
Two Simple Yet Immensely Powerful Techniques to Supercharge kNN Models
Addressing some common limitations of traditional kNNs.

One of the things that always makes me a bit cautious and skeptical when using kNN is its HIGH sensitivity to the parameter k.
To understand better, consider this dummy 2D dataset below. The red data point is a test instance we intend to generate a prediction for using kNN.

Say we set the value of k=7.
The prediction for the red instance is generated in two steps:
First, we count the
7nearest neighbors of the red data point.Next, we assign it to the class with the highest count among those 7 nearest neighbors.
This is depicted below:

The problem is that step 2 is entirely based on the notion of class contribution — the class that maximally contributes to the k nearest neighbors is assigned to the data point.
But this can miserably fail at times, especially when we have a class with few samples.
For instance, as shown below, with k=7, the red data point can NEVER be assigned to the yellow class, no matter how close it is to that cluster:

While it is easy to tweak the hyperparameter k visually in the above demo, this approach is infeasible in high-dimensional datasets.
There are two ways to address this.
Solution #1: Used distance-weighed kNN
Distance-weighted kNNs are a much more robust alternative to traditional kNNs.
As the name suggests, in step 2, they consider the distance to the nearest neighbor.
As a result, the closer a specific neighbor is, the more impact it will have on the final prediction.
Its effectiveness is evident from the image below.
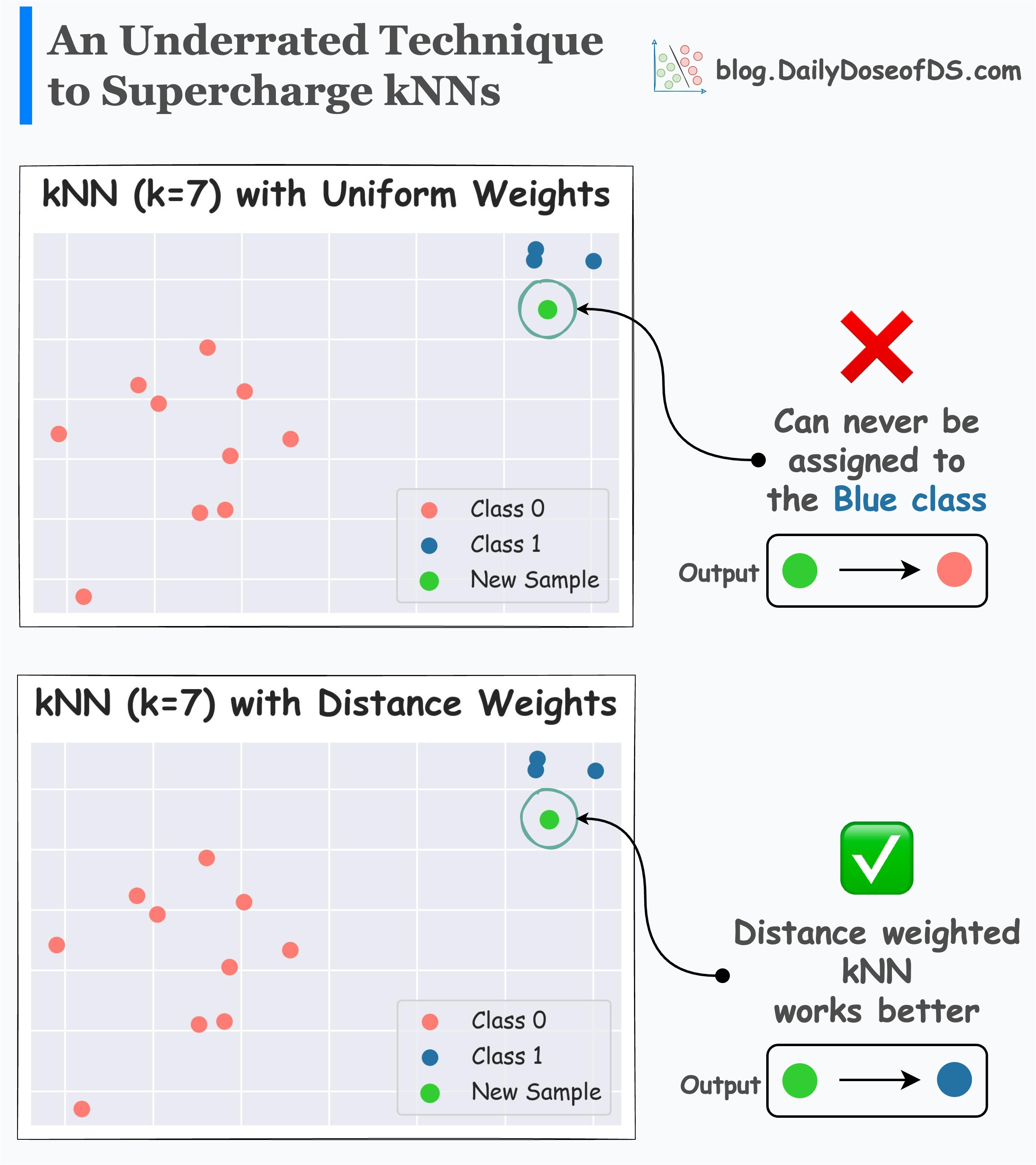
In the first plot, traditional kNN (with k=7) can never predict the blue class.
In the second plot, distance-weighted kNN is found to be more robust in its prediction.
As per my observation, a distance-weighted kNN typically works much better than a traditional kNN. And this makes intuitive sense as well.
Yet, this may go unnoticed because, by default, the kNN implementation of sklearn considers “uniform” weighting.

Solution #2: Dynamically update the hyperparameter k
Recall the above demo again:

Here, one may argue that we must refrain from setting the hyperparameter k to any value greater than the minimum number of samples that belong to a class in the dataset.
Of course, I agree with this to an extent.
But let me tell you the downside of doing that.
Setting a very low value of k can be highly problematic in the case of extremely imbalanced datasets.

To give you more perspective, I have personally used kNN on datasets that had merely one or two instances for a particular class in the training set.
And I discovered that setting a low of k (say, 1 or 2) led to suboptimal performance because the model was not as holistically evaluating the nearest neighbor patterns as it was when a large value of k was used.
In other words, setting a relatively larger value of k typically gives more informed predictions than using lower values.
But we just discussed above that if we set a large value of k, the majority class can dominate the classification result:

To address this, I found dynamically updating the hyperparameter k to be much more effective.
More specifically, there are three steps in this approach.
For every test instance:
Begin with a standard value of
kas we usually would and find theknearest neighbors.Next, update the value of the
kas follows:For all unique classes that appear in the
knearest neighbor, find the total number of training instances they have.
Update the value of k to:

Now perform majority voting only on the first
k'neighbors only.

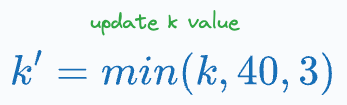
This makes an intuitive sense as well:
If a minority class appears in the top
knearest neighbor, we must reduce the value ofkso that the majority class does not dominate.If a minority class DOES NOT appears in the top
knearest neighbor, we will likely not update the value ofkand proceed with a holistic classification.
I used this approach in a couple of my research projects. If you want to learn more, here’s my research paper: Interpretable Word Sense Disambiguation with Contextualized Embeddings.
The only shortcoming is that you wouldn’t find this approach in any open-source implementations. In fact, in my projects as well, I had to write a custom implementation, so take that into account.
👉 Over to you: What are some other ways to make kNNs more robust when a class has few samples?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Could you theoretically combine the two approaches where the second method would be a precursor to the first method?