
Transfer Learning, Fine-tuning, Multitask Learning and Federated Learning
Four critical model training paradigms that you MUST know for real-world ML modelling.

Here are some astonishing facts about code reviews:

~92% of developers are still doing code reviews manually.
Only 8% of developers are fully confident in doing code reviews.
~80% of developers wait more than one day for a review on their pull request.
Code review is a tedious job, and most developers are doing it the same way as 5 years ago.
Sourcery is making manual code reviews obsolete with AI.

Thus, every pull request instantly gets a human-like review from Sourcery with general feedback, in-line comments, and relevant suggestions.

What used to take over a day now takes a few seconds only.
Sourcery handles 500,000+ requests every month (reviews + refactoring + writing tests + documenting code, etc.) and I have been using it for over 1.5 years now.
Thanks to Sourcery for partnering with me today!
Let’s get to today’s post now.
Most ML models are trained independently without any interaction with other models.
However, in the realm of real-world ML, there are many powerful learning techniques that rely on model interactions to improve performance.
The following animation neatly summarizes four such well-adopted and must-know training methodologies:
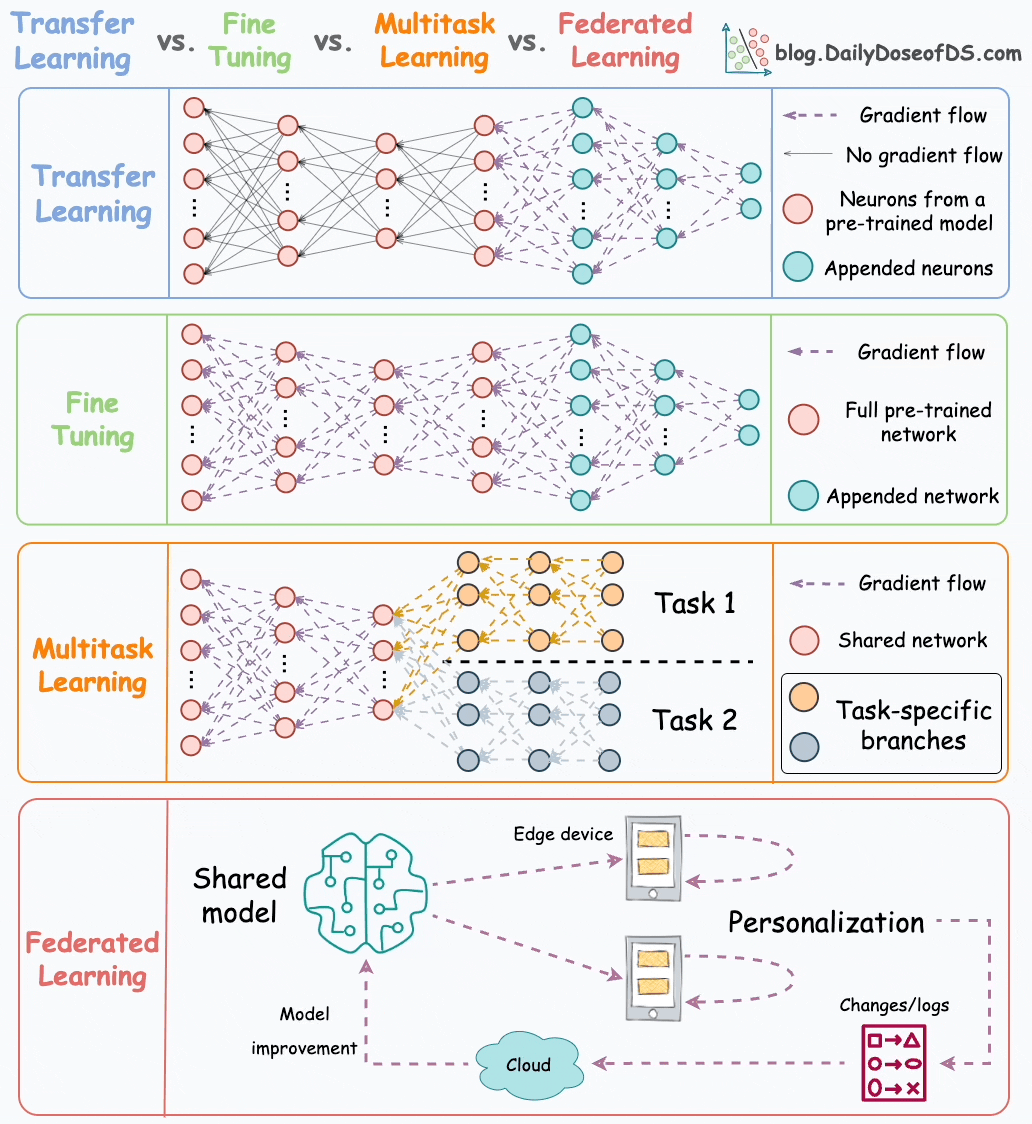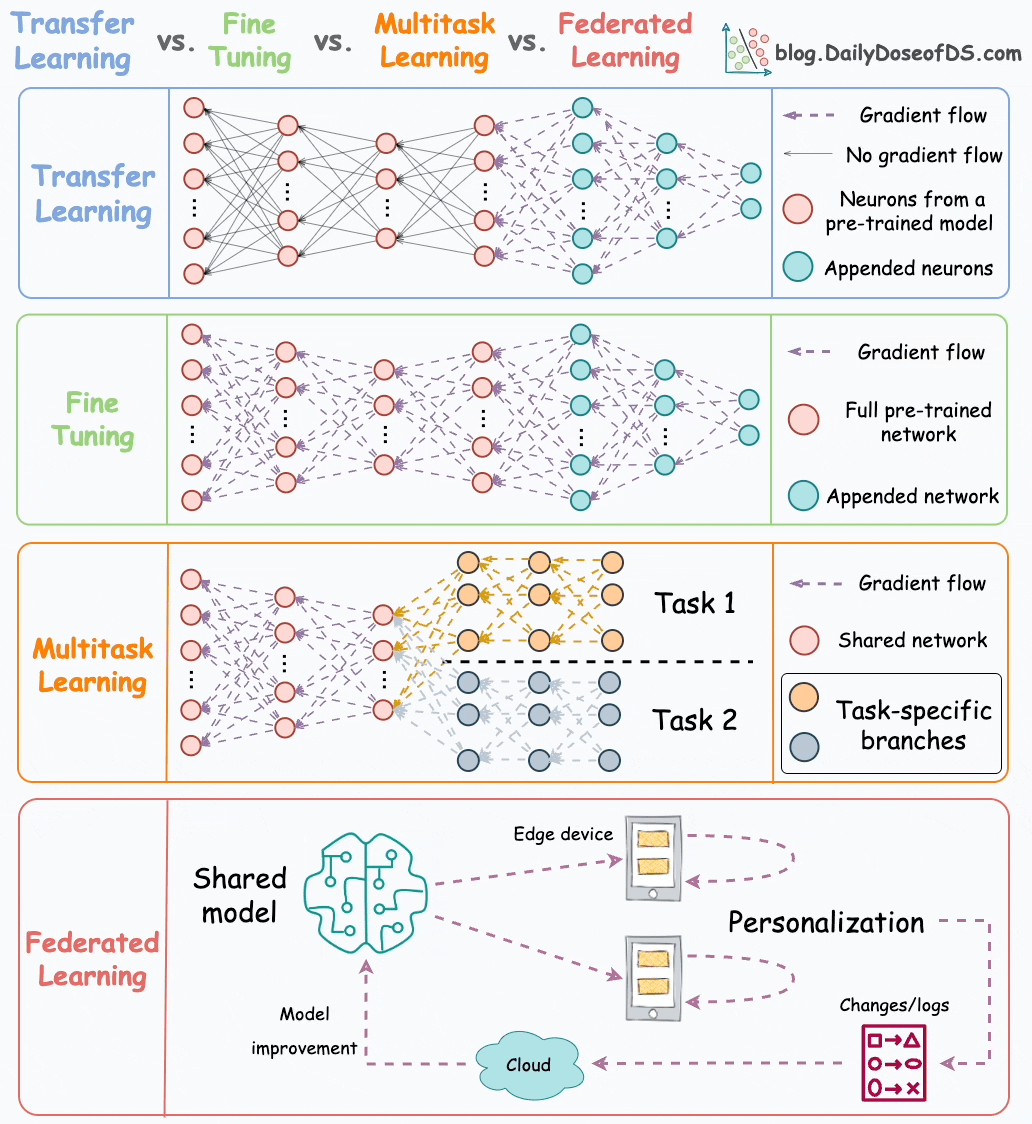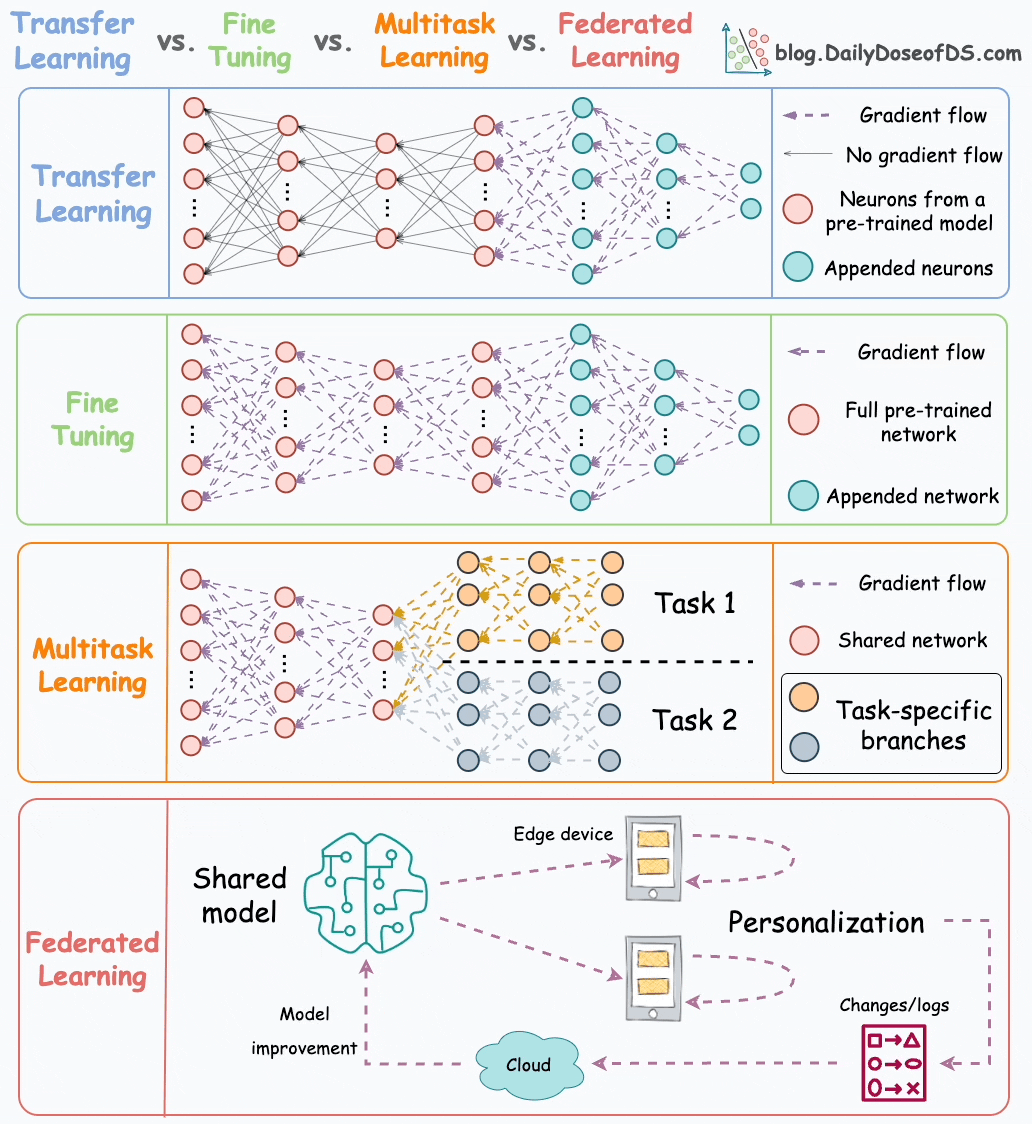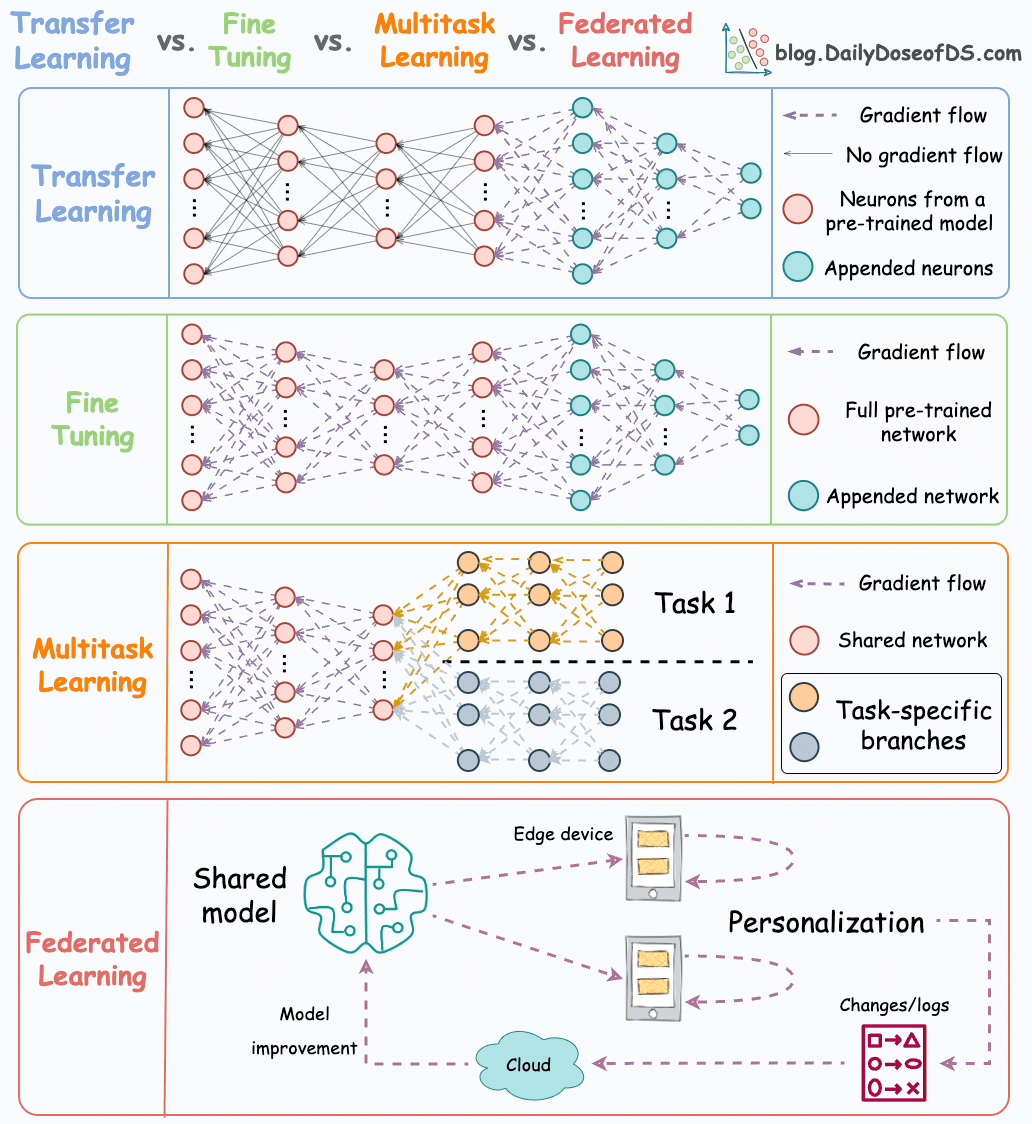
Let’s discuss them today.
#1) Transfer learning
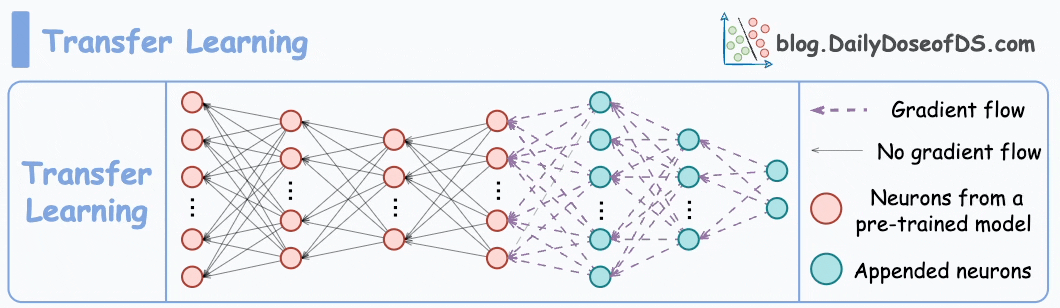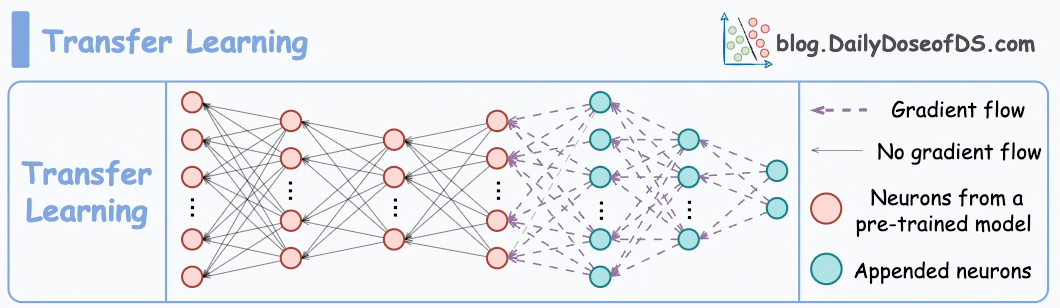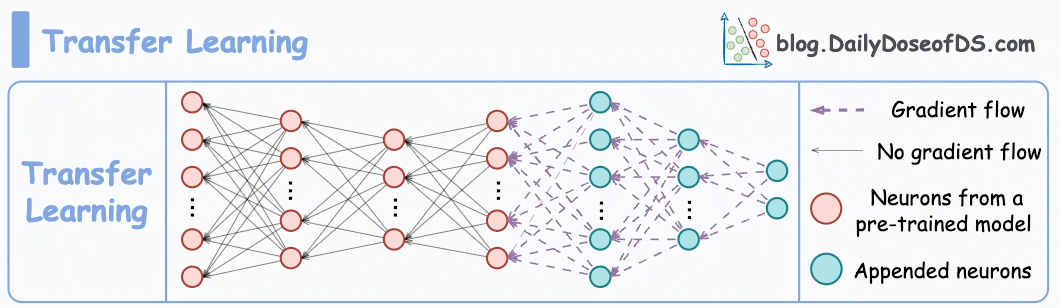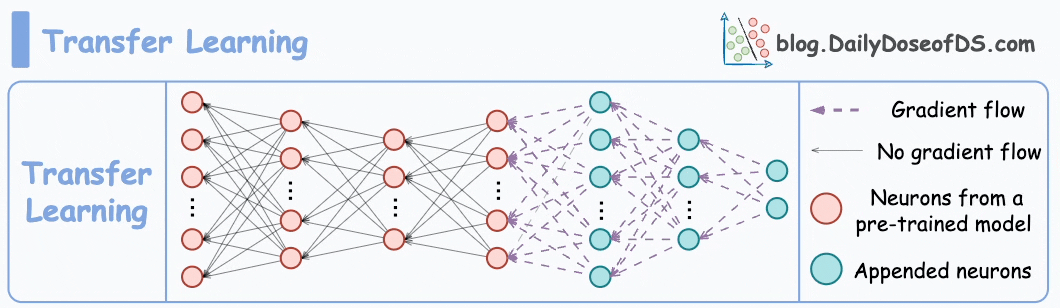
This is extremely useful when:
The task of interest has less data.
But a related task has abundant data.
This is how it works:
Train a neural network model (base model) on the related task.
Replace the last few layers on the base model with new layers.
Train the network on the task of interest, but don’t update the weights of the unreplaced layers during backpropagation.
By training a model on the related task first, we can capture the core patterns of the task of interest.
Later, we can adjust the last few layers to capture task-specific behavior.
Another idea which is somewhat along these lines is knowledge distillation, which involves the “transfer” of knowledge. We discussed it here if you are interested in learning about it.
Transfer learning is commonly used in many computer vision tasks.
#2) Fine-tuning
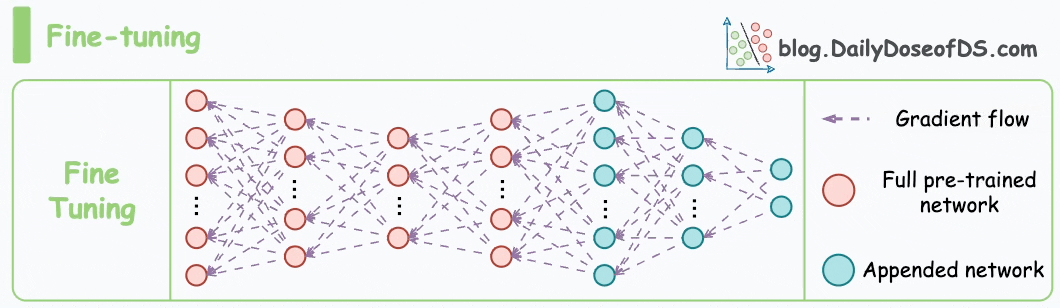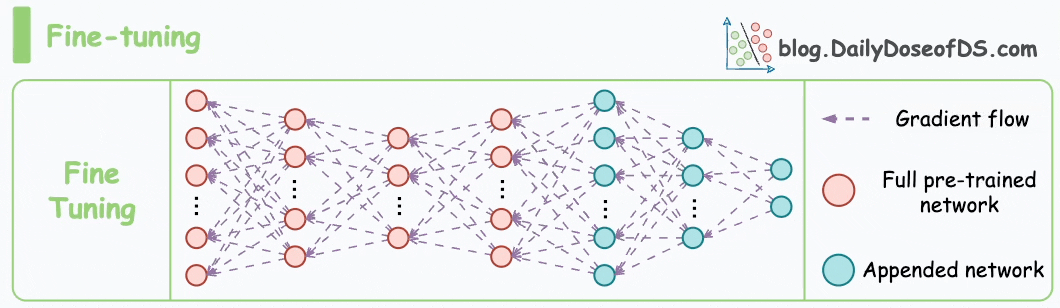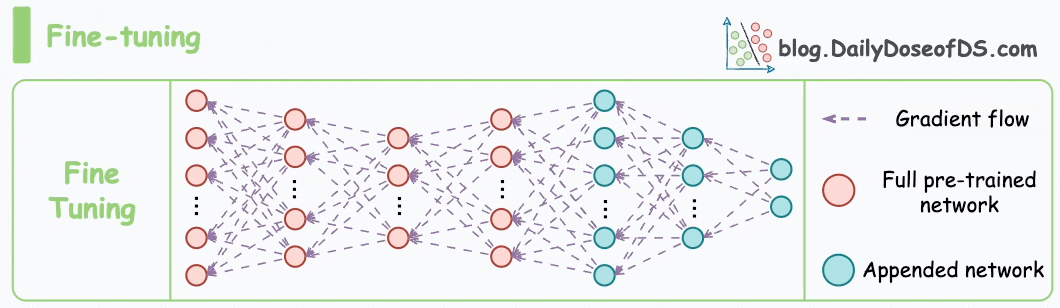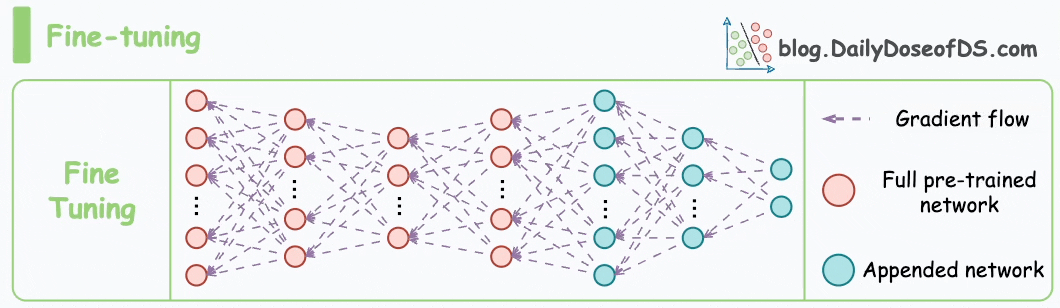
Fine-tuning involves updating the weights of some or all layers of the pre-trained model to adapt it to the new task.
The idea may appear similar to transfer learning, but in fine-tuning, we typically do not replace the last few layers of the pre-trained network.
Instead, the pretrained model itself is adjusted to the new data.
#3) Multi-task learning

As the name suggests, a model is trained to perform multiple tasks simultaneously.
The model shares knowledge across tasks, aiming to improve generalization and performance on each task.
It can help in scenarios where tasks are related, or they can benefit from shared representations.
In fact, the motive for multi-task learning is not just to improve generalization.
We can also save compute power during training by having a shared layer and task-specific segments.

Imagine training two models independently on related tasks.
Now compare it to having a network with shared layers and then task-specific branches.
Option 2 will typically result in:
Better generalization across all tasks.
Less memory utilization to store model weights.
Less resource utilization during training.
This and this are two of the best survey papers I have ever read on multi-task learning.
#4) Federated learning
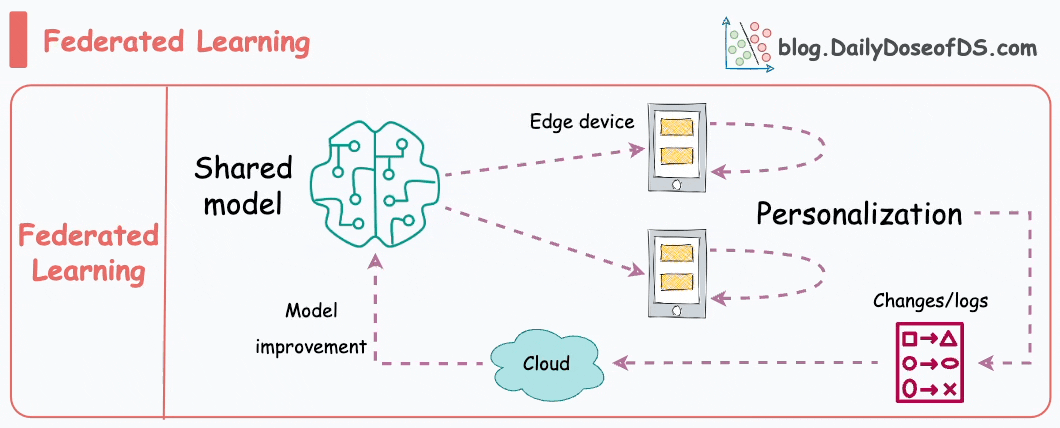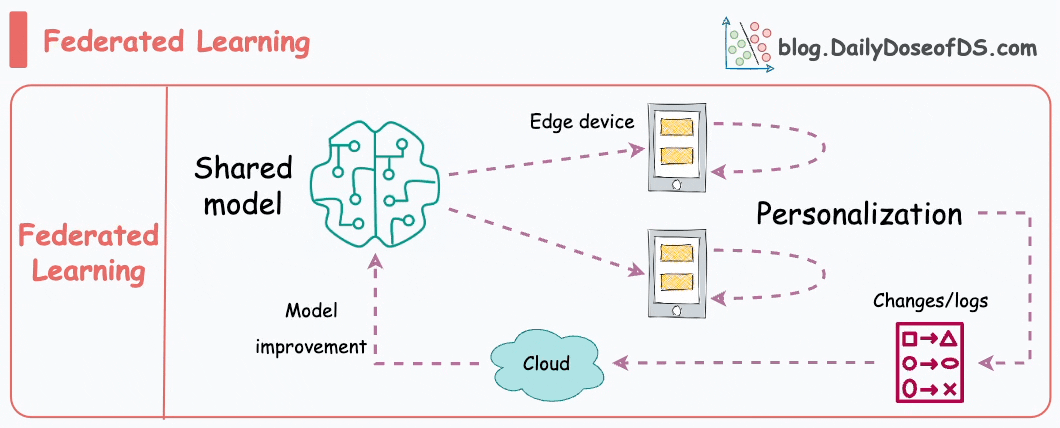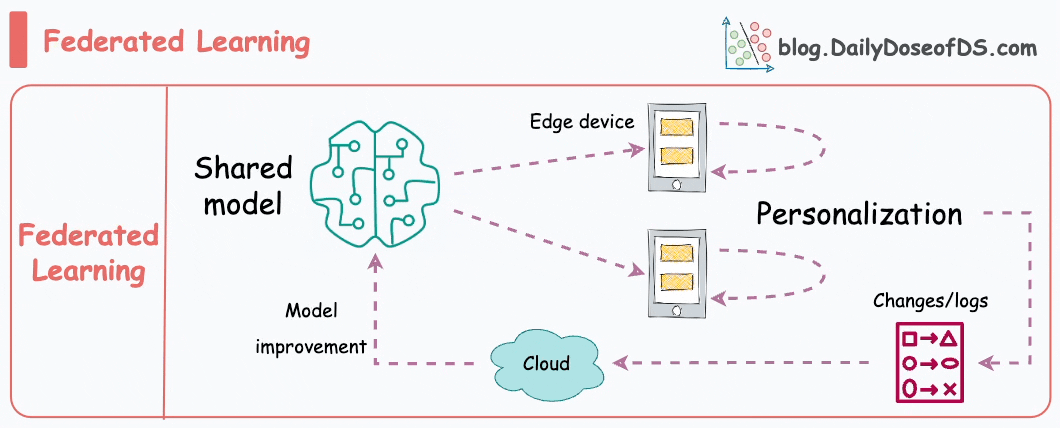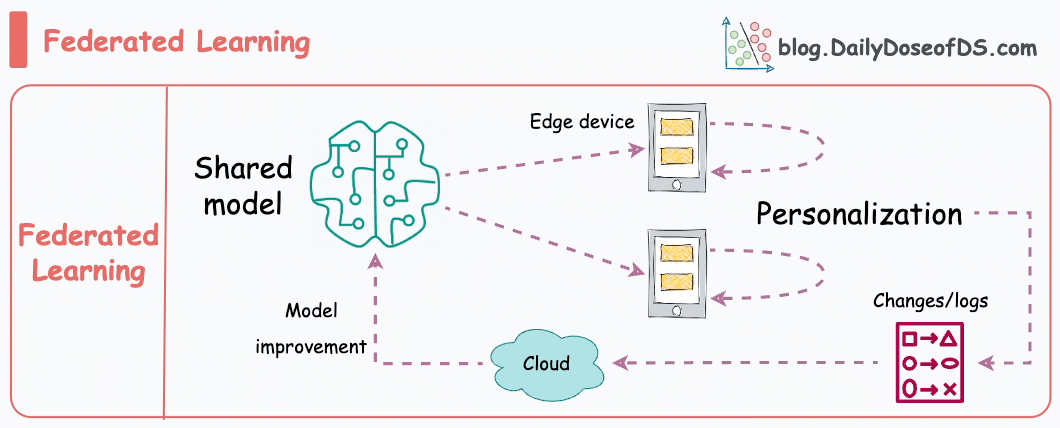
This is another pretty cool technique for training ML models.
Simply put, federated learning is a decentralized approach to machine learning. Here, the training data remains on the devices (e.g., smartphones) of users.
Instead of sending data to a central server, models are sent to devices, trained locally, and only model updates are gathered and sent back to the server.

It is particularly useful to enhance privacy and security. What’s more, it also reduces the need for centralized data collection.
The keyboard of our smartphone is a great example of this.
Federated learning allows our smartphone’s keyboard to learn and adapt to our typing habits. This happens without transmitting sensitive keystrokes or personal data to a central server.
The model, which predicts our next word or suggests auto-corrections, is sent to our device, and the device itself fine-tunes the model based on our input.
Over time, the model becomes personalized to our typing style while preserving our data privacy and security.
Do note that as the model is trained on small devices, it also means that these models must be extremely lightweight yet powerful enough to be useful.
We covered Federated learning in detail here: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Pretty cool, isn’t it?
👉 Over to you: What are some other ML training methodologies that I have missed here?
1 Referral: Unlock 450+ practice questions on NumPy, Pandas, and SQL.
2 Referrals: Get access to advanced Python OOP deep dive.
3 Referrals: Get access to the PySpark deep dive for big-data mastery.
Get your unique referral link:
Are you preparing for ML/DS interviews or want to upskill at your current job?
Every week, I publish in-depth ML deep dives. The topics align with the practical skills that typical ML/DS roles demand.
Join below to unlock all full articles:
Here are some of the top articles:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science.
5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
Join below to unlock all full articles:
👉 If you love reading this newsletter, share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
Thank you, just started with ML.
Muchas gracias desde Argentina!