
Vanna: The Supercharged Text-to-SQL Tool All Data Scientists Were Looking For
Write complex SQL in seconds.

In my opinion, text-to-SQL tools are one of the most powerful utilities for data scientists.
Yet, my past experience with several text-to-SQL tools has been pretty dissatisfying.
For instance, most text-to-SQL tools:
Use static and standard pre-trained models.
Struggle to produce correct SQL queries on complex prompts.
Have limited fine-tuning support.
Can not naturally adapt to text queries and user feedback on outputted SQL queries.
Have limited compatibility with databases like Snowflake, Redshift, etc.
Recently, I learned about Vanna, which addresses each of these limitations.
Let’s understand this today and how you can use it in your projects.
To begin, Vanna is a Python-based open-source text-to-SQL tool that can write complex SQL in seconds.

But with more exploration, I realized that it’s much more than just being a text-to-SQL tool.
In contrast to traditional tools, Vanna can be:
fine-tuned to your database (a big plus)
connected to several databases (a big plus)
Snowflake
BigQuery
Redshift
Postgres etc.

connected directly to Slack, where you can provide text prompts in the chat to get SQL output (a great utility feature, especially for teams):


What’s more, Vanna continuously adapts to new data. Thus, the more you use it, the better it gets.
Once you query your database with a text prompt, Vanna produces four outputs:

The SQL query.
The corresponding Pandas DataFrame.
An AI-suggested visualization of that DataFrame.
AI-recommended follow-up text prompts.
Isn’t that cool?
Let’s see how we can use Vanna directly in a Jupyter Notebook!
First, we install the open-source Vanna package via
pip:

Next, get your free API key from Vanna (make sure you have created an account here: Vanna):

Before querying any database, we must set a name for the text-to-SQL model. The name could be:
An existing model that you may have fine-tuned in the past.
A new model that you intend to train now.
A publically available model.
Here, let’s use the basic “chinook” model provided by Vanna, which is fine-tuned on a dataset of music sales and stuff:

Here’s the database schema:

To query a database, we must connect to it. This is done as follows:

Do note that here we have connected to a SQLite database but as discussed above, Vanna can also connect to:
Snowflake
Postgres
Bigquery
Done!
Now, we can query our database with text prompts.
I intentionally gave it a complex query that will involve multiple joins:
Retrieve a list of customers who have made at least one purchase. Include their contact information, the total amount they’ve spent, the number of purchases, the average order value, and their most frequently purchased track_id.
And here’s the result, which, in fact, is correct:
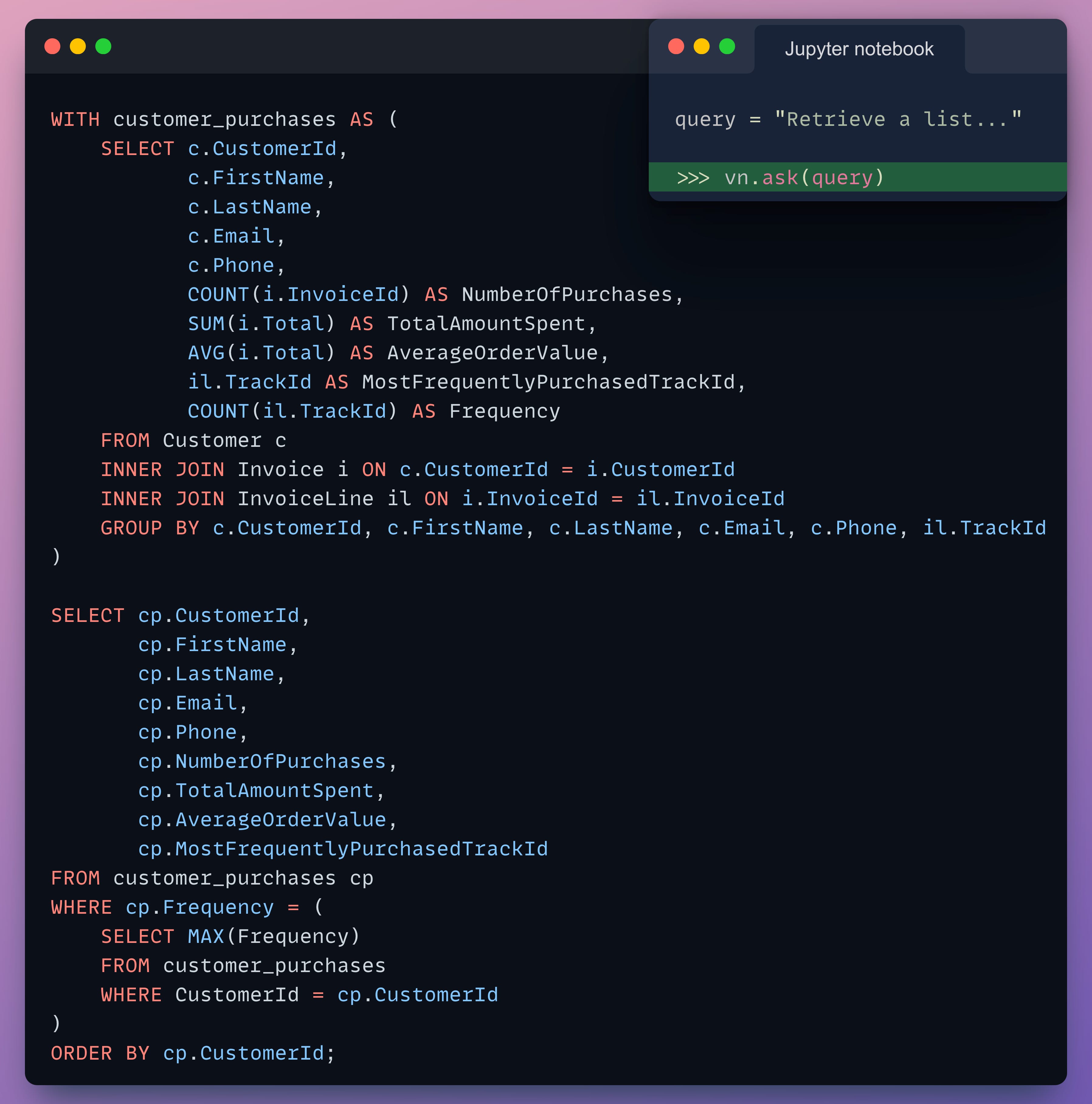
First, it creates a CTE by joining the necessary tables.
Next, it selects the most frequently purchased
track_idof each customer by filtering the CTE results.
This proves that Vanna:
is data-aware.
can analyze and produce SQL queries even with complex prompts.
understands the database schema.
Isn’t that cool?
If needed, you can also train your own text-to-SQL model.
To do so, we first define the model using vn.set_model().

There are three ways to train this model:
Train with DDL statements:

Train with your database documentation:

Train with your previously written SQL queries:

Super convenient and cool, right?
I prepared this practice notebook to help you get started: Vanna practice notebook.
👉 Over to you: What are some other cool text-to-SQL tools you are aware of?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
This is a great elaboration upon your LinkedIn post. This seems like an exciting development, as I have been really struggling to find solutions that help AI work with Tabular Numerical data. I love the animated graphic.