
Use The "Two Questions Technique" To Never Struggle With TP, TN, FP and FN Again
An intuitive guide to binary classification prediction labeling.

When we build any binary classification model, it is natural to create a confusion matrix:
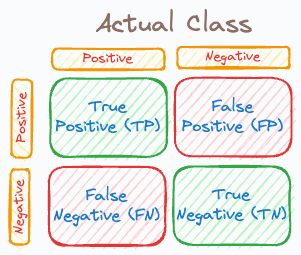
As depicted above, this matrix has four entries:
True positive (TP)
True negative (TN)
False positive (FP)
False negative (FN)
Of course, these terms are easy to remember, and I am sure you already know them.
However, I have seen many folks struggling to quickly and intuitively classify a prediction as one of TP, TN, FP, and FN.

Ever been there?
If yes, then today, let me share one of the simplest techniques I always use to classify predictions of a binary classification model.
I call it the “Two Questions Technique.”
Let’s understand what it is.
When labeling any binary classification prediction, you just need to ask these two questions:

Question 1) Did the model get it right?
Quite intuitively, the answer will be one of the following:
Yes (or True)
No (or False).
Question 2) What was the predicted class?
The answer will be:
Positive, or
Negative
Next, just combine the above two answers to get the final label.
And you’re done!
For instance, say the actual and predicted class were positive.

Question 1) Did the model get it right?
Of course, it did.
So the answer is yes (or TRUE).
Question 2) What was the predicted class?
The answer is POSITIVE.
The final label: TRUE POSITIVE.
Simple, right?
The following visual neatly summarizes this:

As an exercise, try to complete the table below.
Consider:
The cat class → Positive.
The dog class → Negative.

Let me know your answer in the comments.
👉 Over to you: Do you know any other special techniques to label binary classification predictions? Let me know :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Formulating and Implementing the t-SNE Algorithm From Scratch.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Wow nice 🙂