
Two Skills to Fix the Context Gap in Claude Code
They cover what CLAUDE.md never will.

Two skills to fix the context gap in Claude Code
Claude Code has two context gaps that no amount of CLAUDE.md optimization will fix.
The first is web scraping.
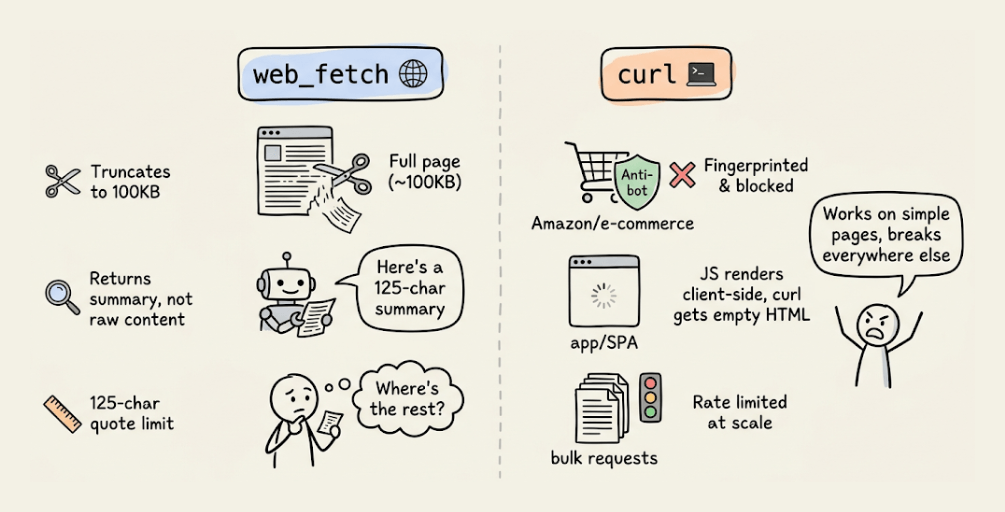
web_fetchdoesn’t return raw page content. It runs the page through a smaller model and returns a summary with a 125-character quote limit, so you can’t use it to extract full tutorials, product specs, or thread content.curlreturns raw HTML but gets blocked by sites with anti-bot protection (Amazon, LinkedIn, most e-commerce), can’t render JavaScript SPAs, and fails at scale due to rate limiting. Both truncate at around 100KB.
The second is backend integration.
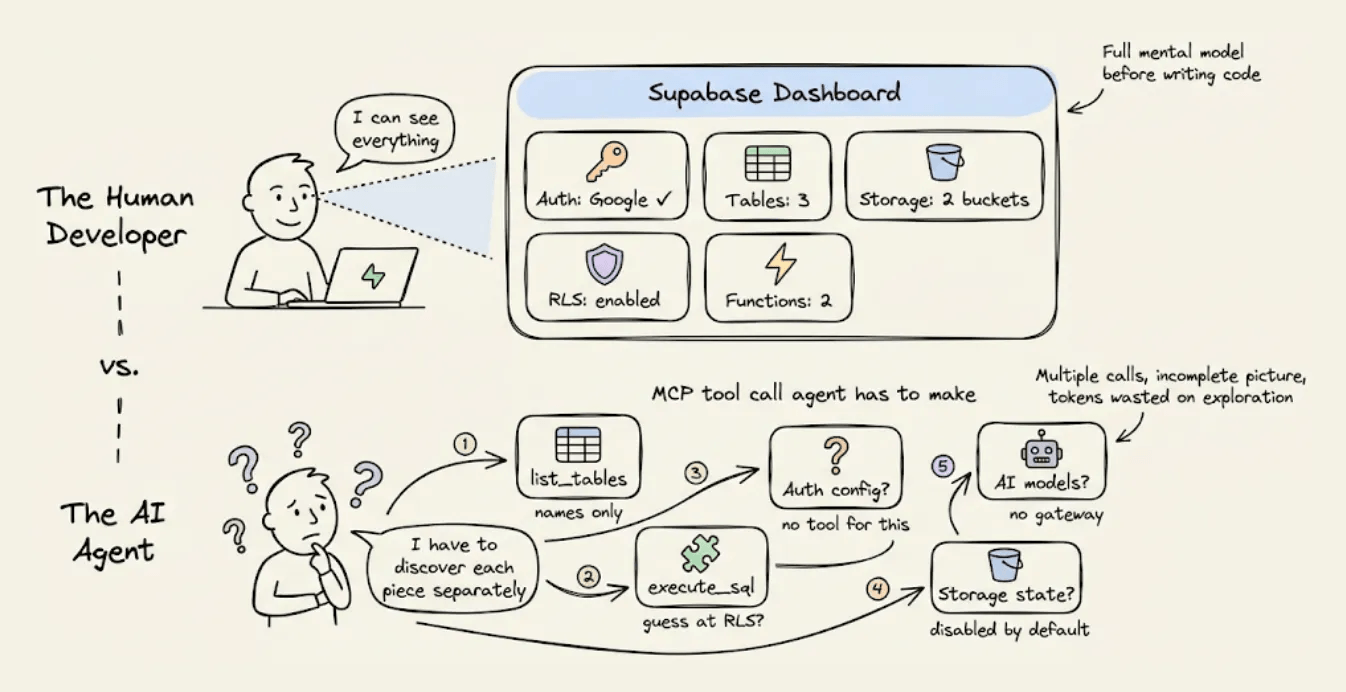
When Claude Code talks to a backend like Supabase through MCP, it discovers state through multiple separate calls (
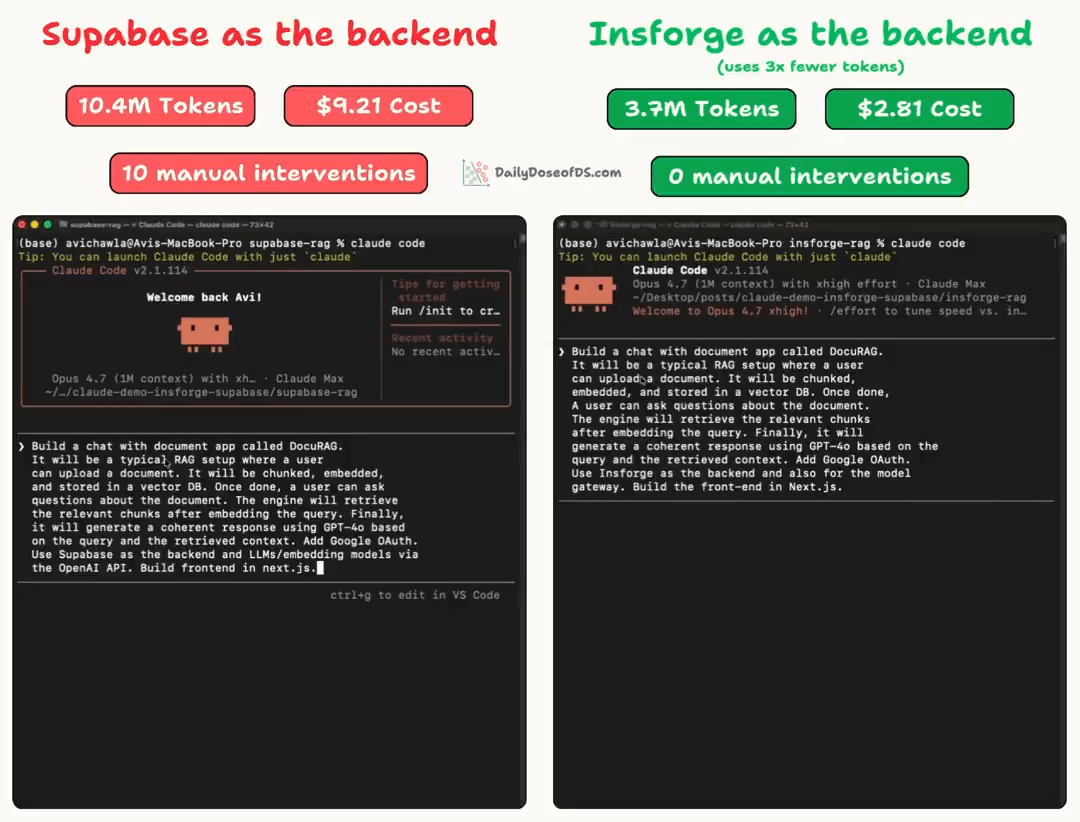
list_tables,execute_sql,list_extensions), each returning a partial view.Auth provider config isn’t queryable at all. And when something fails, error messages don’t distinguish between platform-level and code-level rejections, so the agent enters retry loops that burn tokens with every attempt. In our recent test, a single RAG app built on Supabase consumed 10.4M tokens and needed 10 manual fixes.
Bright Data solves the first problem. InsForge solves the second.
Today, let’s look at how to set up both as skills in Claude Code, with an interesting way we tend to use them.
Bright Data setup
Bright Data skill (open-source) adds scraping infrastructure that handles everything web_fetch and curl can’t.
The agent gets a four-tier fallback that escalates based on what the target site requires, like native fetch, curl, browser automation, and a proxy network with residential IPs and automatic CAPTCHA solving.
For agent workflows, the more useful capability is structured data extraction.
Instead of raw HTML that the agent has to parse, Bright Data provides pre-built extractors for 40+ platforms (Amazon, LinkedIn, Instagram, TikTok, YouTube, Reddit) that return clean JSON with specific fields like product prices, review scores, profile data, and post content.
npx skills add brightdata/skills
This installs several skills covering scraping, search, structured data feeds, MCP orchestration, SDK best practices, and the bdata CLI.
InsForge setup
We covered the backend problem in depth in a recent issue. The same RAG app that consumed 10.4M tokens on Supabase consumed 3.7M on InsForge with zero errors.
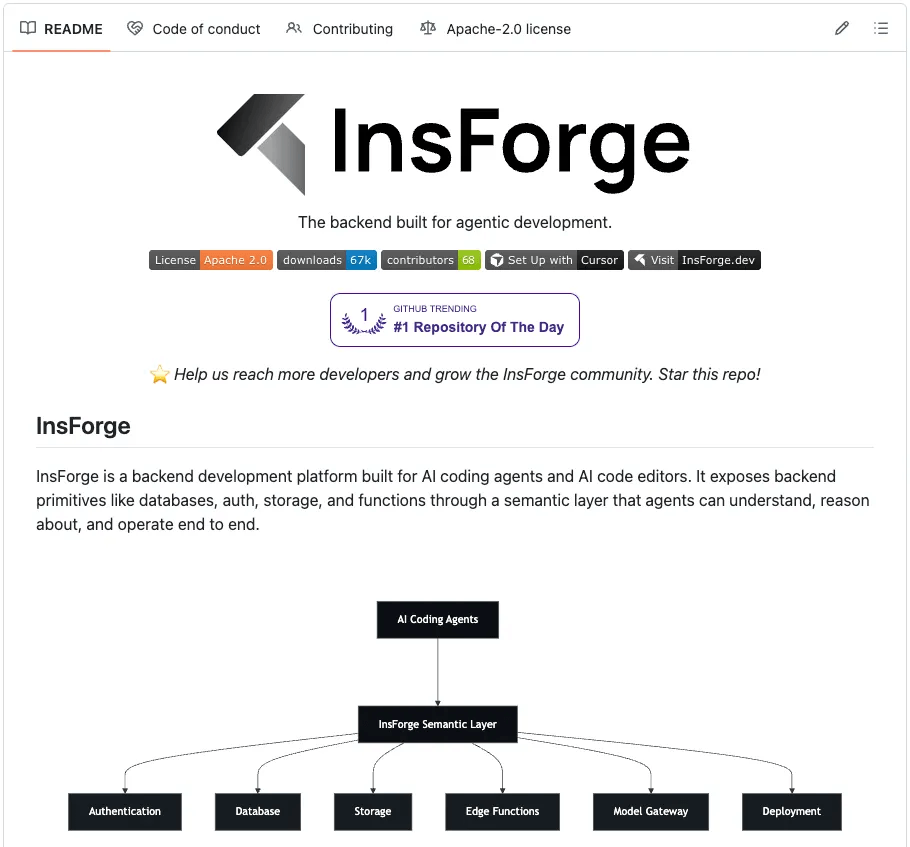
InsForge (open-source, Apache 2.0) acts as the backend context engineering layer for agents using Skills and CLI.
Install all four Skills (primary documentation and diagnostic layer):
npx skills add insforge/insforge-skills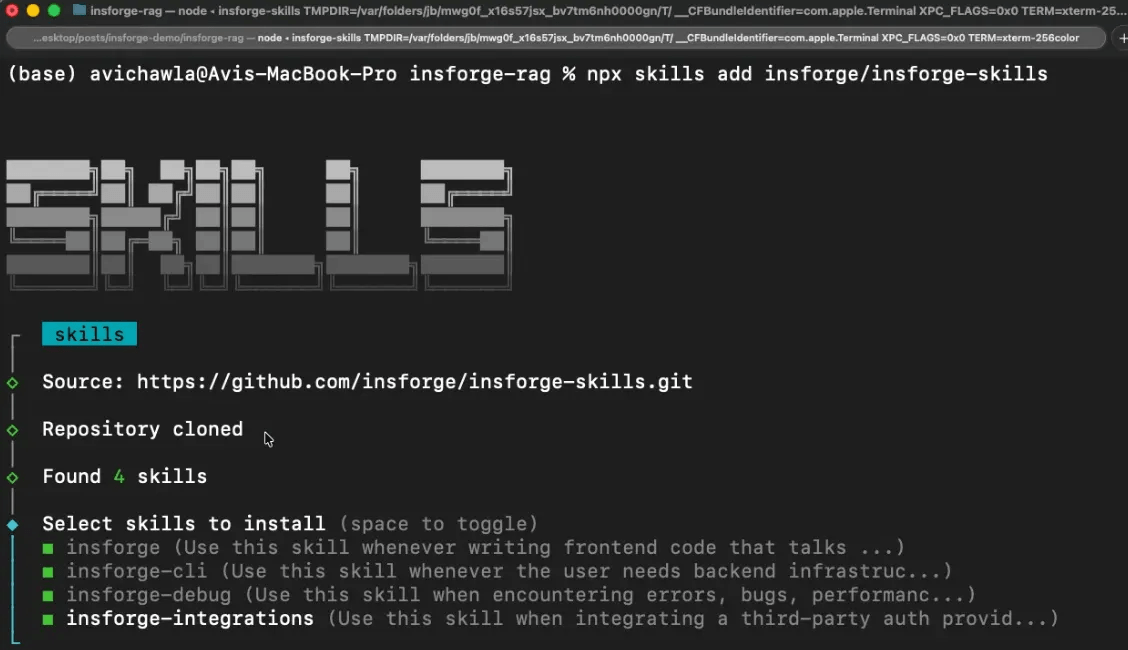
This installs insforge (SDK patterns), insforge-cli (infrastructure commands), insforge-debug (failure diagnostics), and insforge-integrations (third-party auth providers). Total metadata cost: ~714 tokens at session start.
Link the CLI to your project (primary execution layer):
npx @insforge/cli link --project-id <project-id>Building a Google Doc clone
This 10 hr video teaches how to build a Google Doc clone:
Ten hours of video means hundreds of implementation details like real-time collaboration, document state syncing, editor toolbar structure, and permissions.
That’s a lot of context that Claude Code will likely struggle to scrape. Even if it manages to scrape, compression will remove many of those details.
With both skills installed, here’s what you can do:
I want to build what's shown here:
https://www.youtube. com/watch?v=gq2bbDmSokU
Use Bright Data skills to scrape it and then
InsForge as the backend to implement.
Add Google OAuth and build a clean Google-doc
like interface. On every doc, add an "Ask AI"
button that chats with GPT-4o about the content.
Use InsForge's model gateway for the LLM capabilities.The video below depicts the whole build with the final app, built in one shot:
Bright Data scraped the full video content (transcript, metadata, structured descriptions), and Claude Code used it as the build spec.
InsForge handled the backend in one shot: Google OAuth, database schema with RLS, storage, edge functions, and the model gateway for GPT-4o chat through InsForge’s built-in functionalities.
Finally, it gave a working Google Docs clone with real-time editing, Google OAuth, and AI-powered document chat, built from a single prompt with zero errors.
The YouTube example is the simple case for the scraping side and this isn't limited to tutorials or building from scratch.
The same workflow applies to any technical content on the web, like:
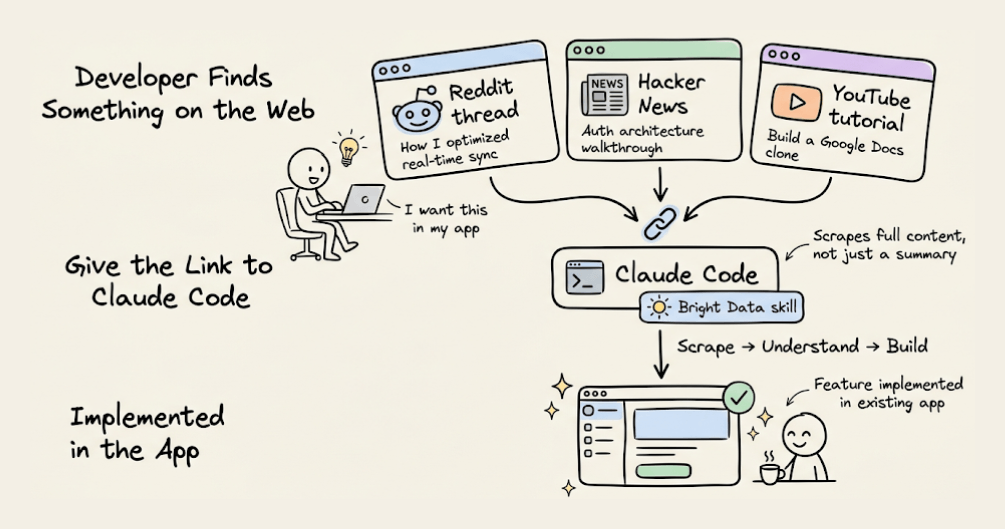
A Reddit thread where someone describes how they optimized their real-time sync.
A Hacker News discussion walking through an auth architecture.
A competitor's product page with a feature worth replicating.
Give the link to Claude Code with the Bright Data skill, and the agent scrapes the content, understands what was described, and implements it in the existing app.
So any technical content on the web can become a build spec.
For basic sources, native scraping tools work. Bright Data is essential with sources that actively resist scraping, like Reddit threads with aggressive rate limiting, Amazon product pages behind anti-bot detection, LinkedIn profiles that fingerprint your browser, and JavaScript SPAs that need full browser rendering to even load content.
👉 Over to you: what skills live in your default Claude Code setup?
Naive RAG vs Blockify
There’s a new RAG approach that:
cuts corpus size by 40x.
reduces tokens per query by 3x.
improves vector search relevance by 2.3x.
And it delivered 260% accuracy improvement on the medical RAG benchmark over standard RAG.
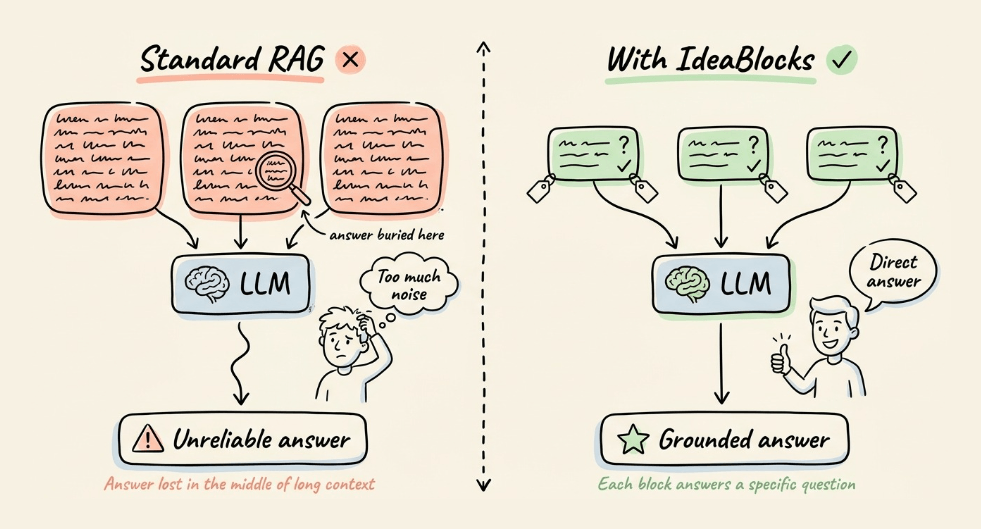
The diagram compares it with naive RAG:
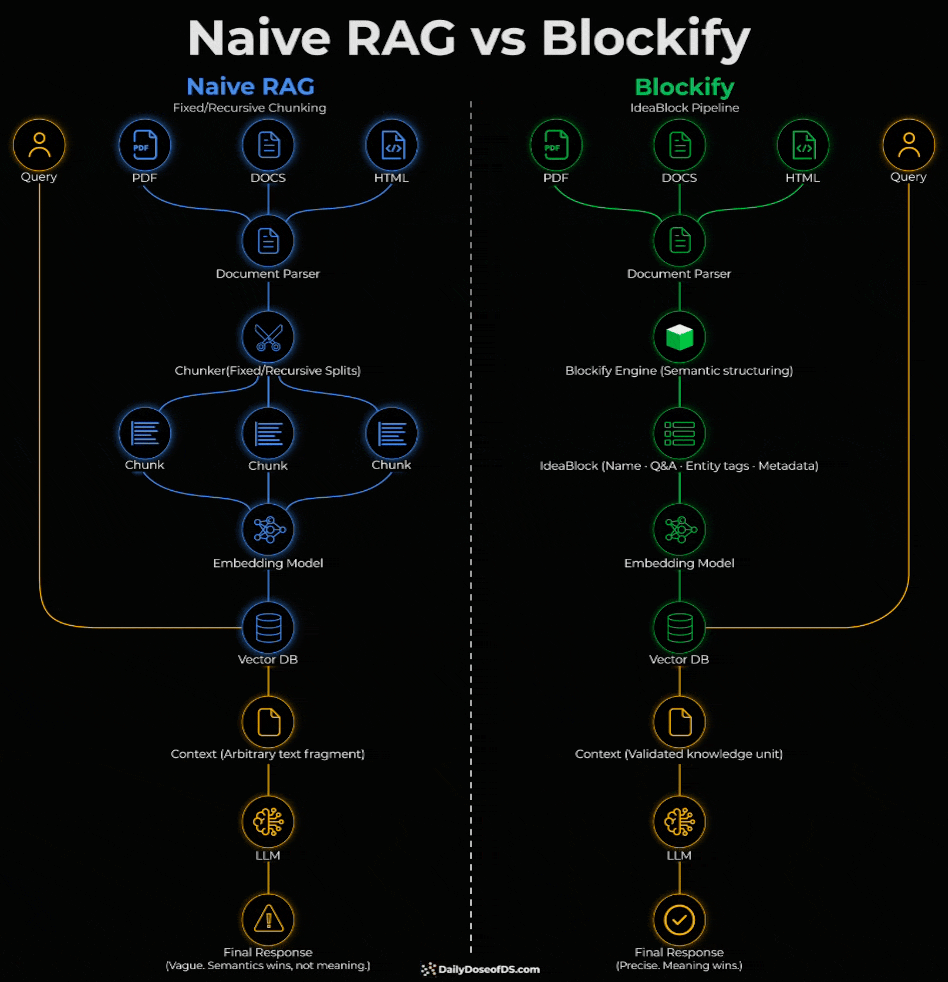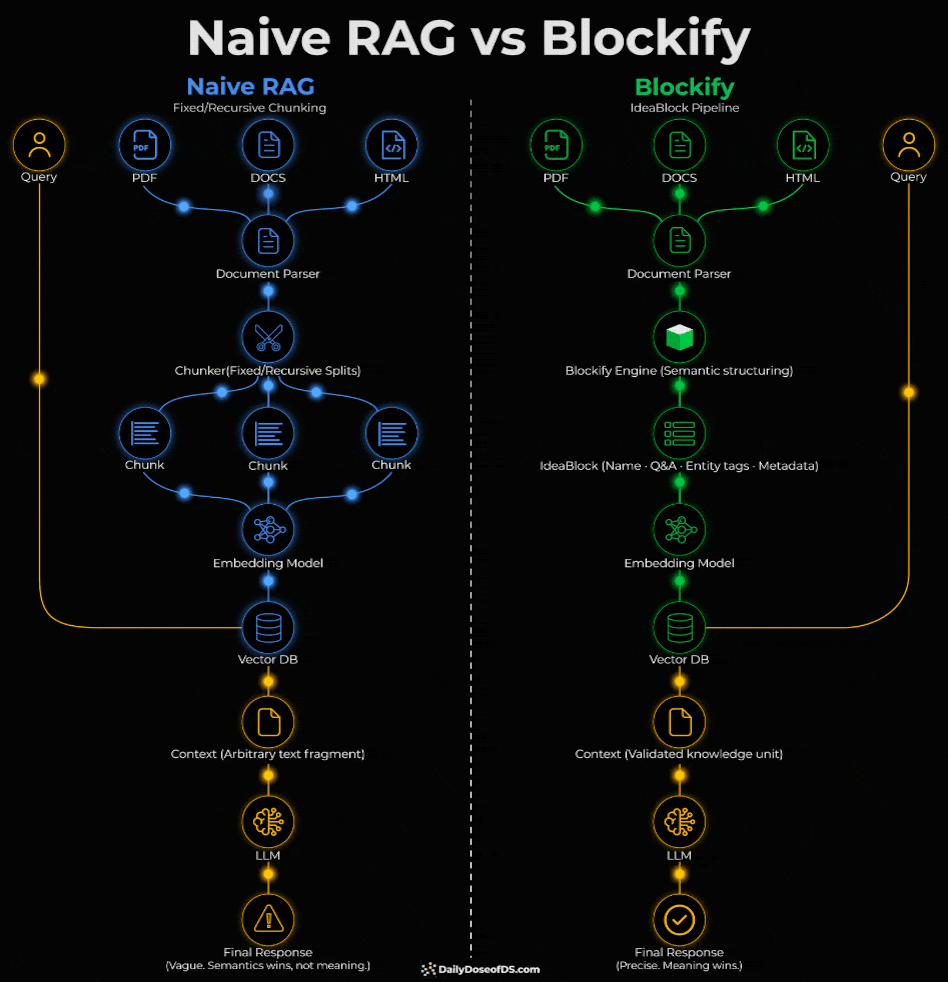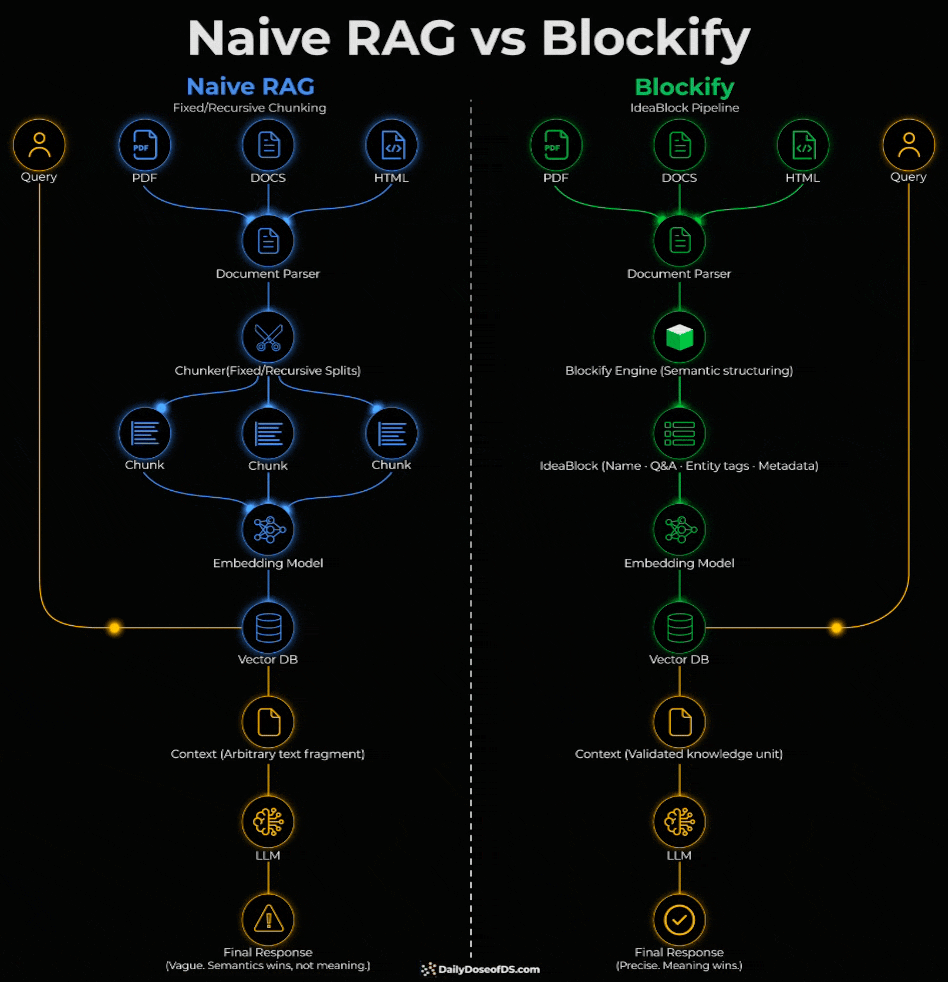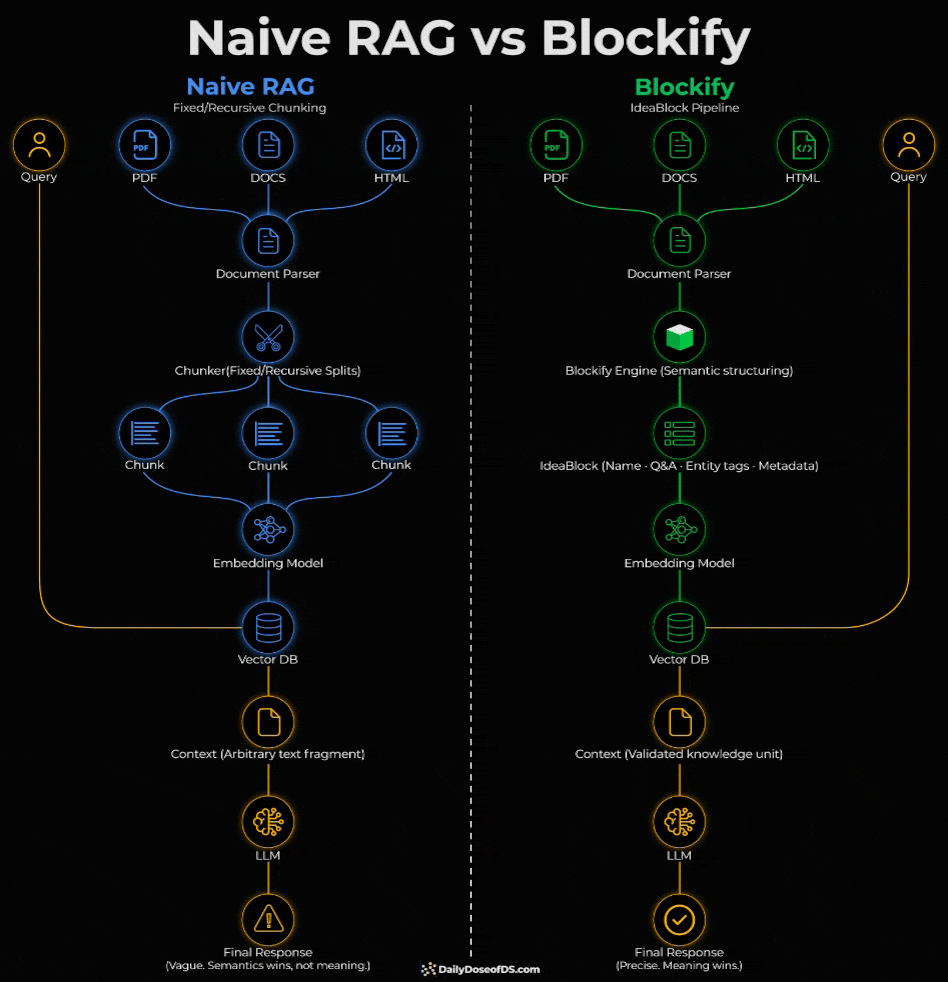
Chunks in a standard RAG pipeline typically carry no info about version, clearance level, or source authority.
The embedding model encodes it the same way regardless of whether the chunk is an outdated draft or the latest approved version.
During retrieval, if an outdated chunk and a latest chunk get retrieved as context, the LLM has no signal to prefer one over the other.
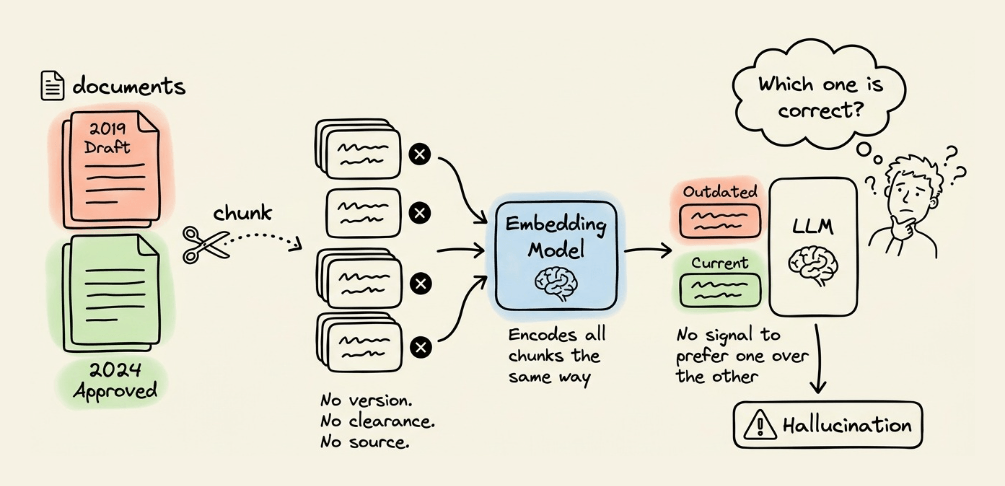
So it combines both and hallucinates.
The issue is not retrieval but rather the representation. The unit itself is wrong, and the fix has to happen before retrieval, at the data layer.
Blockify is an open-source data preprocessing engine that solves this at the data layer.
The engine sits between the document parser and the vector store.
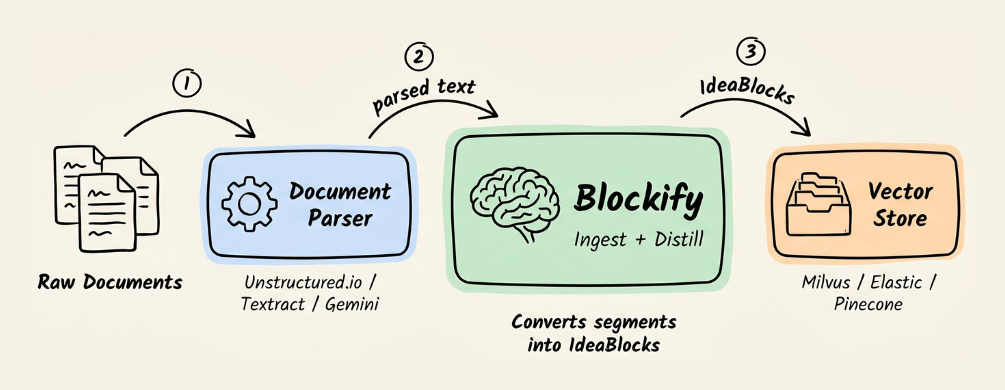
Here’s how it works:
First, a context-aware splitter finds natural breaks (paragraph boundaries, section breaks, topic shifts).
Instead of embedding raw segments directly, a purpose-built LLM processes each one and extracts structured knowledge units called IdeaBlocks (typically 2-3 sentences). Each unit isolates a different fact or concept.
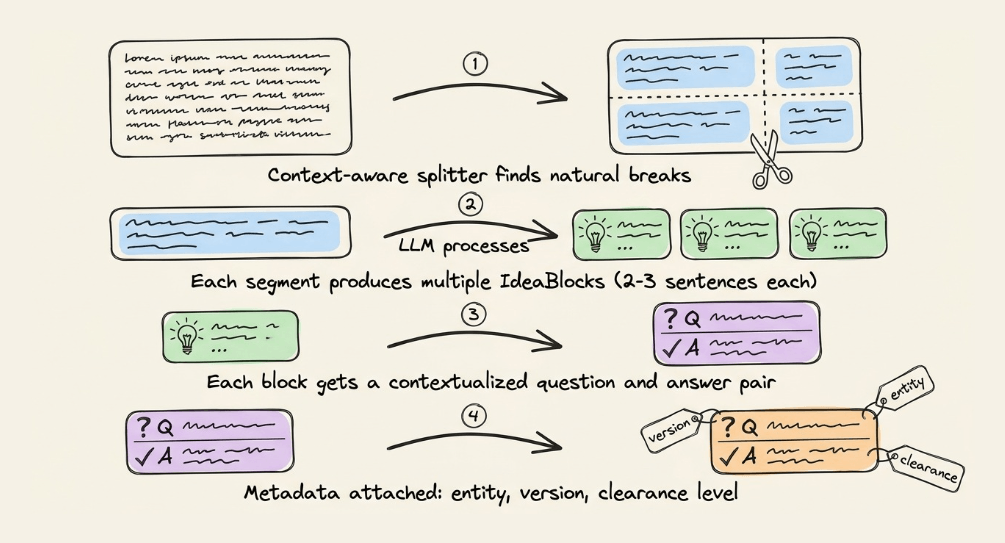
Each unit is paired with a contextualized question and answer. This mirrors how users query the system and ensures the query embedding sits closer to real queries in the vector space (HyDE does something similar).
Each block also carries metadata info like entity name, entity type, version, and clearance level. This helps rank retrieval by recency and authority, not just similarity.
The pipeline runs in two stages.
The Ingest model converts raw text into IdeaBlocks as described above.
The Distill model then clusters semantically similar blocks across the full set and merges duplicates into one canonical unit before indexing.
The retrieved units now answer a specific question instead of returning a paragraph that might contain the answer somewhere in the middle.
On the published benchmarks:
The pipeline reduces a corpus to roughly 2.5% of its original size while preserving 99% factual integrity.
Token consumption per query drops by 3x, from 1.5k tokens (naive top-5 chunks) to 500 tokens (top-5 IdeaBlocks).
Vector search relevance improves 2.3x, measured by cosine distance.
In medical evaluation, the same pipeline delivered up to 650% accuracy improvement on clinical-grade RAG with a quantized Llama 3.2 3B model running on-device.
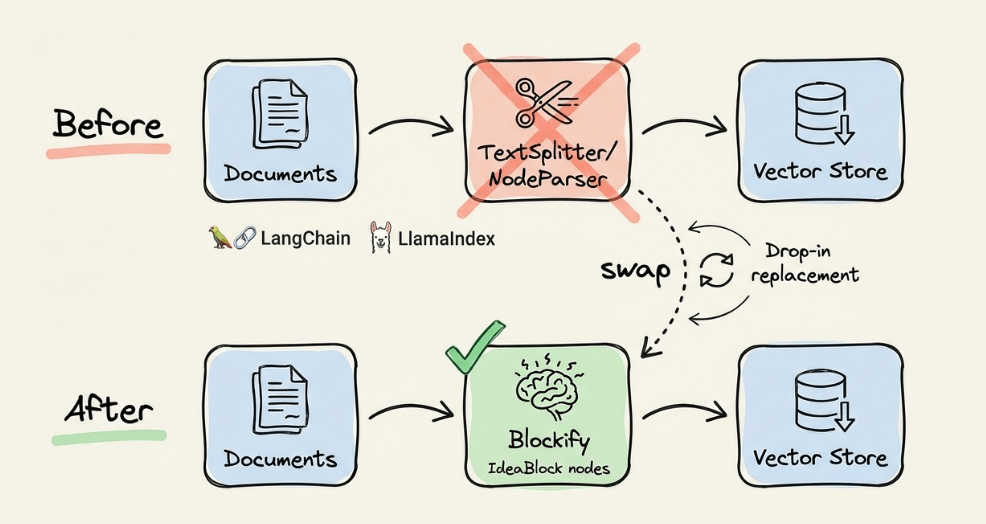
Blockify composes with LangChain and LlamaIndex. You can swap out the chunking stage (NodeParser/TextSplitter) and produce IdeaBlock nodes that the rest of the pipeline consumes normally.
For storage, you can integrate it directly with most vector DBs like Milvus, Elastic, etc.
There is also a Claude Code skill in the repo that runs the full Ingest and Distill pipeline while referencing the project documentation.
For production workloads on Intel Xeon, an optimized build is available through OpenVINO.
Thanks for reading!