
Training an LLM to Generate Reliable Structured Output
Full RL pipeline, explained with hands-on code.

CMU’s new study is a must-read for coding agent users.
They tracked 807 GitHub repos that adopted Cursor.
Each was matched against a similar repo that did not, so the difference reflects the agent, not the project.
In the first month after adoption, the agent-assisted repos added 3 to 5x more code. That gain was real but short-lived, and it faded within two months.

What did not fade was the hit to code quality.
Static analysis warnings rose around 30% and code complexity around 41%, and both stayed elevated for the rest of the study.
The obvious objection is that this is a skill problem, fixable with sharper prompts and review.
But even after controlling for how much code was added, complexity still climbed faster in the agent-assisted repos than in the controls. The agent adds to the problem, not just the developer using it.
The instinct is to have the agent review the code it just wrote, or add a second agent to check it.
That does not work as well as expected because the model that wrote the code carries the same blind spots that produced the defects.
A second model trained on similar data shares most of them, so an AI reviewer misses what the AI author missed.
Catching this reliably needs deterministic code analysis, which applies fixed rules instead of another probabilistic guess.
SonarQube actually implements this as a plugin inside Claude Code.
It runs deterministic verification in the session, flagging issues, complexity, and exposed secrets after every edit across the project.
For instance, in the video below, I typed a prompt with a GitHub token in it, and SonarQube blocked it before it reached Claude. The token never entered the context window.
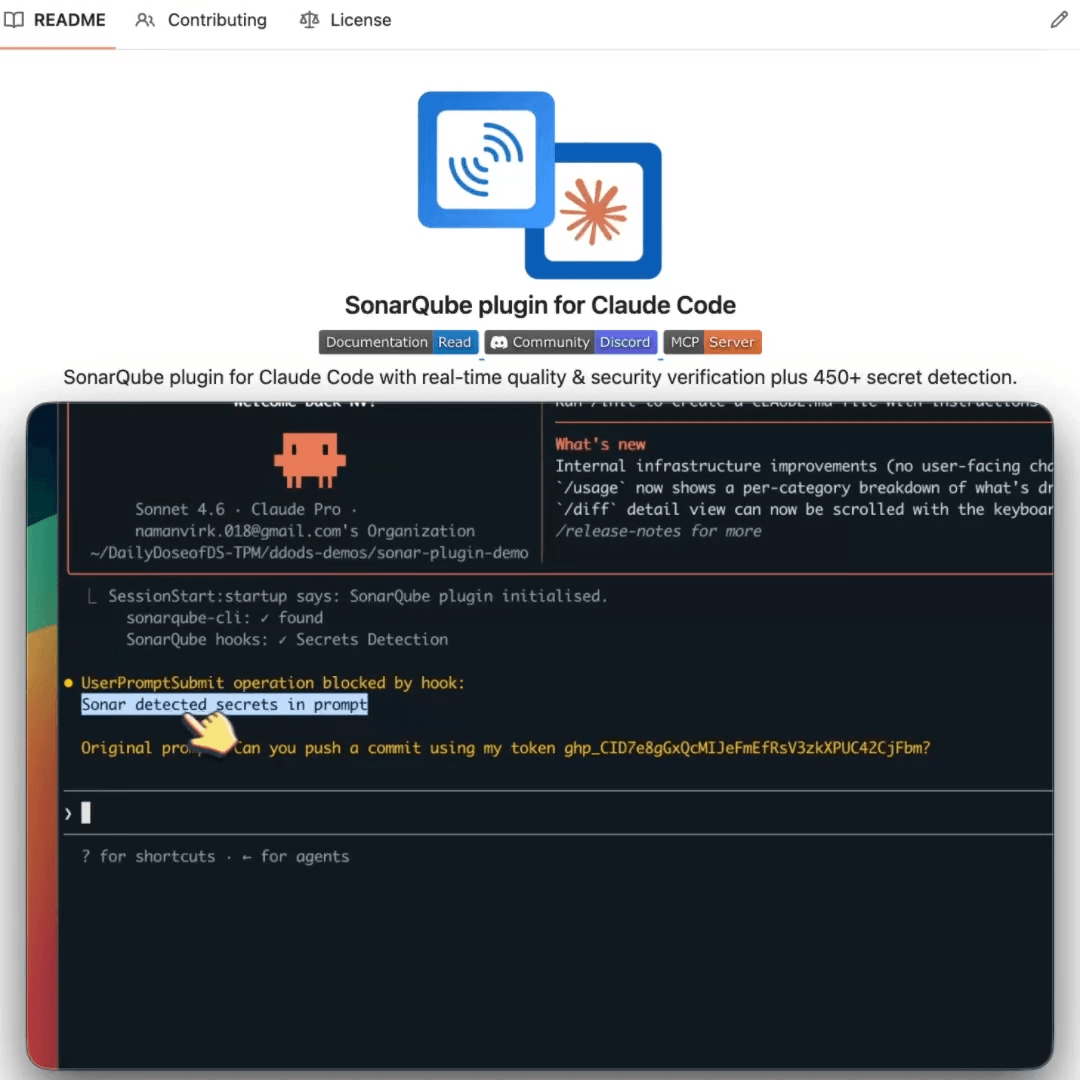
To get started in Claude Code, run /plugin, find sonarqube, install it, then run /sonarqube:integrate.
You can find the Claude plugin here →
Thanks to Sonar for partnering with us!
Training an LLM to generate reliable structured output
An LLM has no inherent concept of a parser. It predicts the next token from the ones before it, and well-formed JSON is only one of the continuations that fit this format.
So a number written as a string fits just as well, and so does an object with a line of explanation in front of it.
More examples and a tighter prompt do push the failure rate down, but then it stalls.
DeepSeek-R1 showed a way around this. Training a strong model used to mean annotation pipelines, preference pairs, and a team of labelers.
DeepSeek replaced all of it with one function that checks whether an answer is right. If you can define correctness via code, you do not need the rest.
That is the idea behind GRPO. Instead of learning from examples, the model learns from a reward function you write.
For each prompt, it generates a few candidate answers. The reward function scores them, and the model is pushed toward the ones that score higher.
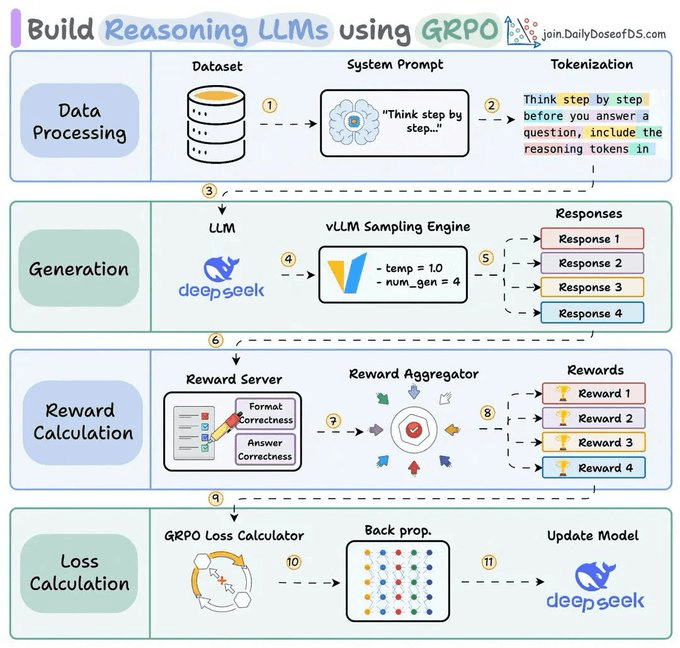
Today, let’s use this idea to fine-tune Qwen3-8B for JSON extraction. The loop runs from a local notebook while the model trains on remote H200s.
The reward function just checks whether each output parses and matches the schema.
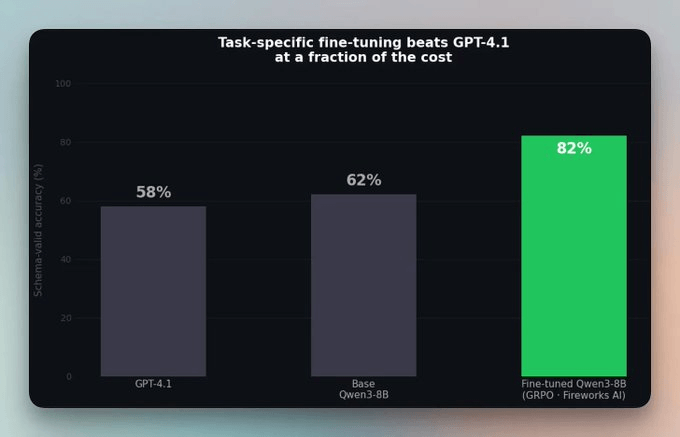
Schema-valid output went from 62% on the base model to 82% after training, past GPT-4.1 on the same eval at 58%.
Before we dive into code, let’s see why the obvious approach stalls.
Problems with SFT
SFT learns by copying examples. If you show it correct completions, it gets good at producing output that looks like them.
Notice the word “looks.”
This implies that looking like valid JSON and being valid JSON are different goals, and SFT only optimizes the first one.
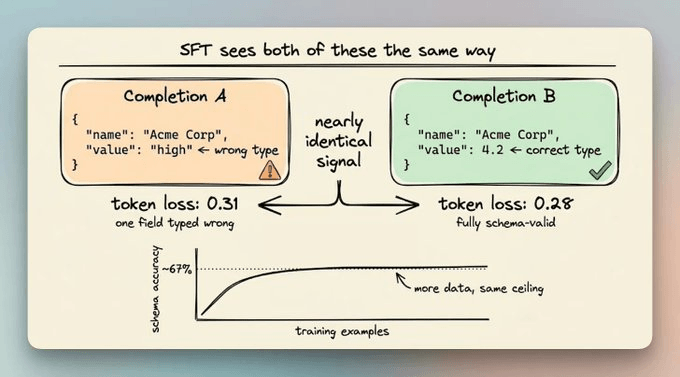
The loss is measured token by token, and a completion with one field typed wrong scores almost the same as a perfect one.
If you add more examples, the metrics do tick up, but then they flatten, because the limit is the objective, not the data.
Once you see the problem this way, the fix becomes immediately clear. You can define what “correct” means in code, and train the model against that definition directly.
This is what GRPO does.
It swaps labeled examples for a reward function. For each prompt, the model generates a small group of answers (usually 4-8). And then the reward function scores every one of them.
The scores are normalized inside the group. The model update then reinforces the answers that scored above the group’s average.
So the model is always comparing its own outputs against each other. It learns what “more correct” means for your task, not what “more similar to an example” means.
Here is how the reward function scores three different outputs for the same prompt:

Output that doesn’t parse as JSON scores 0.0.
Output that parses but fails the schema scores 0.5.
Output that parses and matches the schema scores 1.0.
That middle score is important because without it, valid JSON with the wrong field types would score zero, the same as complete garbage.
The model would lose an important signal that a valid structure is already progressing. The 0.5 is what gives training something to climb toward.
Infra for GRPO
GRPO is heavier than SFT. On an 8B model, it needs H200s and runs for hours.
Every step, it generates several completions per prompt, scores all of them, and updates the weights. That repeats across the whole dataset, many times over.
So this is not something you can run on your laptop.
There is also a timing problem that SFT never has.
During rollout, the model samples answers from its current weights. During training, those same weights are changing underneath it.
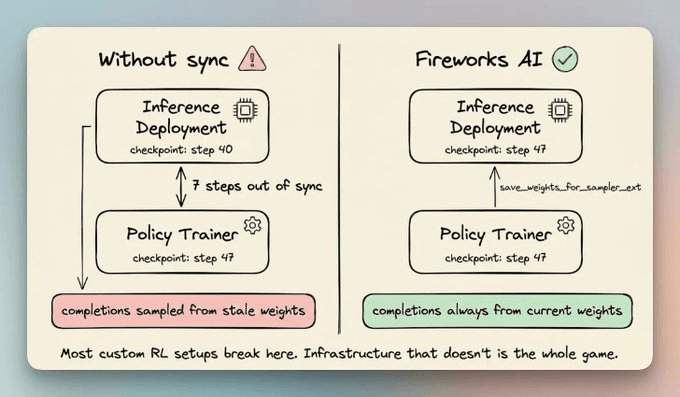
If the inference side and the trainer fall out of sync, you sample from a stale model and train on answers that the current one would never give. This is where most custom RL setups fall apart.
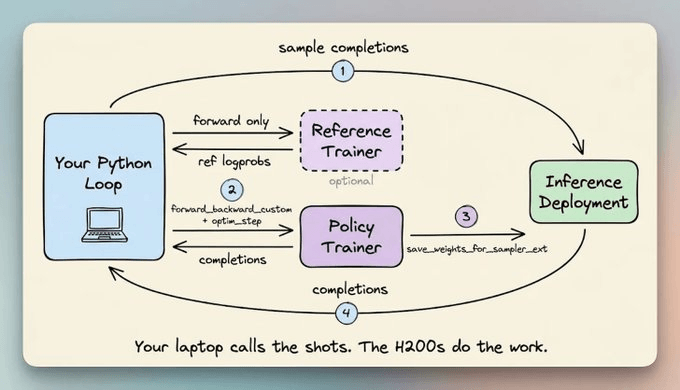
Fireworks’ Training API handles both sides. You can write the training logic in Python on your own machine, and the infrastructure handles the rest.
It provisions the GPUs, runs the forward and backward passes, saves checkpoints, and resyncs the inference deployment after every step.
The setup is three steps:
Write the reward function
Upload the dataset
And configure the run.
Let’s go through each one.
The training loop
Fireworks documents the full setup in their Training API docs. That includes rl_loop, the recipe that runs the entire GRPO loop.
Clone the cookbook and install the training dependencies:
git clone https://github.com/fw-ai/cookbook.git
cd cookbook/training && pip install -e ".[training]"
export FIREWORKS_API_KEY="your-training-scoped-key"Step 1: Write the Reward Function
This is the only place your task is defined. The SCHEMA says what a correct output looks like, and score() checks each completion against it.
For invoice extraction, we pull four fields from raw text: vendor, date, amount, and currency.
import json
from jsonschema import validate, ValidationError
SCHEMA = {
"type": "object",
"required": ["vendor", "date", "amount", "currency"],
"properties": {
"vendor": {"type": "string"},
"date": {"type": "string"},
"amount": {"type": "number"},
"currency": {"type": "string"},
},
"additionalProperties": False
}
def score(completion: str) -> float:
try:
parsed = json.loads(completion.strip())
except (json.JSONDecodeError, ValueError):
return 0.0
try:
validate(instance=parsed, schema=SCHEMA)
return 1.0
except ValidationError:
return 0.5jsonschema handles the type checks, the required fields, and any nested rules in a single call.
For a different task, like SQL or tool-call formatting, you can swap in a new schema. The score() function stays the same.
Step 2: Prepare the Dataset
GRPO does not need labeled outputs. The dataset is just the prompts you would send in production.
The model writes its own completions during training, and score() grades them as they come.
We used 200 training prompts. They cover different vendor names, date formats, amount styles, and currency codes. We also set aside 50 eval prompts.
Variety matters more than volume here. Prompts that all look alike produce a model that breaks on real invoice variation.
{
"messages": [
{
"role": "user",
"content": "Extract the following fields from this invoice:
Bill from Acme Corp, dated 2024-03-15, total $1,250.00 USD.
Return valid JSON only."
}
]
}
{
"messages": [
{
"role": "user",
"content": "Extract the following fields from this invoice:
Received from TechSupplies Inc on January 8 2024,
amount due: 340 euros. Return valid JSON only."
}
]
}Upload the dataset and wait for the READY state before the training job can use it.
from fireworks import Fireworks
client = Fireworks()
client.datasets.create(dataset_id="invoice-extraction-grpo-v1",
dataset={"exampleCount": "200"})
client.datasets.upload(dataset_id="invoice-extraction-grpo-v1",
file="./train_prompts.jsonl")
# poll client.datasets.get(...).state until "READY" before proceedingStep 3: Configure and Run the Loop
rl_loop runs the whole thing. It provisions the trainer, schedules the rollouts, syncs the weights, and cleans up when the run is done.
You connect your score() function by wrapping it and assigning it to rl_loop.reward_fn. The wrapper gets both the completion and the dataset row, so you can reach ground-truth metadata if your reward needs it.
from training.recipes.rl_loop import Config, main
from training.utils import DeployConfig, InfraConfig, WeightSyncConfig
import training.recipes.rl_loop as rl_loop
# Wire your reward function to the training loop
def invoice_reward(completion: str, row: dict) -> float:
return score(completion)
rl_loop.reward_fn = invoice_reward
cfg = Config(
base_model="accounts/fireworks/models/qwen3-8b",
dataset="invoice-extraction-grpo-v1",
max_rows=200,
epochs=1,
completions_per_prompt=4,
max_completion_tokens=256,
temperature=1.0,
max_seq_len=4096,
policy_loss="grpo",
output_model_id="invoice-extractor-v1",
infra=InfraConfig(
training_shape_id="accounts/fireworks/trainingShapes/qwen3-8b-128k",
),
deployment=DeployConfig(
deployment_id="invoice-extractor-v1",
tokenizer_model="Qwen/Qwen3-8B",
),
weight_sync=WeightSyncConfig(weight_sync_interval=1),
)
main(cfg)A few of these settings to note here:
datasetpoints to thedataset_iduploaded in Step 2. Fireworks pulls it from their storage directly.completions_per_prompt=4sets the group size for GRPO. Production runs often use 8 to 16, which gives more signal per step at a higher compute cost. Four is enough here. The reward is clear-cut enough that even a small group shows real variance between answers.weight_sync_interval=1resyncs the inference deployment after every step. That keeps rollout sampling from the exact model being trained. Production runs often set this to 4 or 8 for speed. For a short 200-step run, 1 gives the tightest feedback loop, which is what you want.One Qwen3 quirk to handle here is that it defaults to thinking mode and adds
<think>...</think>blocks before the answer. Strip them at eval time withcontent.split(”</think>”)[-1].strip(). Suppress them in training by adding/no-thinkto the system prompt. Otherwise, the reward function reads the reasoning text instead of the JSON, and scores everything 0.0.
Results on the held-out eval
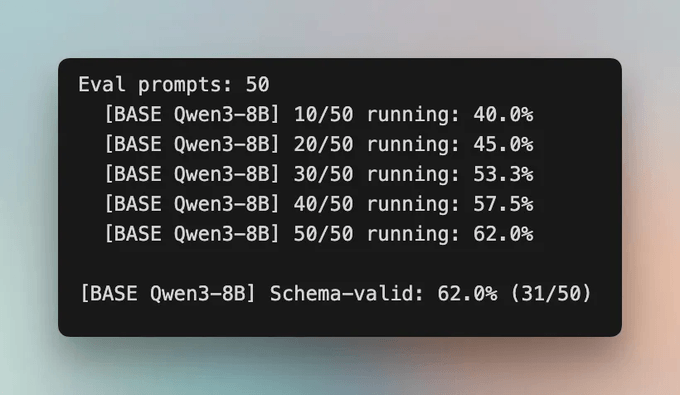
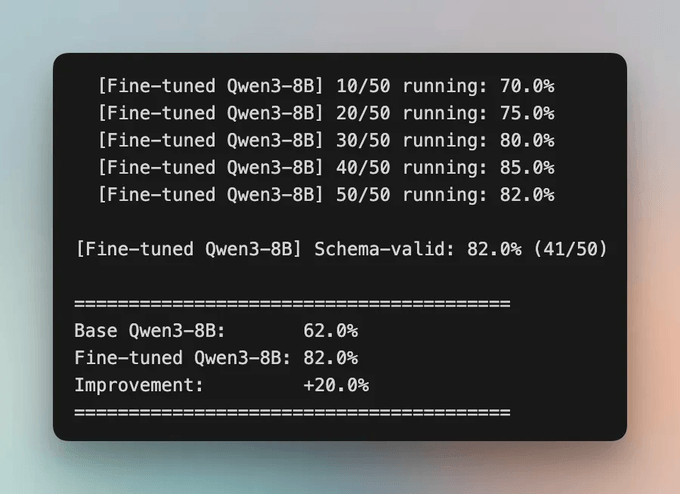
Base Qwen3-8B scores 62% schema-valid on the 50 held-out prompts. After GRPO training on Fireworks H200s, the fine-tuned model hits 82%.
That is past GPT-4.1 on the same eval, which lands at 58%.
Here is the baseline run first, on the 50 prompts the model never trained on.
And here is the same eval after training.
The trained model runs on a Fireworks serverless endpoint, at a fraction of GPT-4.1’s per-token cost. Latency is lower too, since the output is short and predictable.
The real difference shows up on messy inputs. A prompted general-purpose model starts to slip, while the trained model holds, because it learned the constraint instead of the examples.
This pattern works for any task where you can check correctness in code.
SQL that has to parse, API responses that must match a shape, tool calls, and code that has to pass a linter.
If you can score an output, you can train a model to chase that score.
What DeepSeek-R1 proved at the frontier scale holds for your own small task. The model you get has practiced your definition of correct, not memorized examples of it.
You can find the training API docs in this GitHub repo →
The full code is in the repo below. That includes the reward function, the training config, the dataset builder, and the eval script.
And you can find the finetuning code in our repo here →
Thanks for reading!