
Transformer vs. Mixture of Experts in LLMs
...explained visually.

100% open-source serverless AI workflow orchestration

Julep AI is a serverless platform designed to help data and ML teams build intelligent workflows without the need to manage infrastructure.
Star the repo on GitHub (~5000 stars): GitHub repo.
Think of it as your control tower for orchestrating complex AI tasks—managing memory, state, parallel execution, and tool integration.
You just focus on creating smarter solutions and Julep does the heavy lifting.
Key features:
Smart memory: remembers context across interactions.
Workflow Engine: multi-step tasks with branching.
Parallel tasks: run operations simultaneously.
Seamlessly connects to external APIs.
Python & Node.js SDKs.
Real-time monitoring.
Reliable and secure.
Check it out below:
Thanks to Julep for partnering today!
Transformer vs. Mixture of Experts in LLMs
Mixture of Experts (MoE) is a popular architecture that uses different "experts" to improve Transformer models.
The visual below explains how they differ from Transformers.
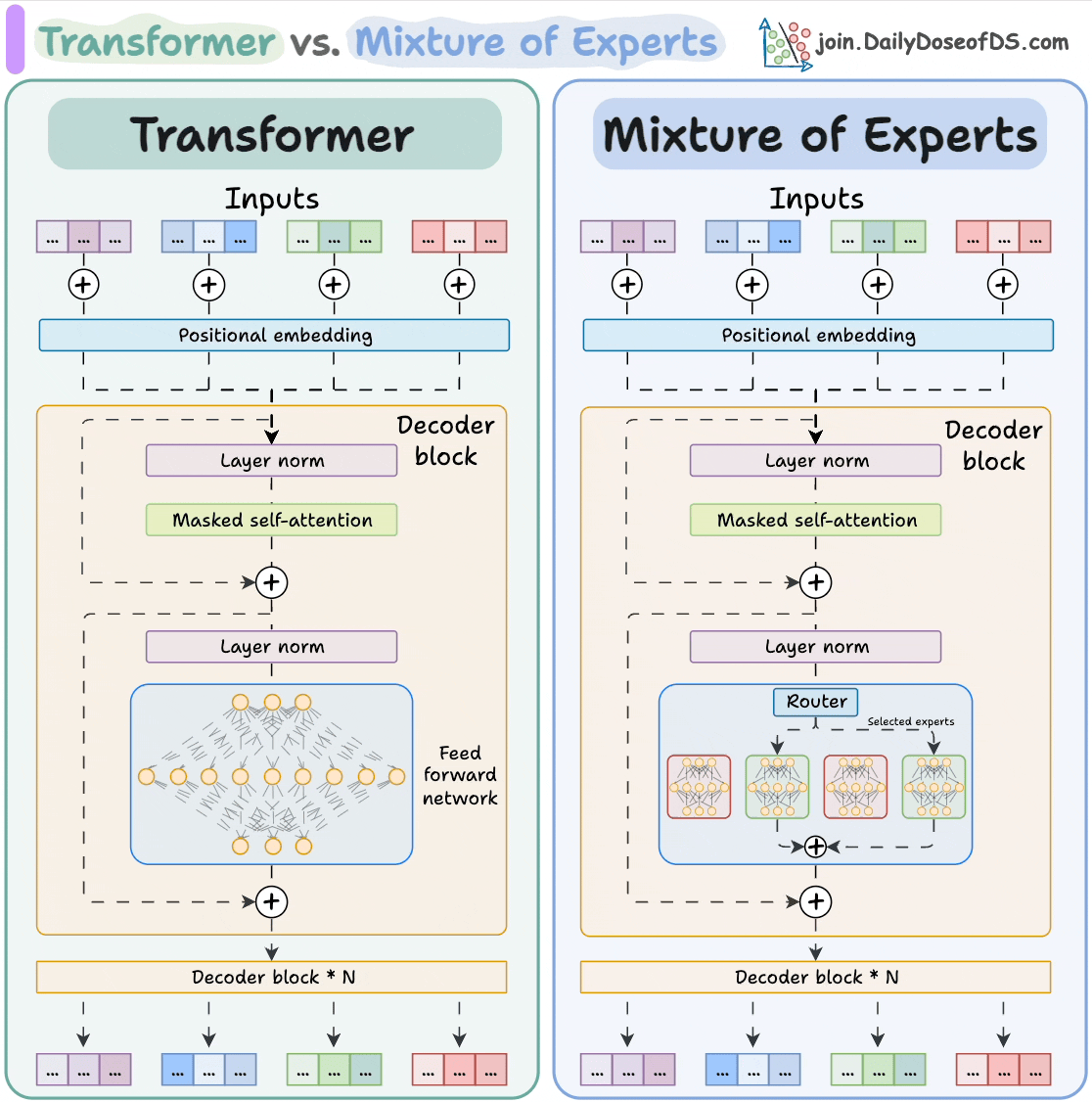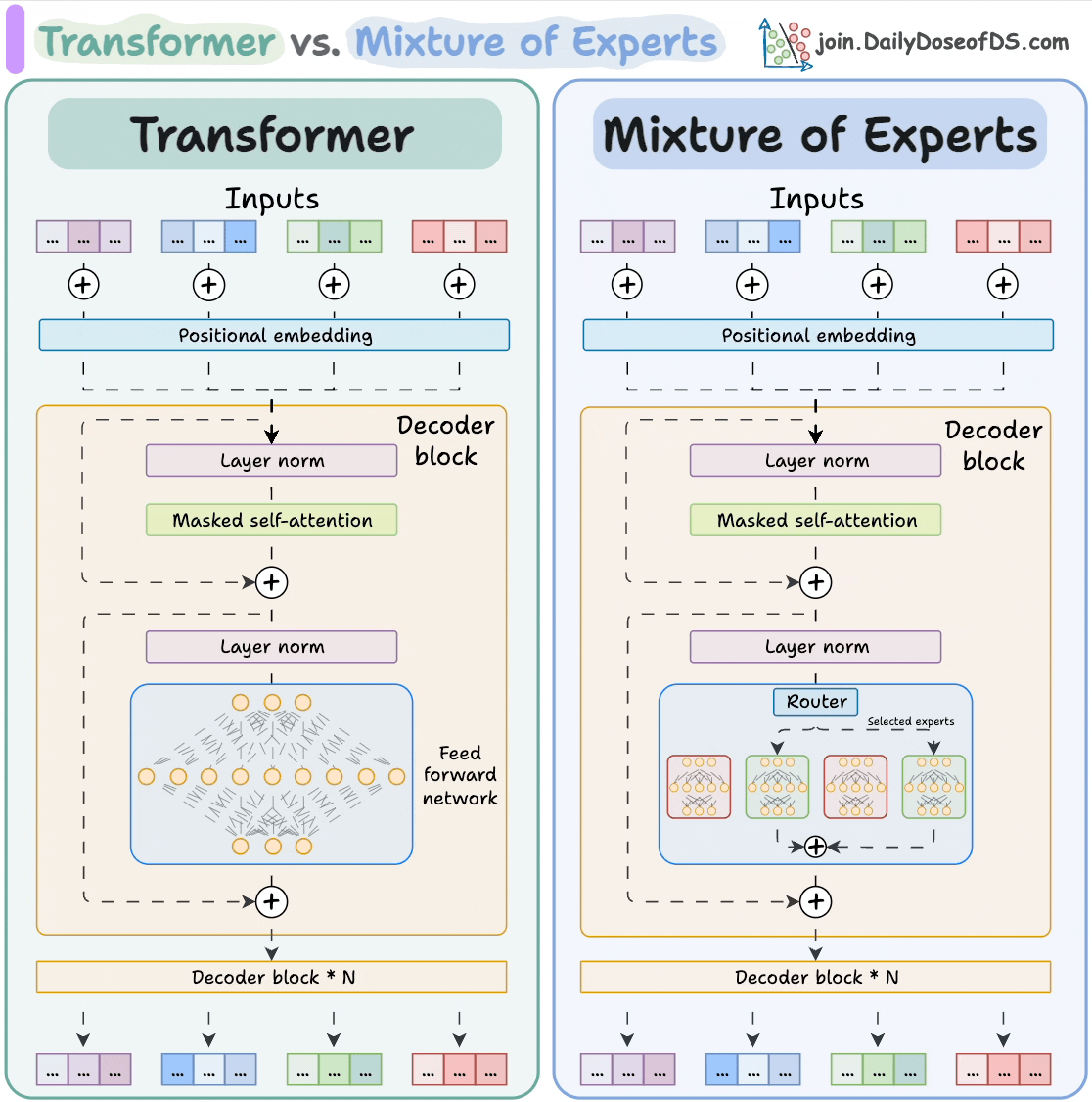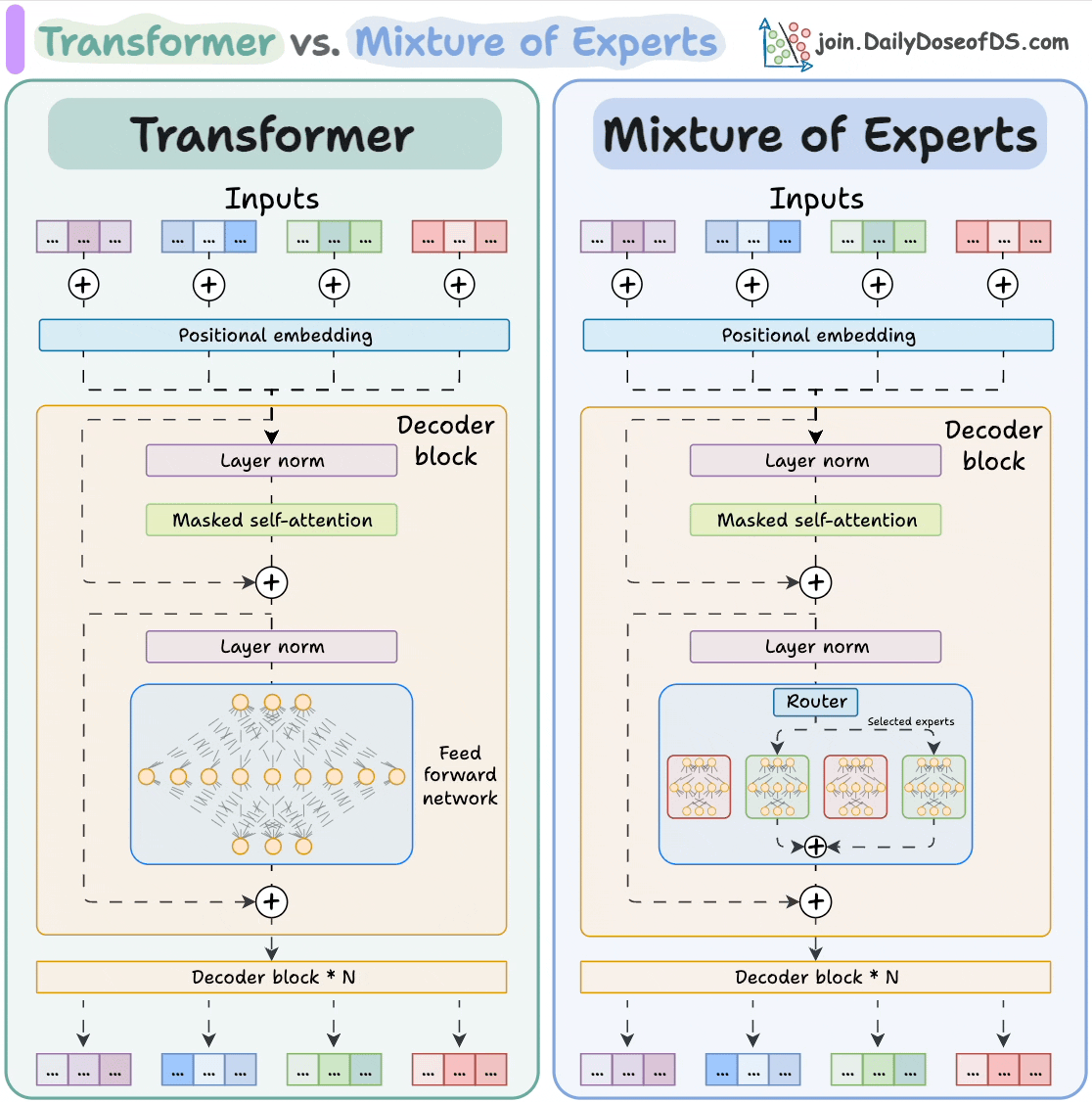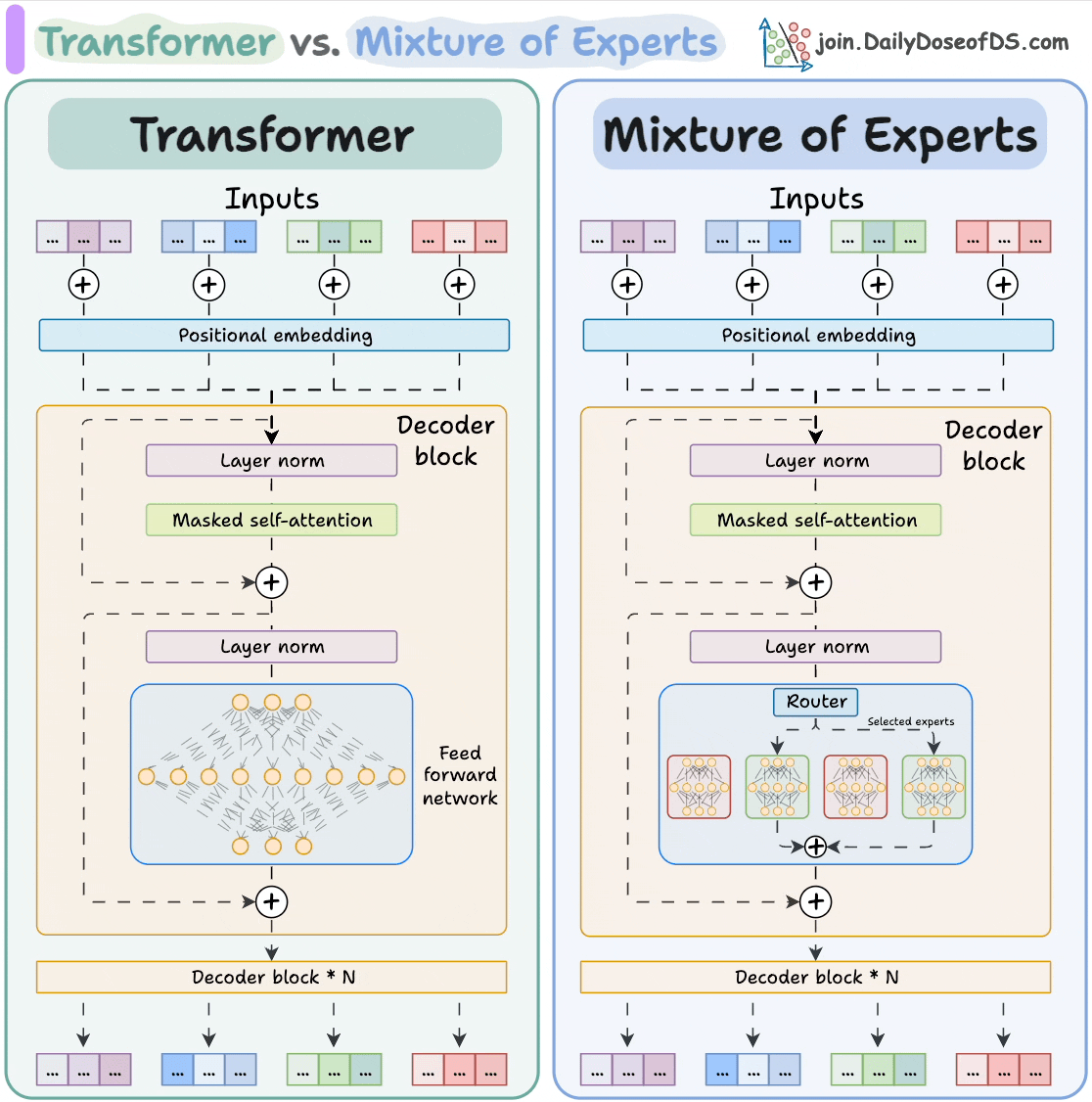
Let's dive in to learn more about MoE!
Transformer and MoE differ in the decoder block:

Transformer uses a feed-forward network.
MoE uses experts, which are feed-forward networks but smaller compared to that in Transformer.
During inference, a subset of experts are selected. This makes inference faster in MoE.
Also, since the network has multiple decoder layers:
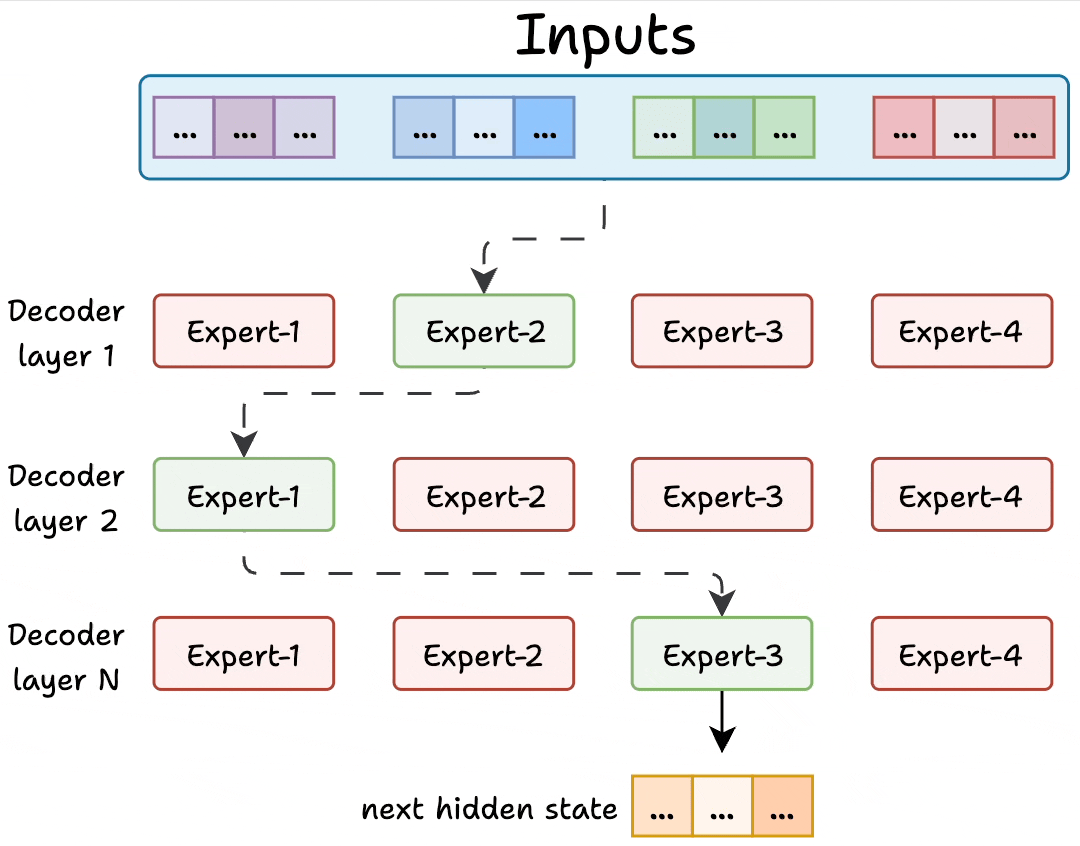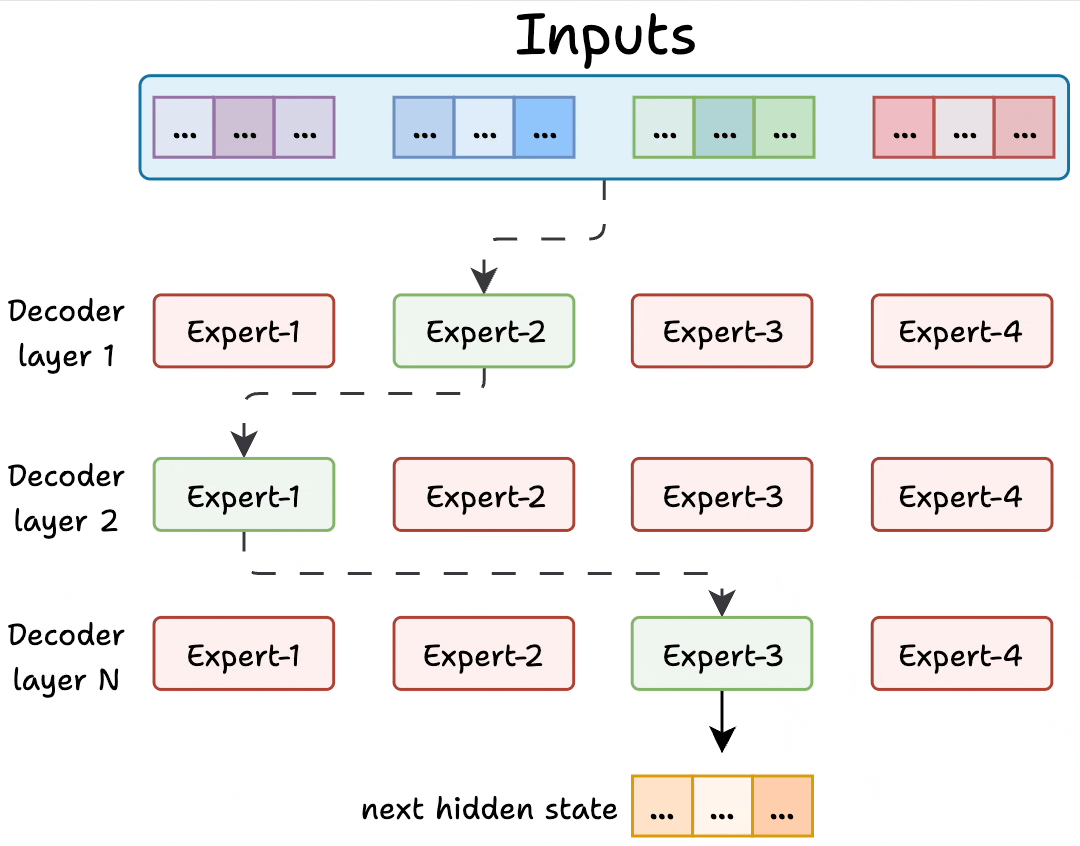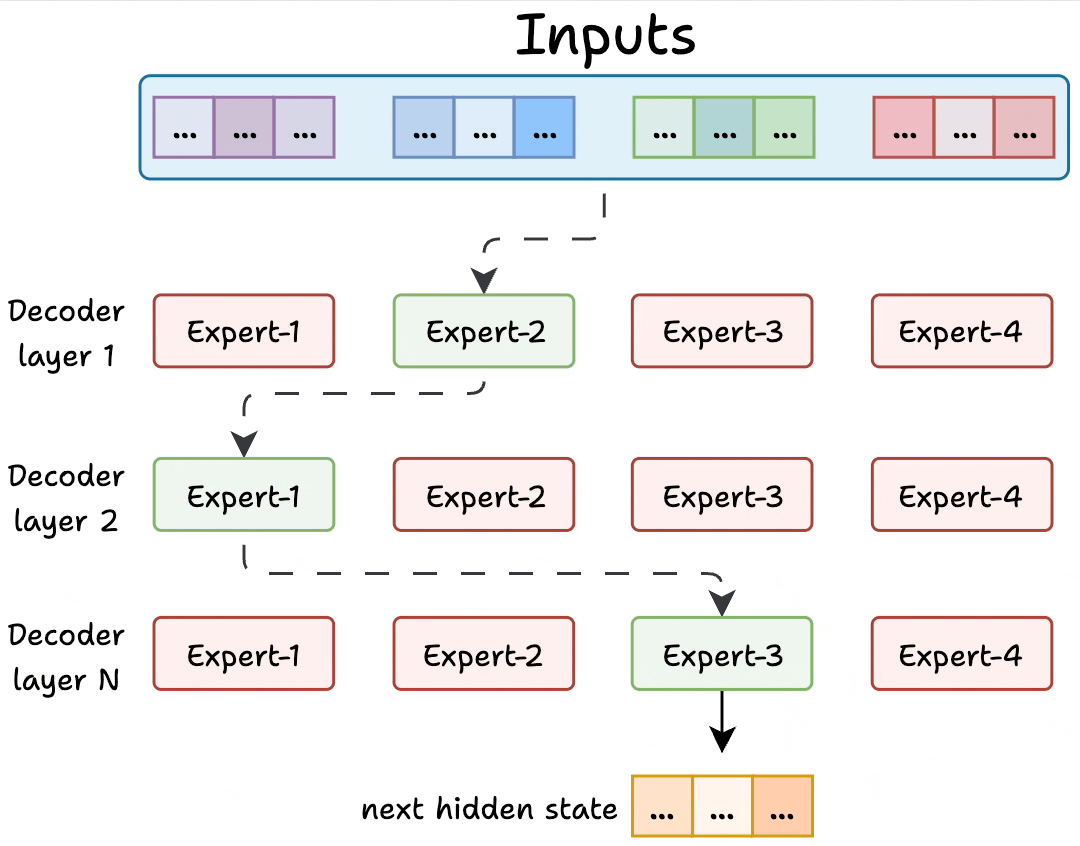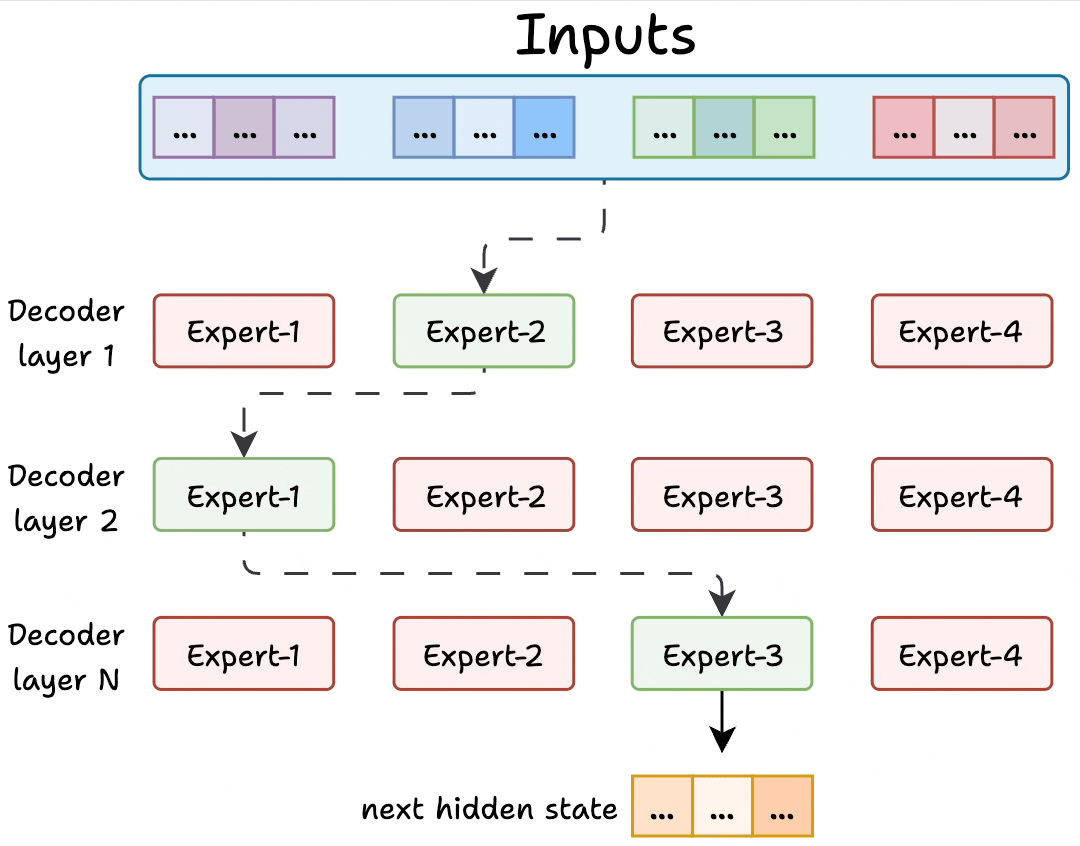
the text passes through different experts across layers.
the chosen experts also differ between tokens.
But how does the model decide which experts should be ideal?
The router does that.
The router is like a multi-class classifier that produces softmax scores over experts. Based on the scores, we select the top K experts.
The router is trained with the network and it learns to select the best experts.
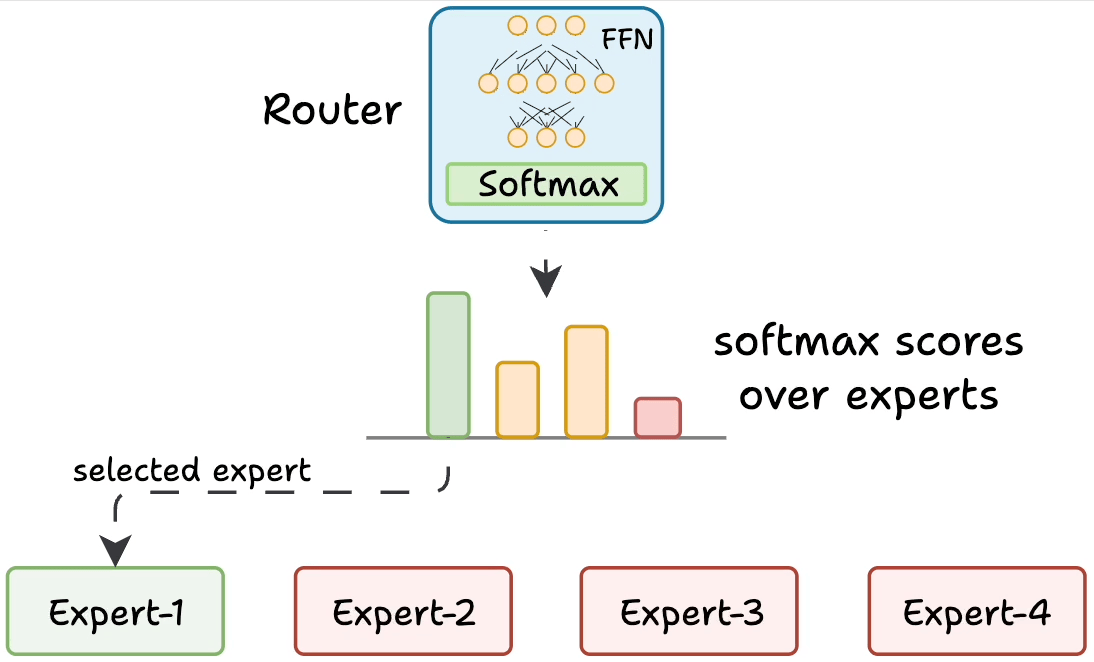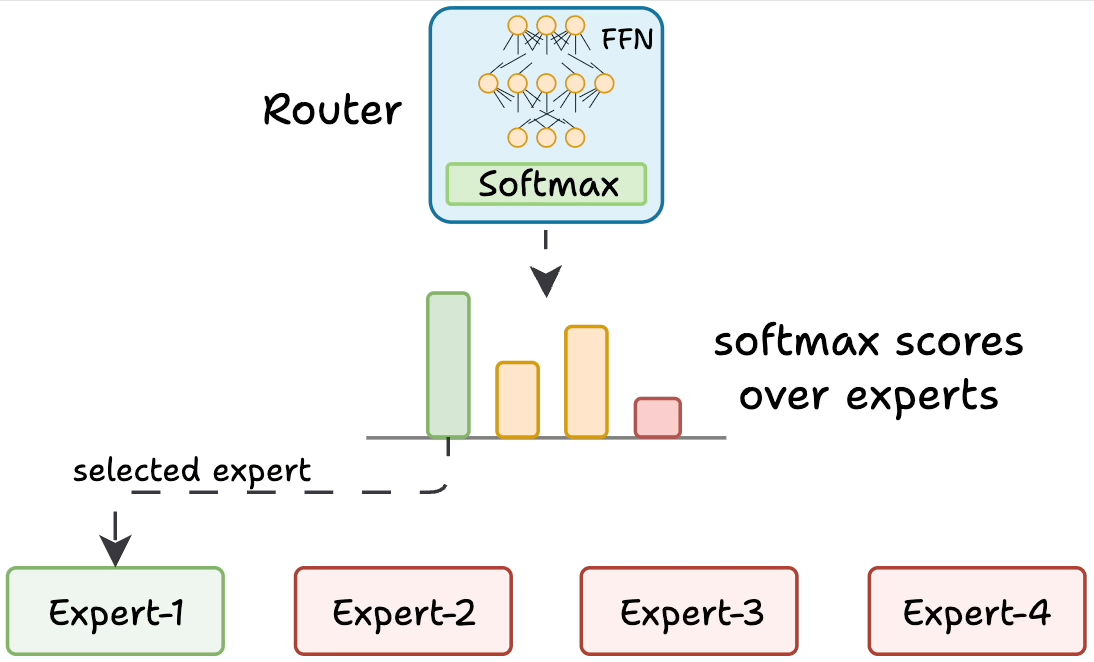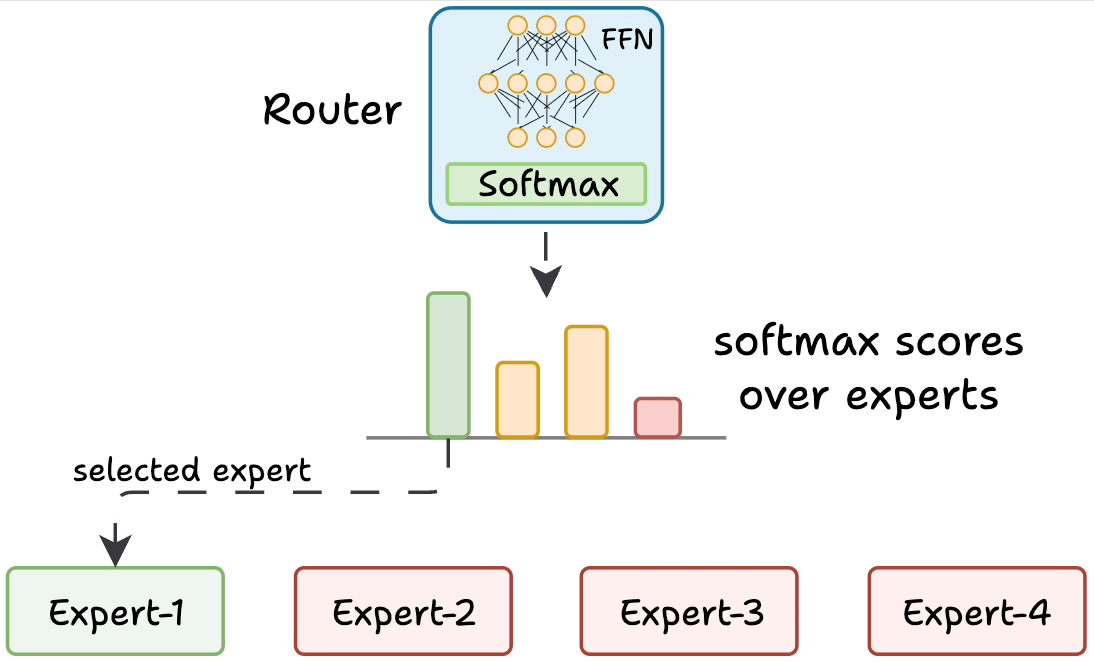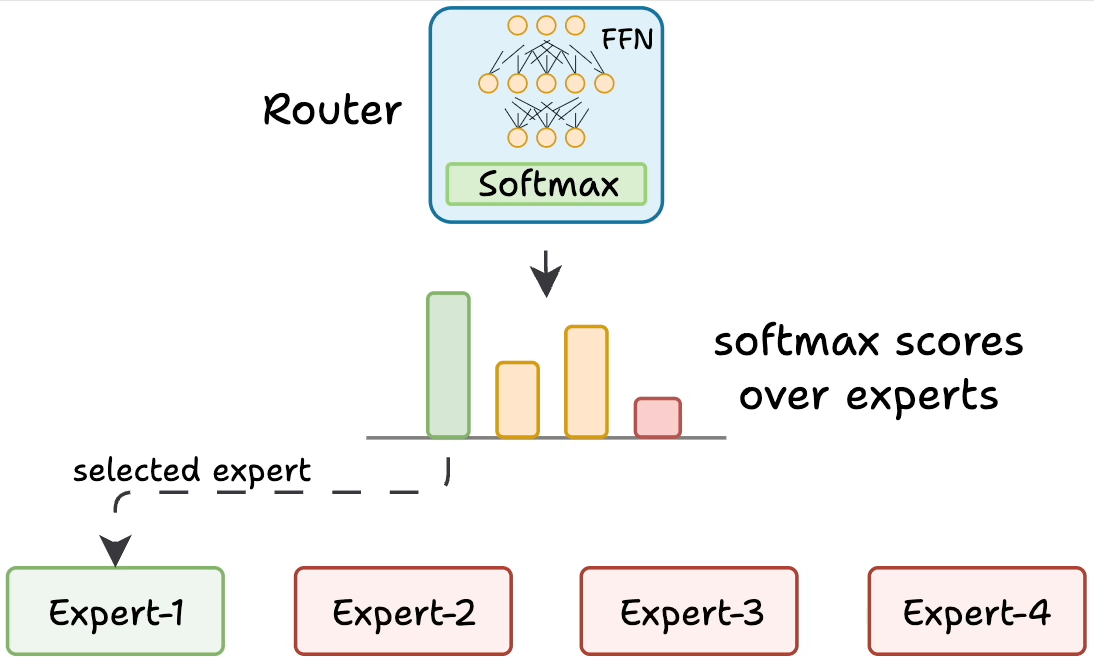
But it isn't straightforward.
There are challenges.
Challenge 1) Notice this pattern at the start of training:
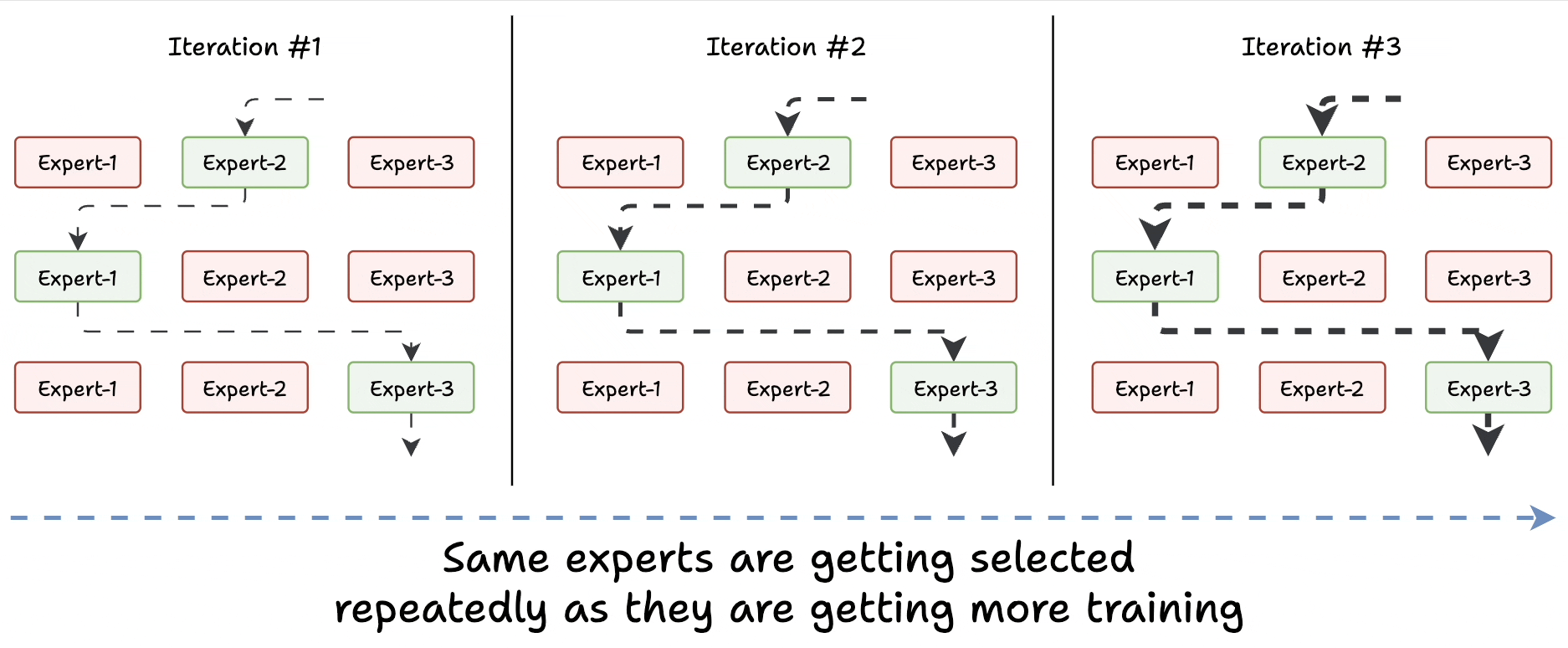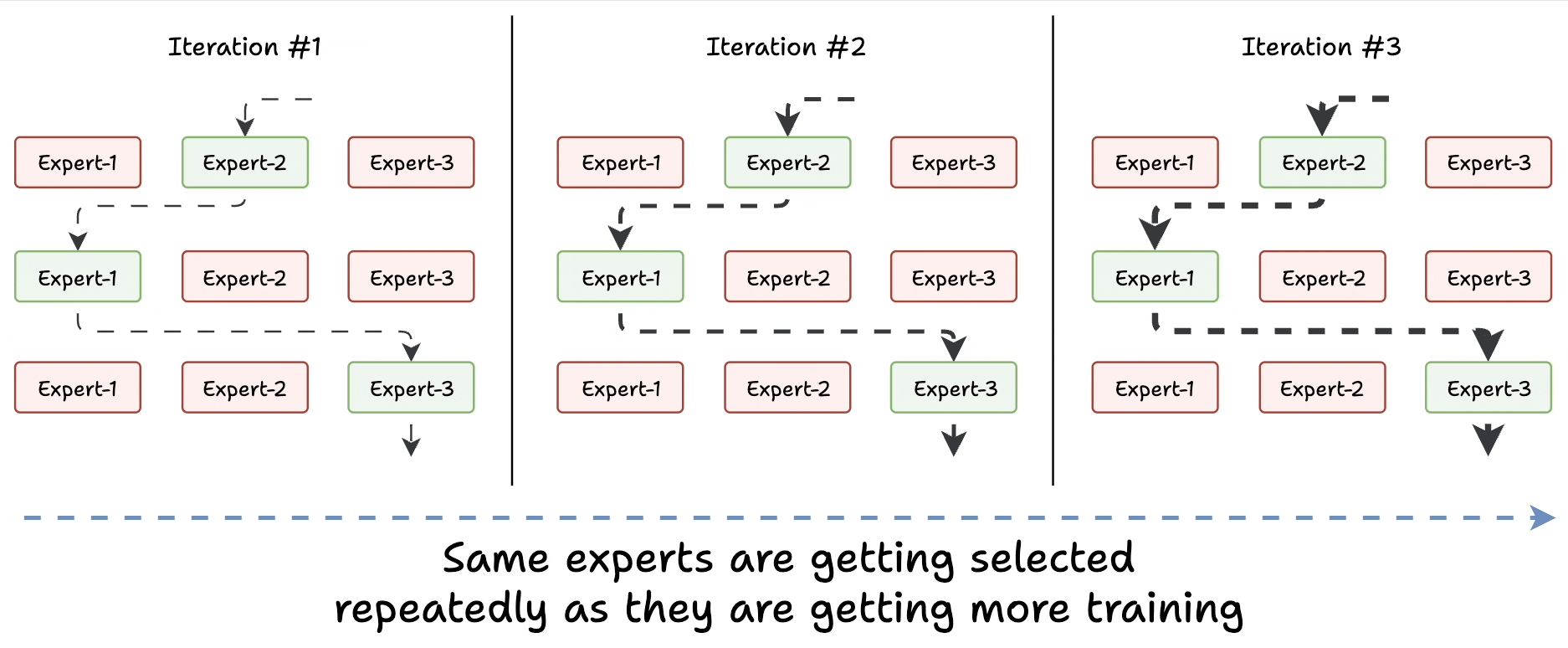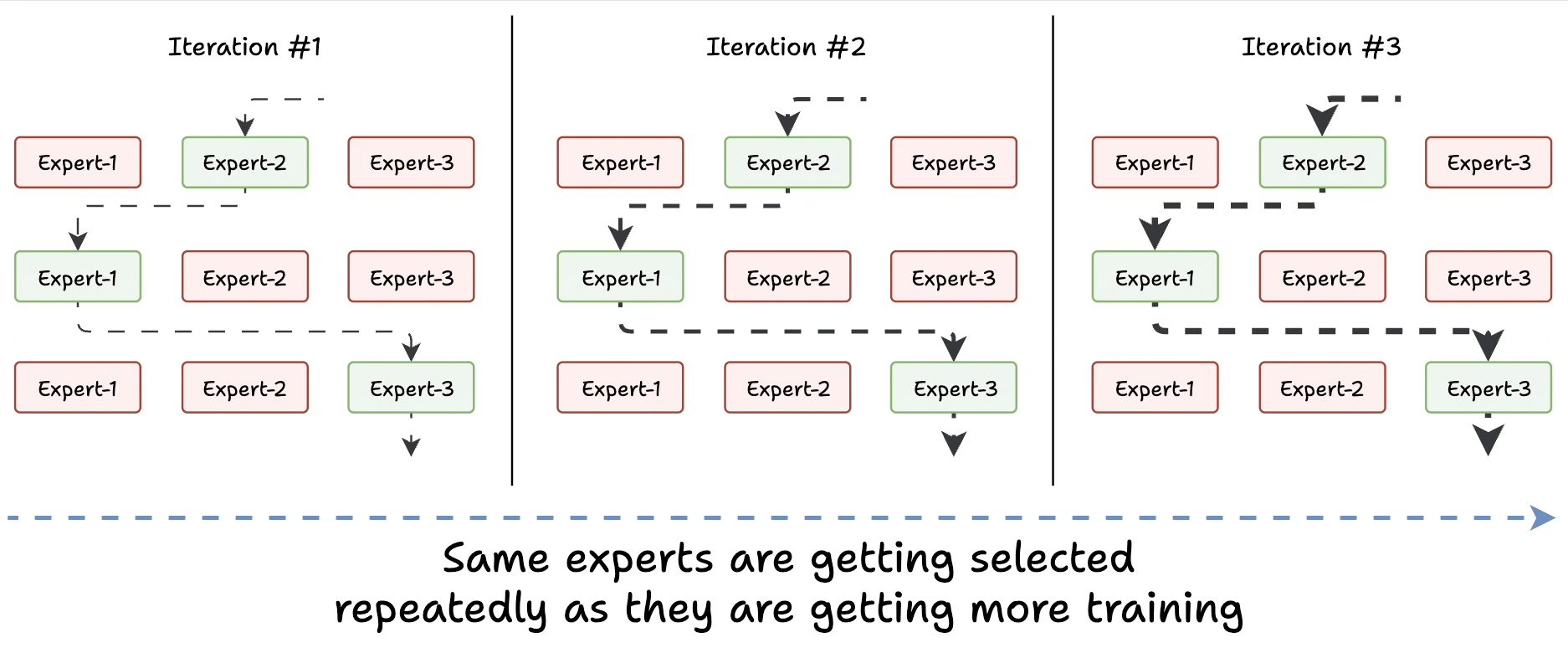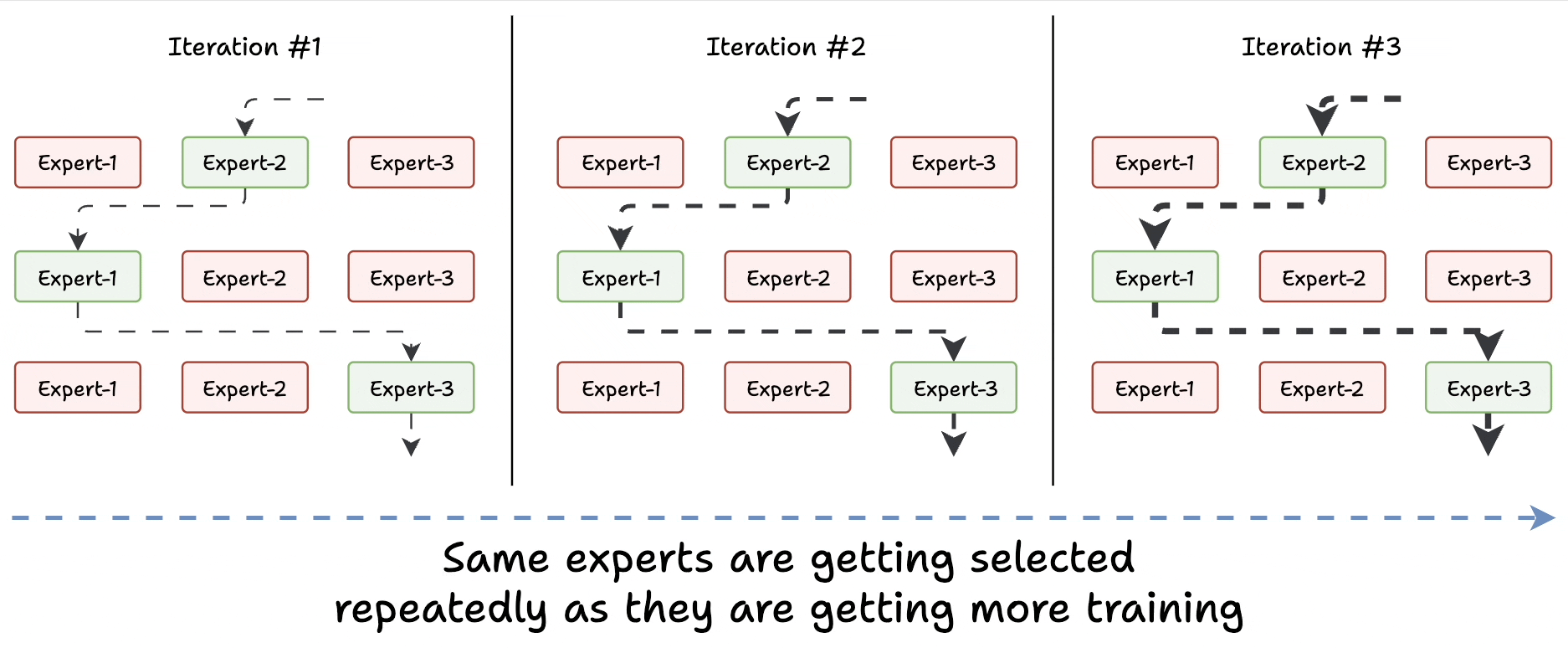
The model selects "Expert 2" (randomly since all experts are similar).
The selected expert gets a bit better.
It may get selected again since it’s the best.
This expert learns more.
The same expert can get selected again since it’s the best.
It learns even more.
And so on!
Essentially, this way, many experts go under-trained!
We solve this in two steps:
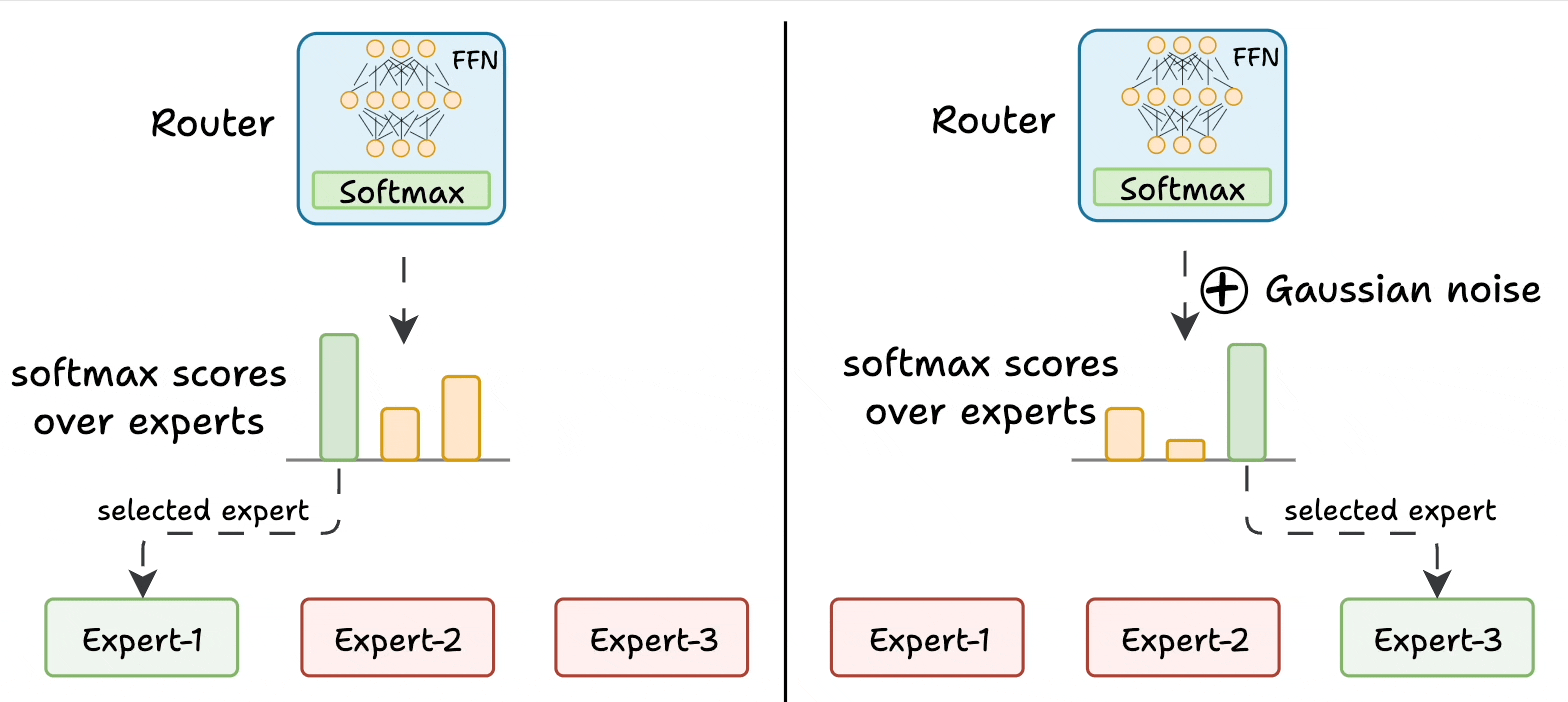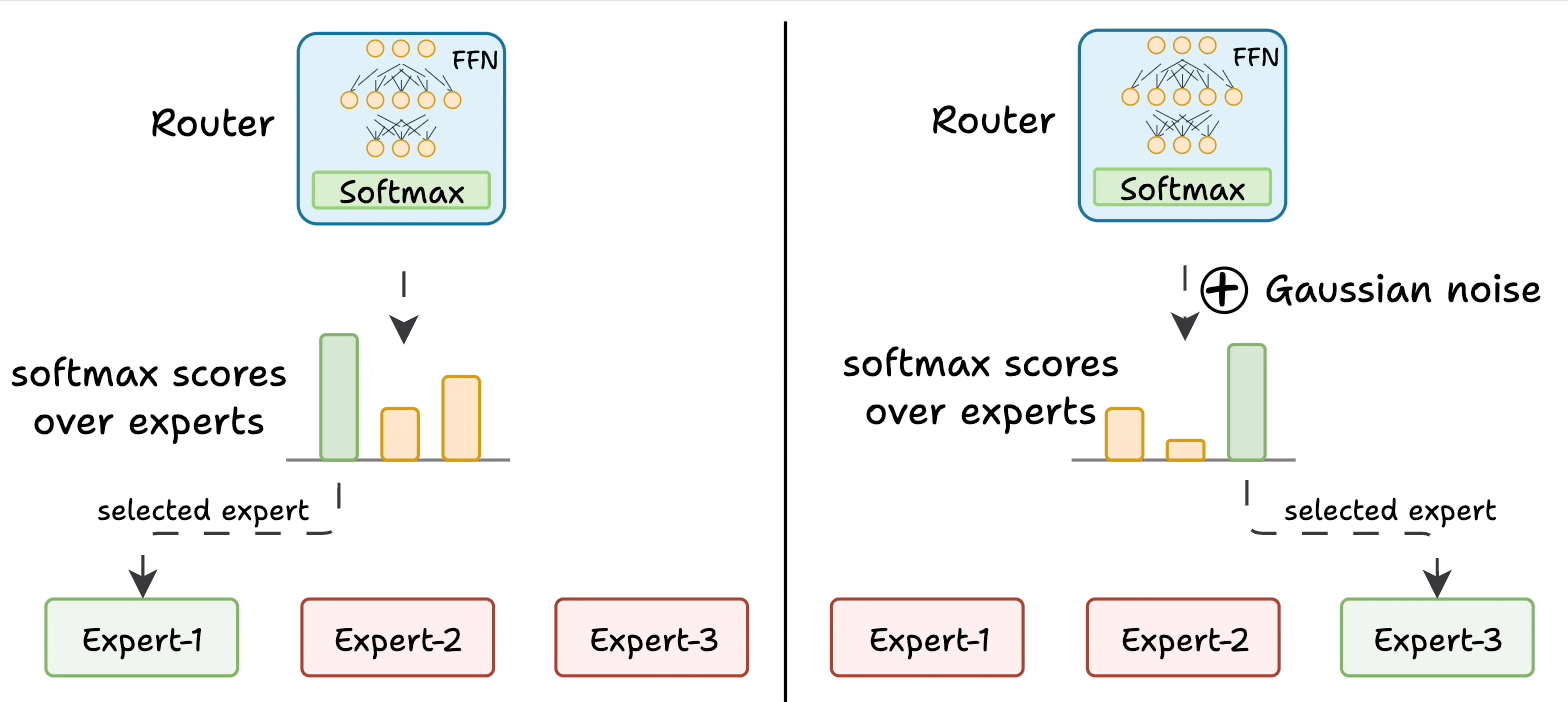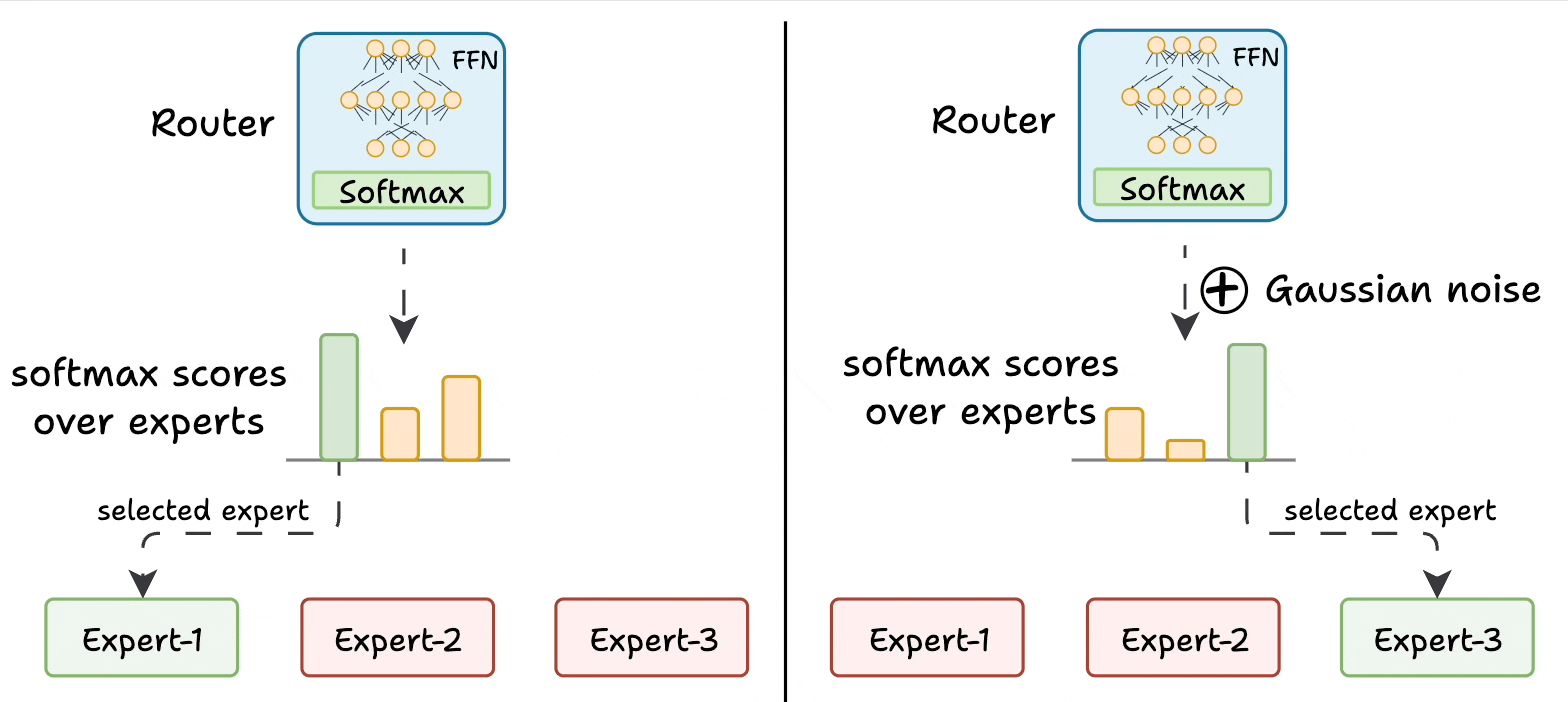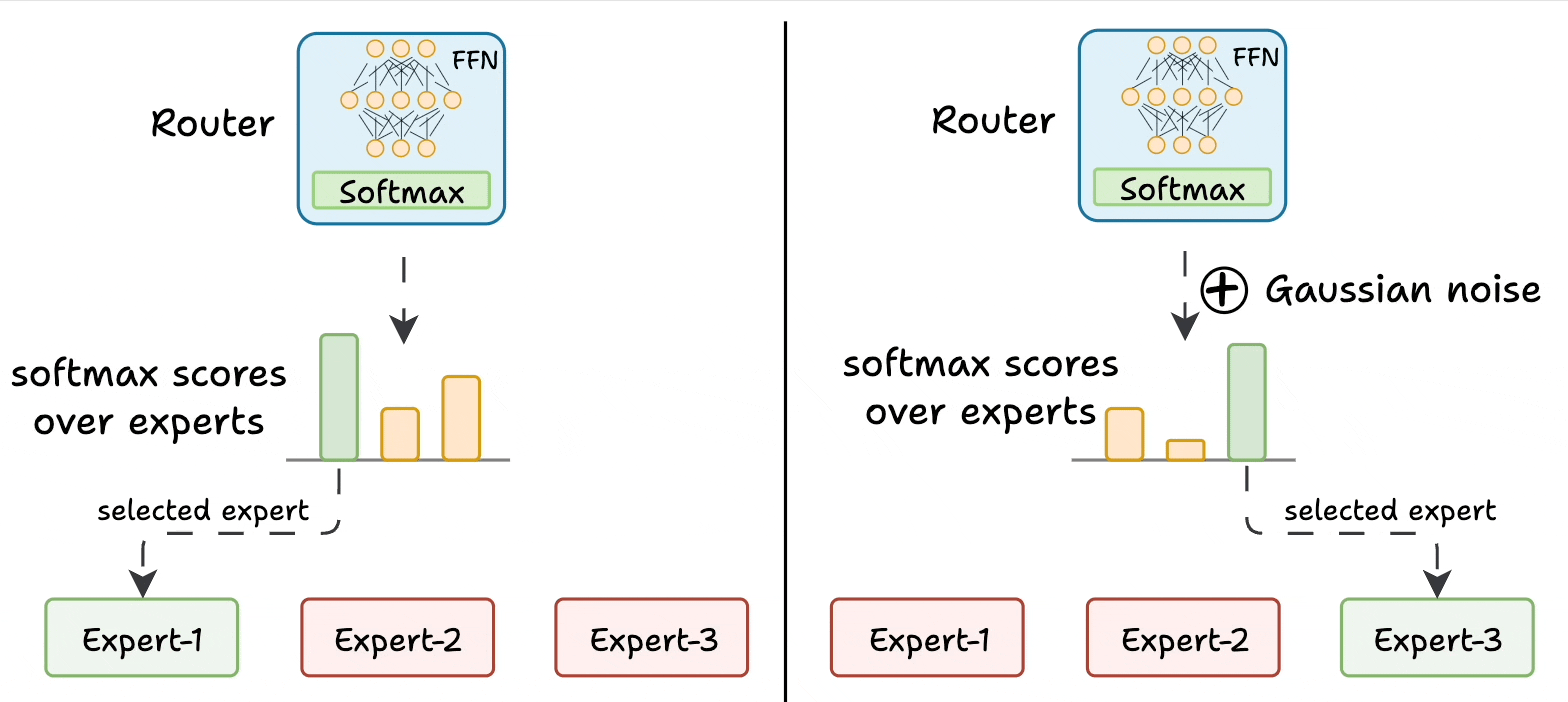
Add noise to the feed-forward output of the router so that other experts can get higher logits.
Set all but top
Klogits to-infinity. After softmax, these scores become zero.
This way, other experts also get the opportunity to train.
Challenge 2) Some experts may get exposed to more tokens than others—leading to under-trained experts.
We prevent this by limiting the number of tokens an expert can process.
If an expert reaches the limit, the input token is passed to the next best expert instead.
MoEs have more parameters to load. However, a fraction of them are activated since we only select some experts.
This leads to faster inference. Mixtral 8x7B by MistralAI is one famous LLM that is based on MoE.
Here's the visual again that compares Transformers and MoE!
If you want to learn how to build with LLMs…
…we have already covered a full crash course on building, optimizing, improving, evaluating, and monitoring RAG apps (with implementation).
Start here → RAG crash course (9 parts + 3 hours of read time).
Over to you: Do you like the strategy of multiple experts instead of a single feed-forward network?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.