
Train Neural Nets 4-6x Faster!
Explained with code and visuals.

One model that transcribes speech across 99 languages
Training accurate speech-to-text models is challenging, since so many nuances go into the data, like accents, pauses, murmurs, multiple languages/speakers, etc.
Open-source models are great to experiment with, but scaling them to production means dealing with latency, infra work, updating the model, etc.
AssemblyAI’s Universal provides production-ready speech-to-text via a simple managed API endpoint that you can invoke in just 5 lines of code.
The latest update also supports 99 languages, with automatic language detection for all supported languages, and speaker diarization for 95 of them.
Here’s a snippet that depicts its usage on a multilingual audio file:

Processes 1 hr of speech in ~35 seconds.
Provides industry-leading accuracy of 93.3%.
Supports diarization to detect multiple speakers.
Trained on 12.5 million hours of multilingual data.
Detects languages automatically across 99 languages.
Thanks to AssemblyAI for partnering today!
Train neural nets 4-6x faster!
A simple technique trains neural nets 4-6x faster!
OpenAI used it in GPT models.
Meta used it in LLaMA models.
Google used it in Gemini models.
Let’s understand today, with code.
Typical deep learning frameworks are conservative when it comes to assigning data types.
The default data type is usually 64-bit or 32-bit, when they could have used 16-bit, for instance.
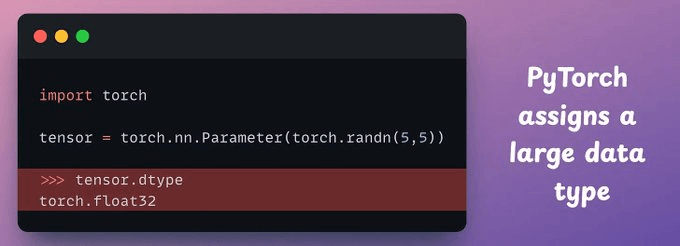
As a result, we are not entirely optimal at allocating memory.
Of course, this is done to ensure better precision in representing information.
However, this precision comes at the cost of memory utilization, which is not desired in all situations, as depicted below:
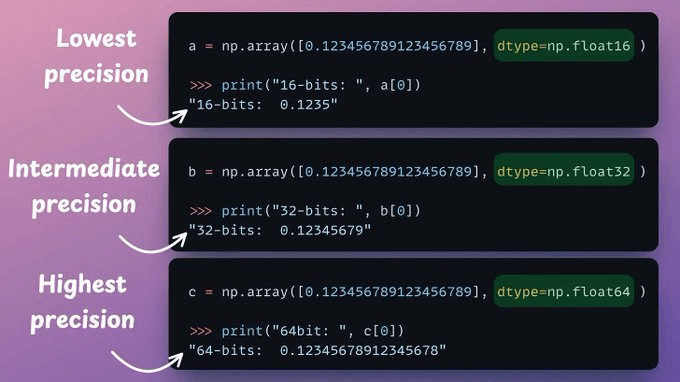
But the motivation to use lower precision isn't just memory reduction.
Many tensor operations, like matmuls, are significantly faster with lower precision, as depicted below:

This also allows us to train on larger mini-batches, resulting in even more speedup.
Mixed precision training is used to achieve this.
The idea is to employ lower precision float16 (like in convolutions and matmuls) along with float32.
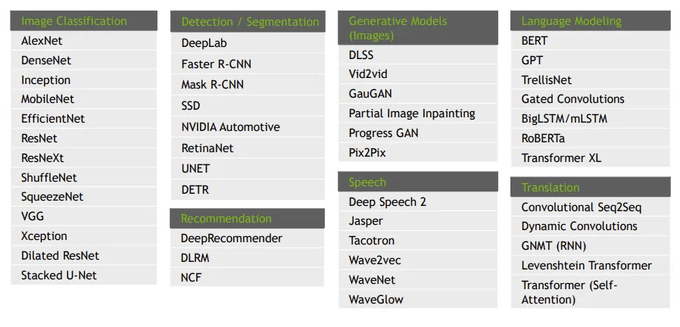
Here's a list of some models that were trained under mixed precision.
Here's a technical breakdown:
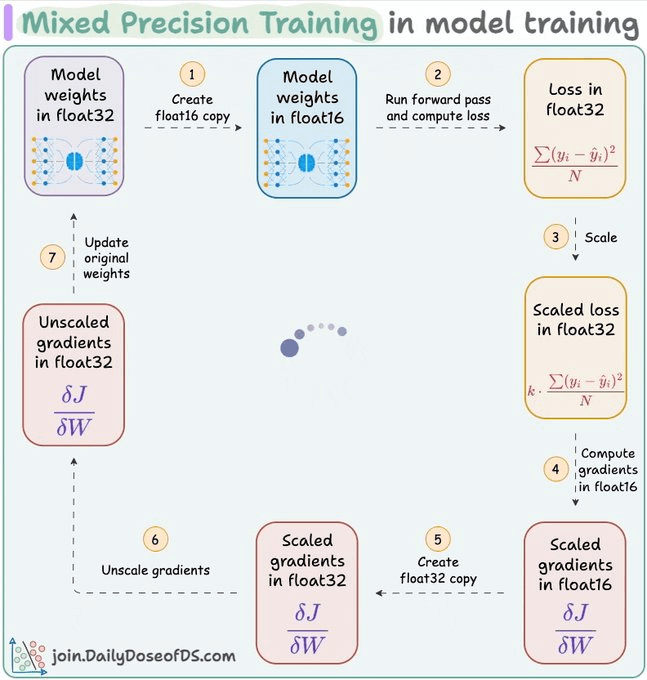
Make a f16 copy of weights during the forward pass.
Compute gradients in f16 is because, like forward pass, gradient computations also involve matmuls. Compute loss float32 and scale it to have more precision in gradients.
After computing gradients in f16, matmuls have been completed. Now we must update the original weight matrix, which is in f32.
Make a f32 copy of the above gradients, remove the scale we applied in Step 2, and update the f32 weights.
Let's dive into the code next!
Consider this is our current PyTorch model training implementation:

First, we use a scaler object that will scale the loss.
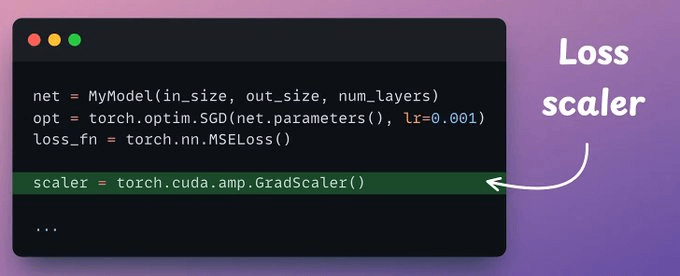
We do this because the original loss value can be so low and not captured in f16, producing no update during backprop.
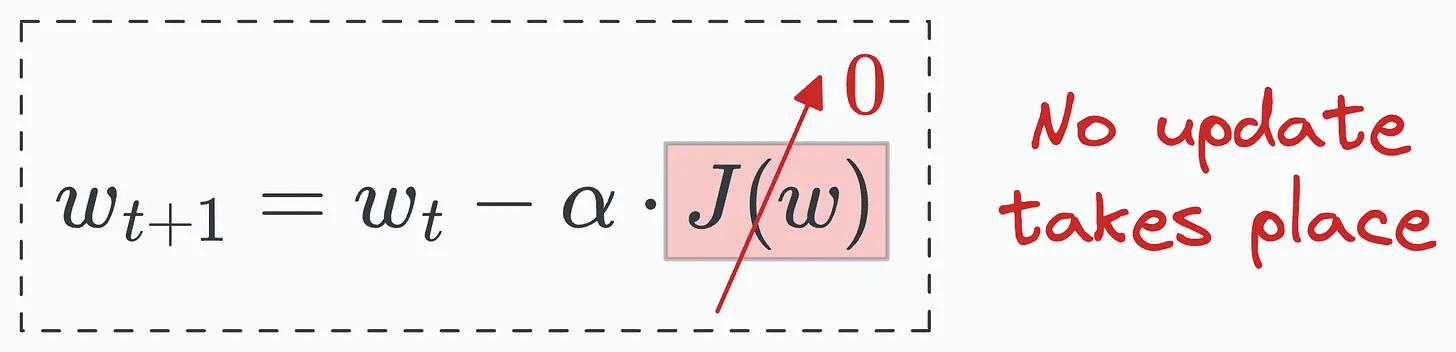
Scaling it ensures that even small gradients can contribute to the weight updates.
Next, mixed-precision settings in the forward pass are carried out by the torch.autocast() context manager.
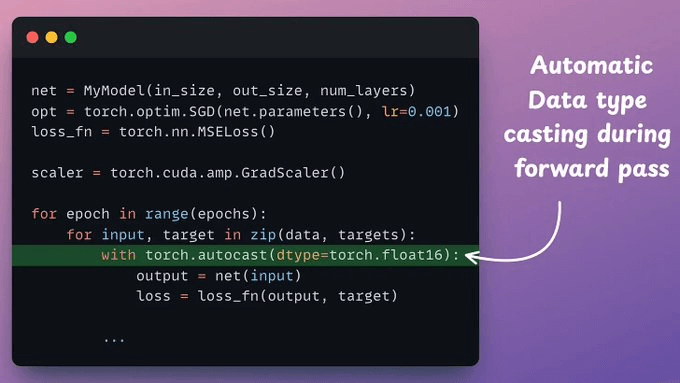
Now, it’s time to handle the backward pass:

Line 13 → Sales the loss value and compute the gradients.
Line 14 → Unscale gradients and update weights.
Line 15 → Update the scale for the next iteration.
Line 16 → Zero the gradients.
Done!
The efficacy of mixed precision scaling over traditional training is evident from the image below.

Mixed precision training is over 2.5x faster than conventional training in a mini neural network.
Typical speeds are 4-6x in bigger neural networks.
What other techniques are you aware of to optimize neural network training?
We covered 15 such techniques here (with implementation) →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
There is a typo in the loss computation of mixed precision. It must be loss calculated in float16 (same as weight’s precision) and then upscale it up float32.