
Training and Inference Time Complexity of 10 Most Popular ML Algorithms
...in a single frame.

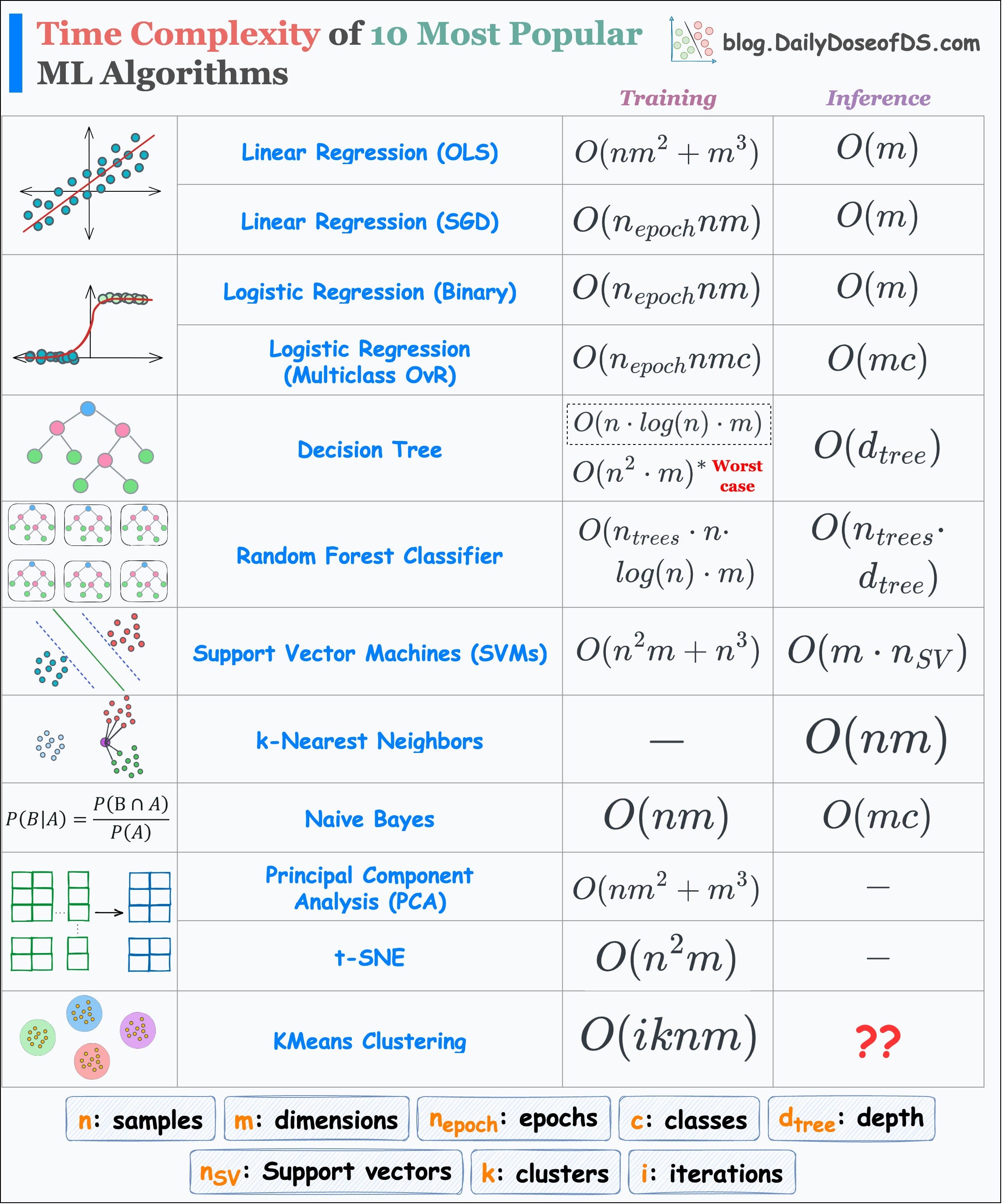
I prepared the following visual which depicts the run-time complexity of the 10 most popular ML algorithms.
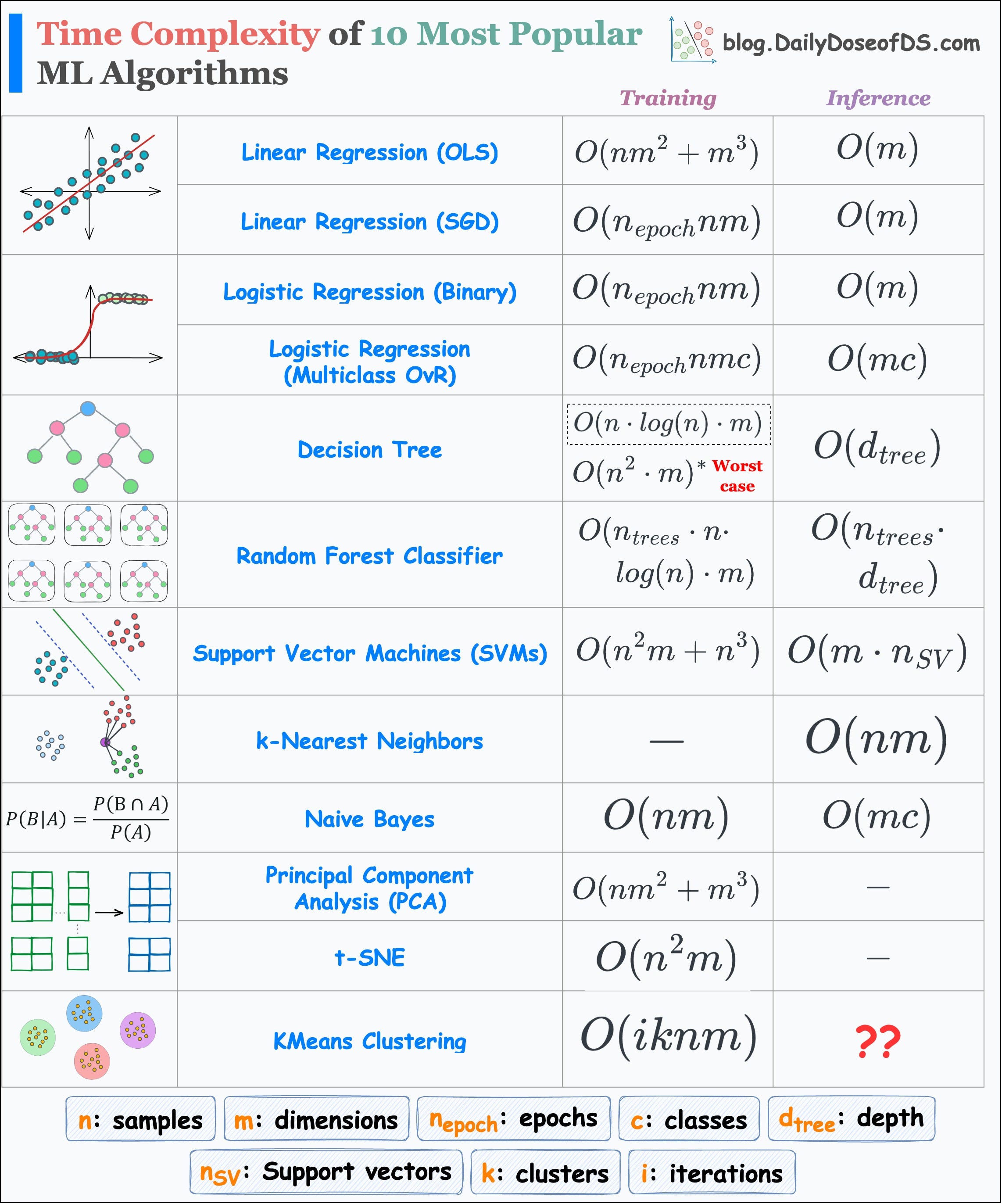
But why even care about run time?
There are multiple reasons why I always care about run time and why you should too.
To begin, we know that everyone is a big fan of sklearn implementations.
It literally takes just two (max three) lines of code to run any ML algorithm with sklearn.
Yet, in my experience, due to this simplicity, most users often overlook:
The core understanding of an algorithm.
The data-specific conditions that allow us to use an algorithm.
For instance, it makes no sense to use PCA when you have plenty of dimensions.

This is because PCA’s run-time grows cubically with dimensions.
Similarly, you are up for a big surprise if you use SVM or t-SNE on a dataset with plenty of samples.
SVM’s run-time grows cubically with the total number of samples.
t-SNE’s run-time grows quadratically with the total number of samples.
Another advantage of figuring out the run-time is that it helps us understand how an algorithm works end-to-end.
Of course, in the above table, I have made some assumptions here and there.
For instance:
In a random forest, all decision trees may have different depths. But here, I have assumed that they are equal.
During inference in kNN, we first find the distance to all data points. This gives a list of distances of size n (total samples).

Then, we find the k-smallest distances from this list.
The run-time to determine the k-smallest values may depend on the implementation.
Sorting and selecting the k-smallest values will be
O(nlogn).But if we use a priority queue, it will take
O(nlog(k)).
In t-SNE, there’s a learning step. However, the major run-time comes from computing the pairwise similarities in the high-dimensional space. You can learn how t-SNE works here: tSNE article.

Nonetheless, the table still accurately reflects the general run-time of each of these algorithms.
Today, as an exercise, I would encourage you to derive these run-time complexities yourself.
This activity will provide you so much confidence in algorithmic understanding.
If you get stuck, let me know.
👉 Over to you: Can you tell the inference run-time of KMeans Clustering?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!