
Two Handy Alternatives to Pandas’ Describe
Generate a comprehensive data summary in seconds.

Important announcement (In case you missed it)
Over the coming weeks, we will move to a different newsletter platform.
Switch for free here: https://switch.dailydoseofds.com.
You will receive an email to confirm your account.

Due to deliverability concerns, we can’t move everyone ourselves in one go, so this transition will be slow. But you can join yourself to avoid waiting.
To upgrade your reading experience, please join below:
7500 readers have already joined, and starting next Monday, they will start receiving emails from our new platform.
Let’s get to today’s post now!
Two handy alternatives to Pandas’ describe()
I find the output of df.describe() to be pretty naive and almost of no use. It hardly highlights any key information about the data.
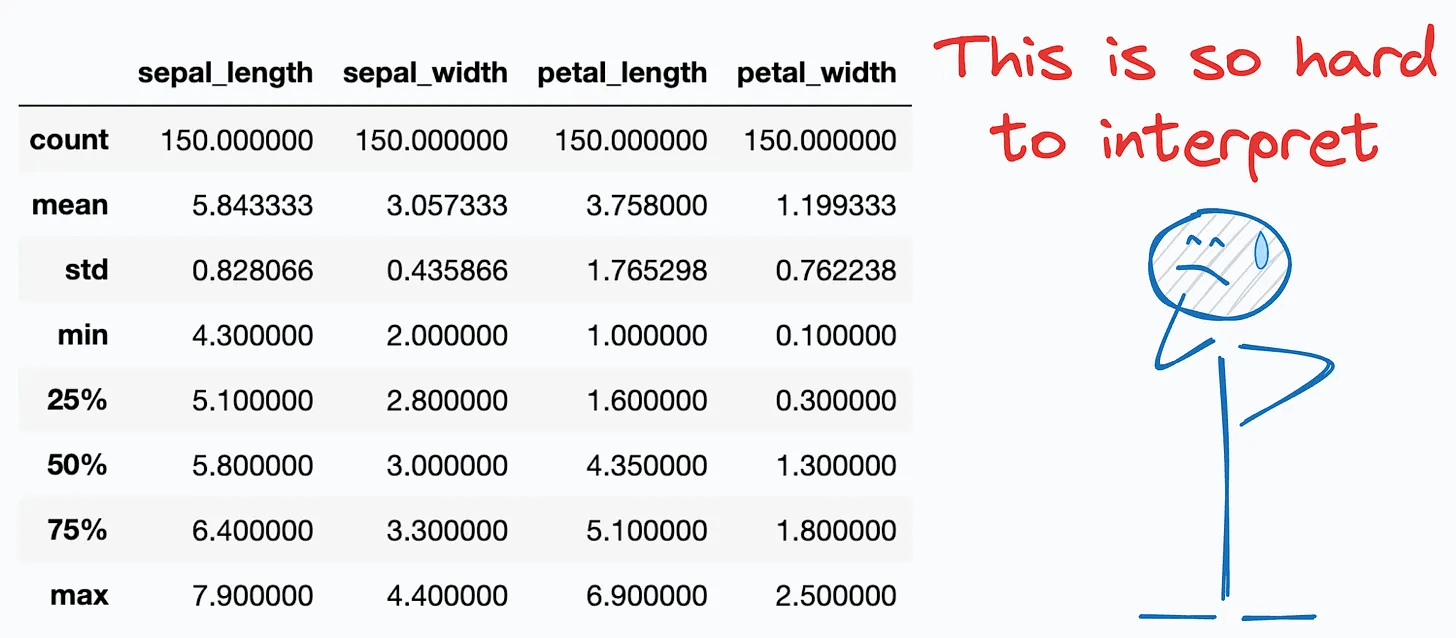
Today, let me share two libraries that supercharge this summary.
The first one is Skimpy.
It is a Jupyter-based tool that provides a standardized and comprehensive data summary.
This includes data shape, column data types, column summary statistics, distribution charts, missing stats, etc., as shown below:

What’s more, the summary is grouped by datatypes for faster analysis.
This is the code to use Skimpy:

One thing I love about Skimpy is that it works seamlessly with Polars, which I also use frequently:

The second library is SummaryTools, which generates a standardized report as well:
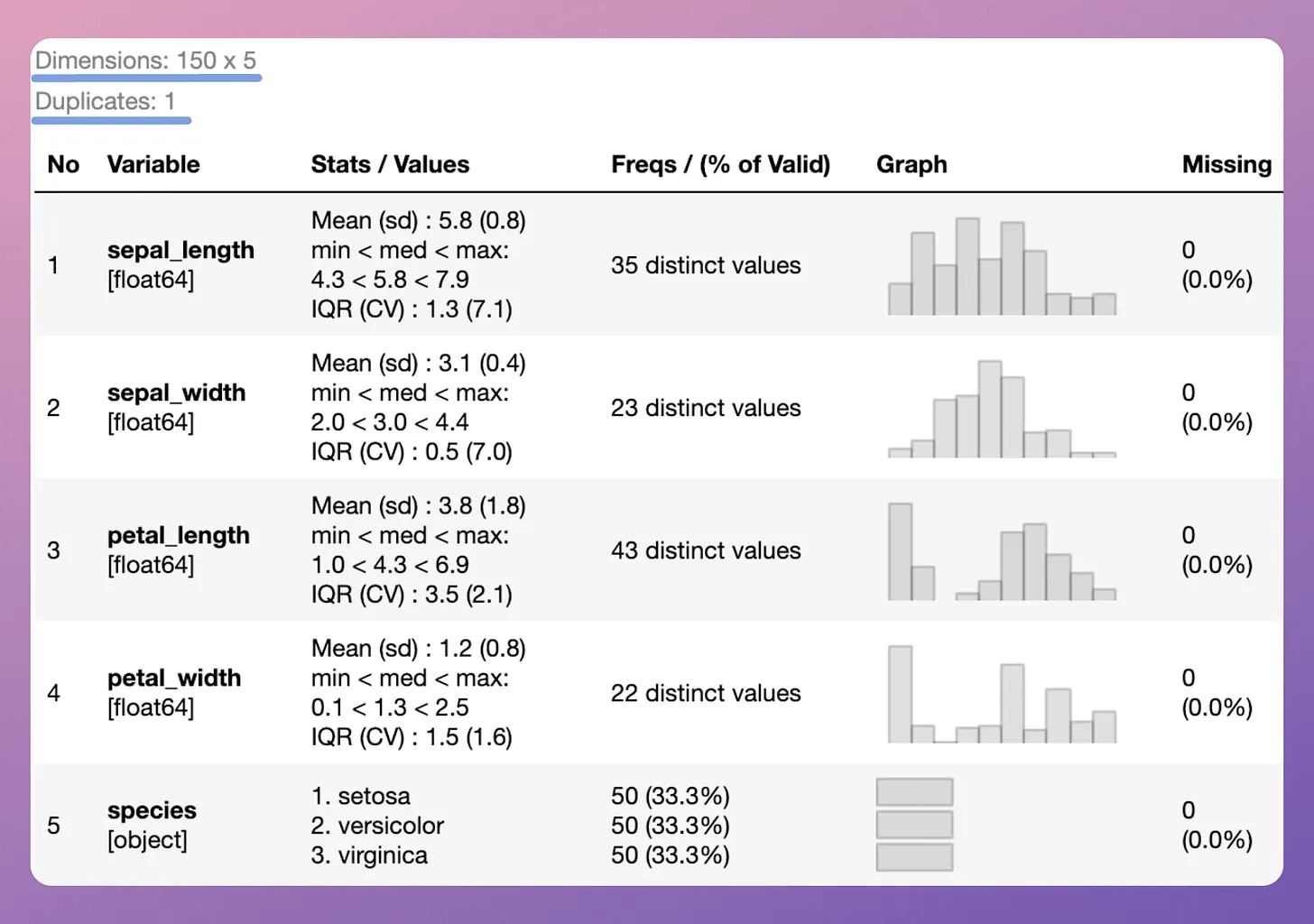
This is the code to use SummaryTools:

Here are two useful things about SummaryTools:
It creates a collapsible summary of the dataset, as illustrated below:

It can create a tabbed summary of the dataset, as shown below:
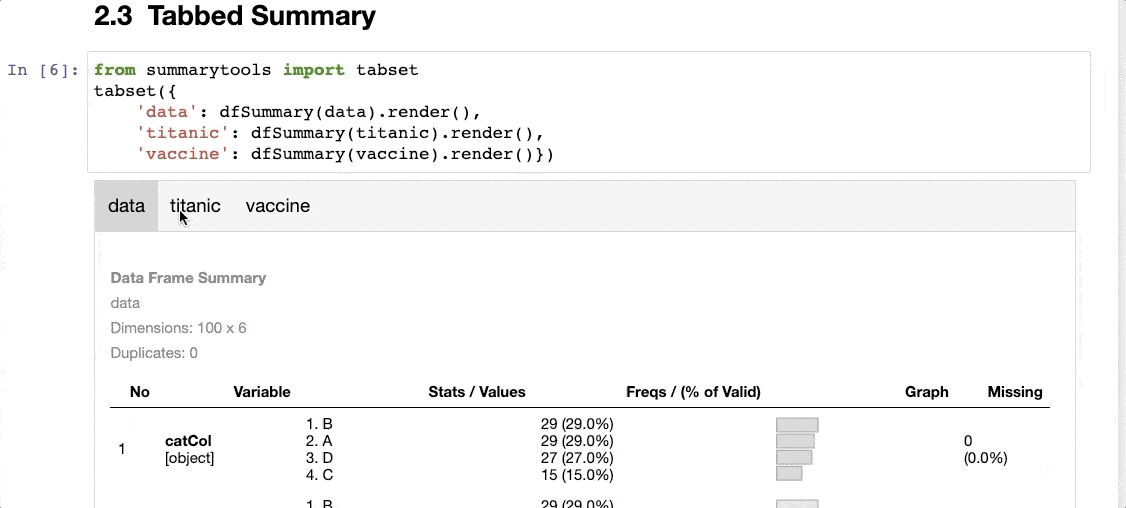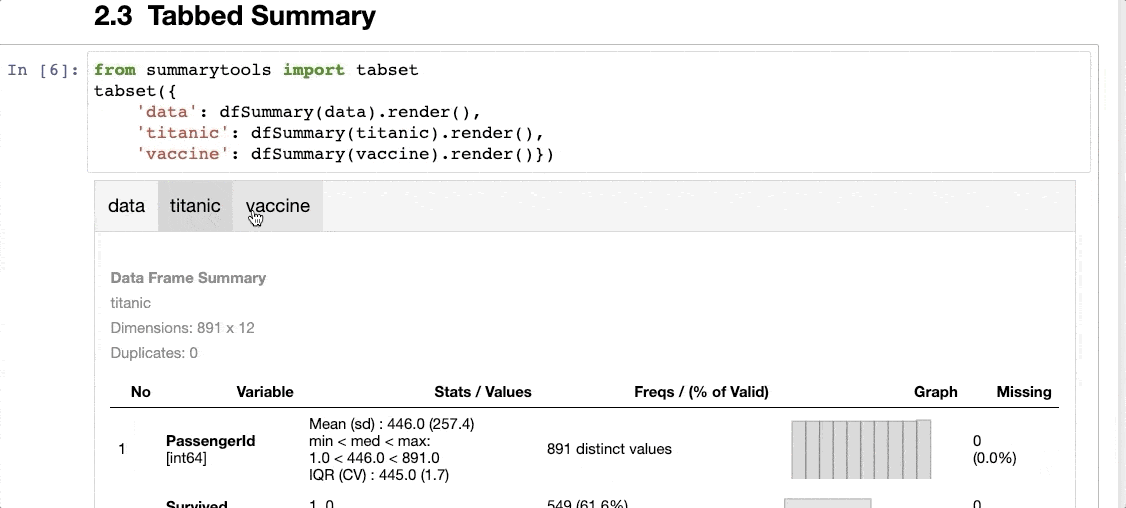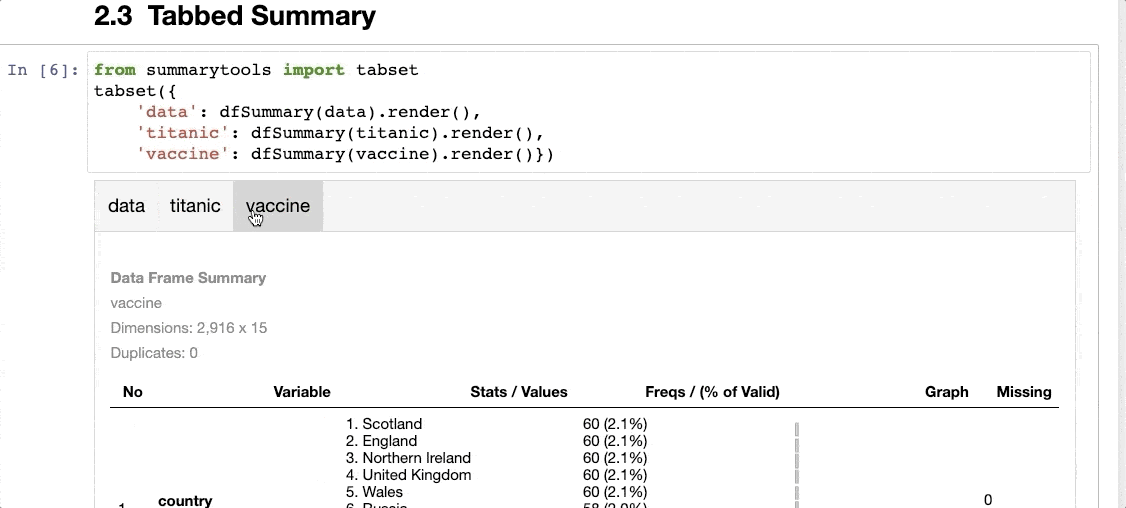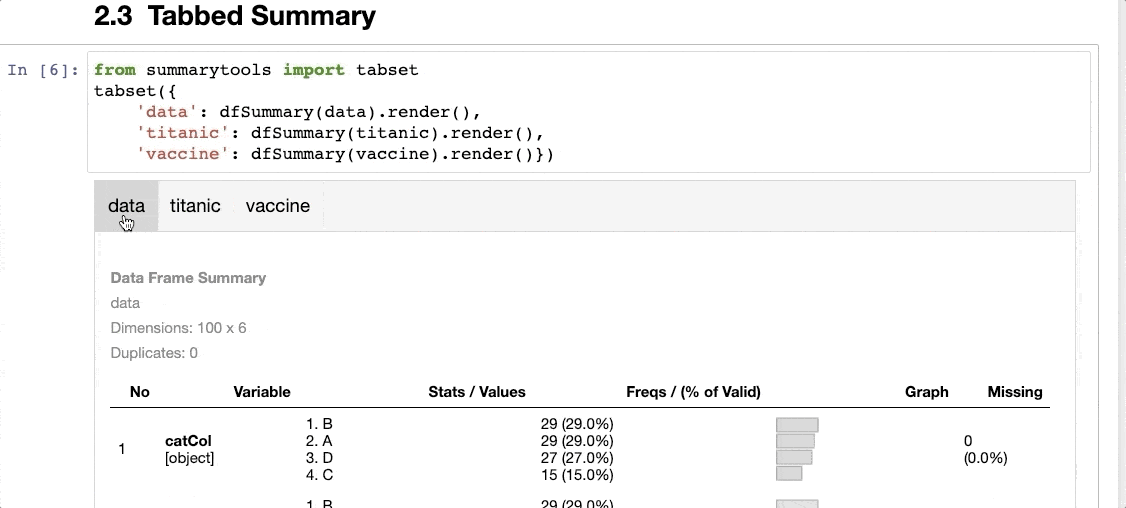
The thing I don’t like about SummaryTools is that it is not compatible with Polars (yet).
Nonetheless, I find both of them extremely promising for understanding my dataset with more granularity than Pandas’ describe() method.
Aren’t they interesting?
👉 Over to you: What other cool Pandas-related tools are you aware of?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 105,000+ data scientists and machine learning professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
I am getting below runtime error when using `skim` function.
TypeError: to_dict() takes from 1 to 2 positional arguments but 4 were given
Can someone help to resolve this? Tried stackoverflow, google but no use.