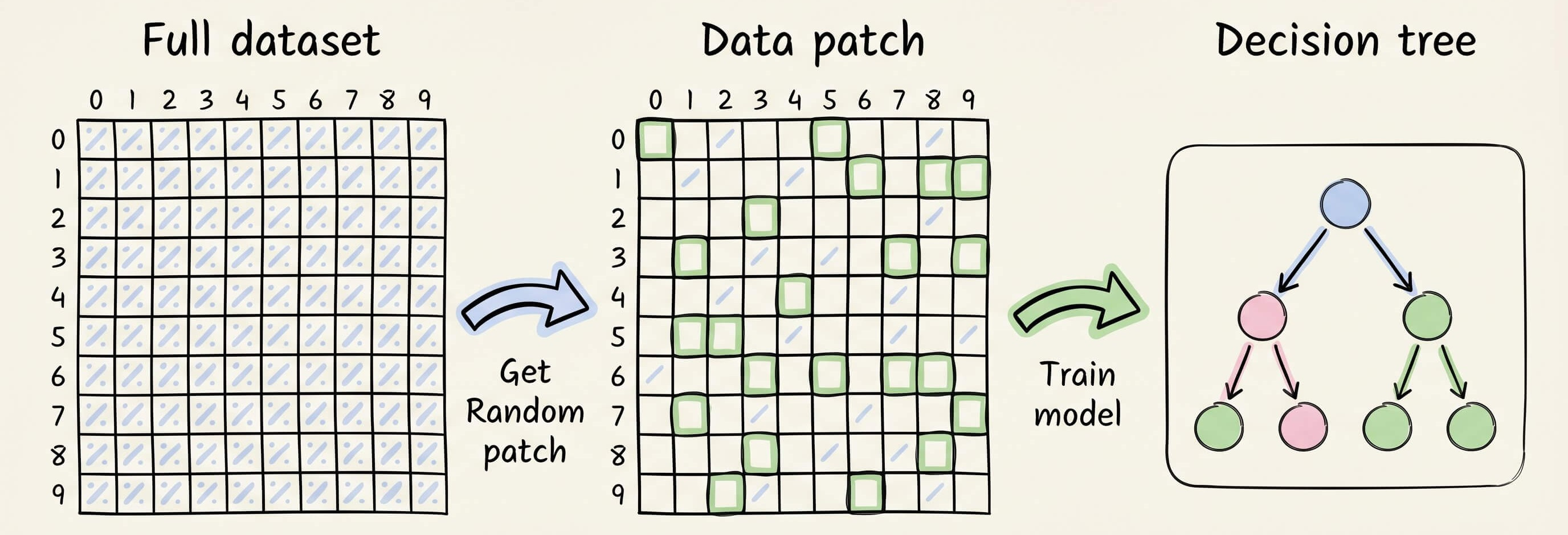
Repeat this step multiple times by randomly generating different data patches to obtain the entire random forest model.
These are the results mentioned in the thesis (check pages 174 and 178) on 13 datasets:
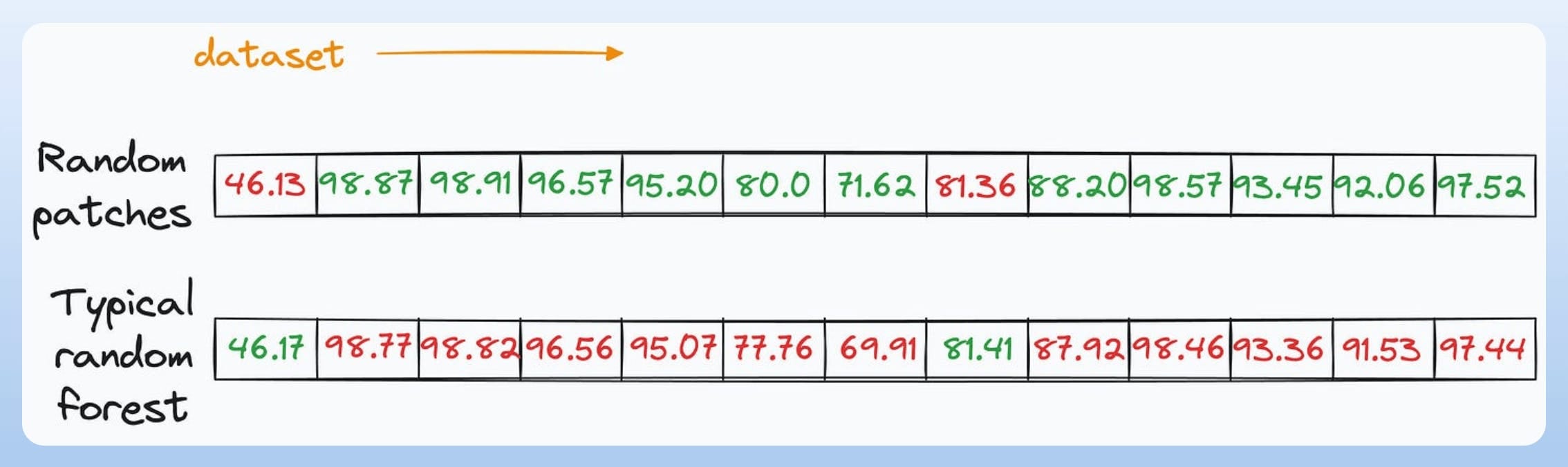
In most cases, the random patches approach performs better than the traditional random forest.
In other cases, there is a marginal difference in performance.
And this is how we can train a random forest model on large datasets that do not fit into memory.
Why does it work?
The idea is similar to what we discussed when we covered Bagging, which eventually allowed us to build our own variant of the Bagging algorithm: Why Bagging is so ridiculously effective at variance reduction?
In a gist, building trees that are as different as possible guarantees a greater reduction in variance.
In this case, the dataset overlap between two trees will be less than that in a typical random forest. This aids in the Bagging objective and leads to a more robust model.
To understand this mathematically, read this: Why Bagging is so ridiculously effective at variance reduction?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.