
Vector Index vs Vector Database
...explained visually!

Extract any info from the web with a prompt!
Firecrawl’s latest /agent endpoint lets you just describe what you need (with or without a URL), and then it searches, navigates, and gathers information from the widest range of websites, reaching data no other API can.
It accomplishes in minutes what would take you hours or days of manual work.
Think of it as deep research for datasets.
You can try it out in the research preview here →
Thanks to Firecrawl for partnering today!
Vector Index vs Vector Database
Devs typically use the terms Vector Index and Vector Database interchangeably.
But that’s a mistake.
We put together this visual which summarizes the difference:
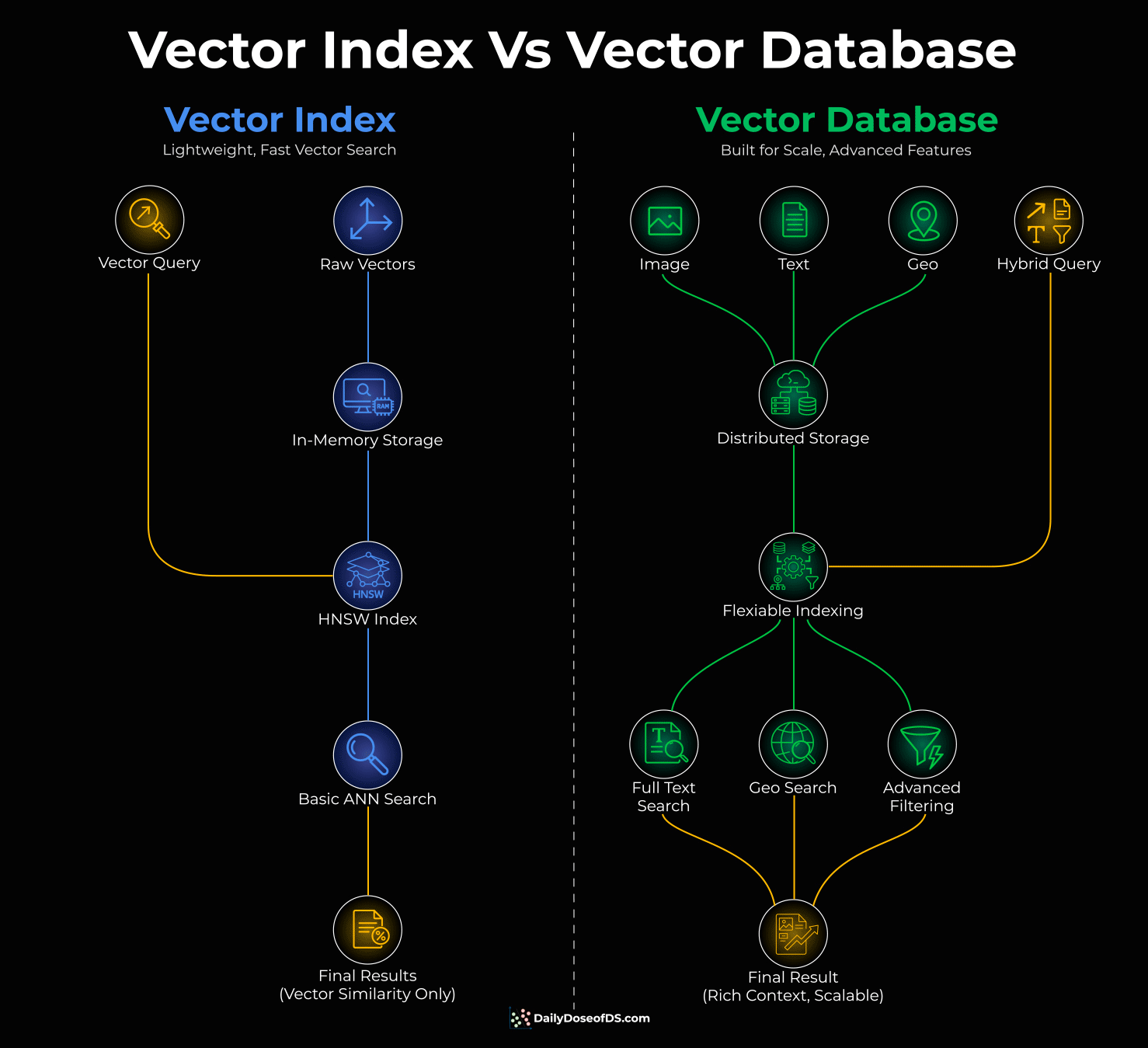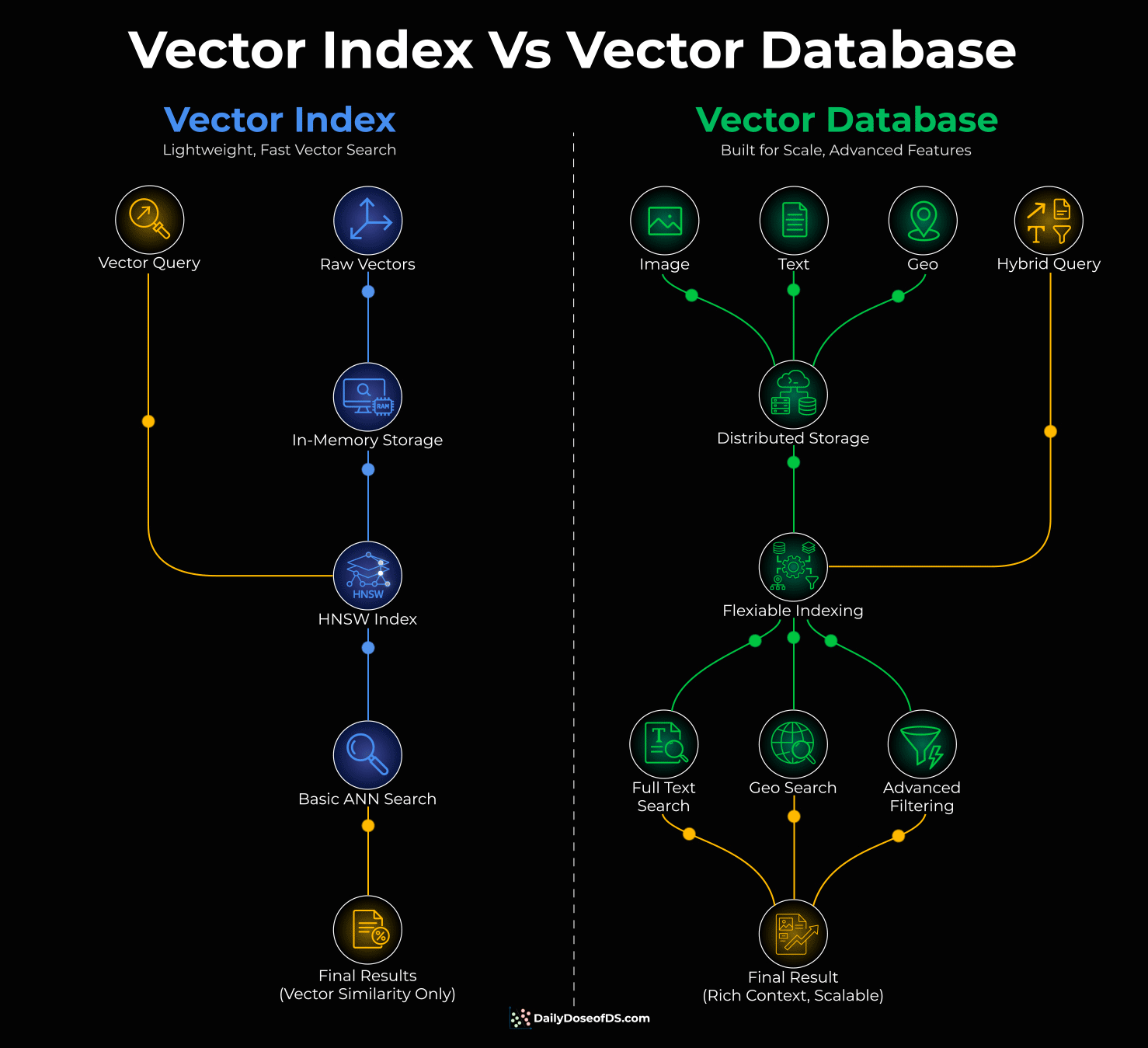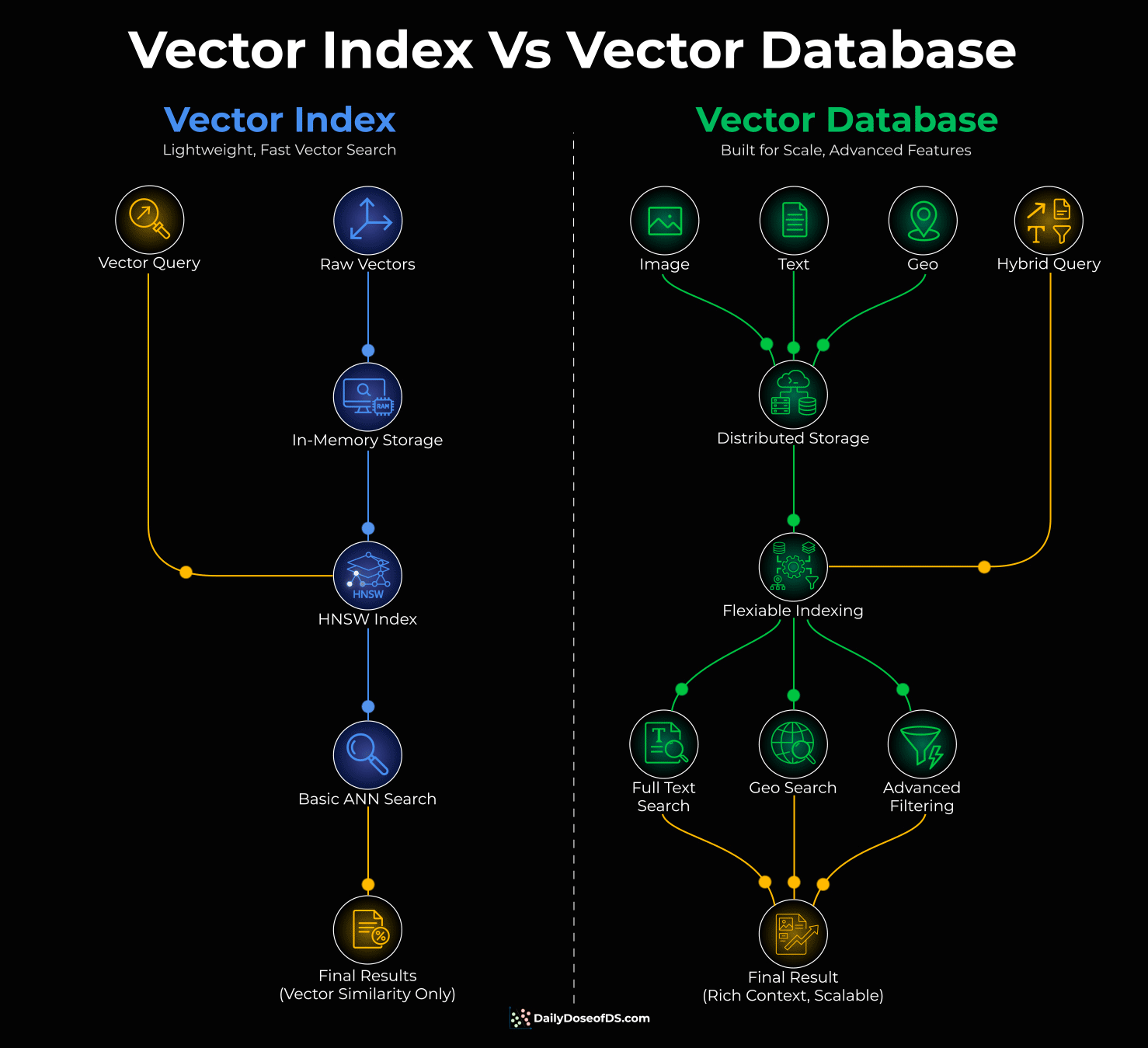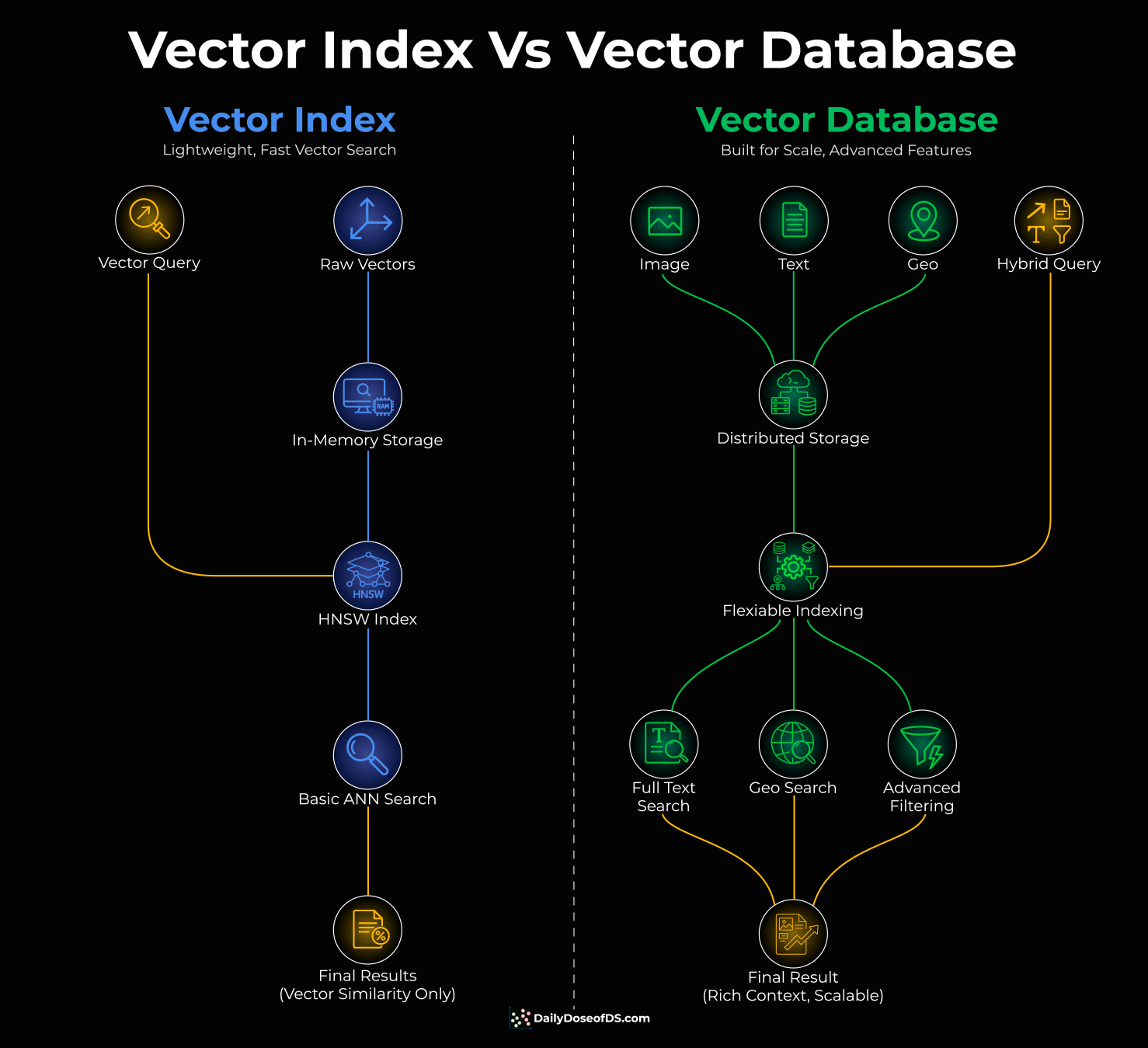
Think of it this way:
A vector index is an algorithm. It takes your vectors, organizes them into a searchable structure (like HNSW), and finds similar items fast. FAISS is a good example.
But an algorithm alone doesn’t handle storage, filtering, or scale. It just searches.
A vector database wraps that index with everything else you need, like distributed storage, metadata filtering, persistence, and concurrent access.
It also gives you flexibility in how you index. HNSW, IVF, DiskANN - different techniques for different tradeoffs between speed, accuracy, and memory. Milvus is a good example.
So, one is a component. The other is a system.
This distinction feels academic until you hit scale. Then it becomes expensive.
An autonomous driving company learned this the hard way.
They were building a search system for driving footage at massive scale. Every trip generates frames; each frame becomes a vector embedding.
Engineers needed to query scenarios like “nighttime urban intersections with pedestrians” across months of data.
FAISS was the natural starting point because it was fast, lightweight, and easy to set up.
But as data grew, each day’s embeddings became a separate index file.
Months later, they had hundreds of thousands of isolated files.
Searching across multiple days meant accessing many files simultaneously. Queries like “front-facing camera in light rain on urban roads” required custom databases, query planners, and filtering logic built around FAISS.
This is exactly where vector databases come in and why the company migrated to Milvus.

The difference was immediate:
Single queries combine vector similarity with metadata filters
Data organized into collections and partitions, not scattered files
Tens of billions of vectors, over a year in production, zero major incidents
30% infrastructure cost reduction
10x proven scalability headroom
This isn’t a unique problem. Most enterprises hit the same wall when they start with a lightweight index, then scramble when they need filtering, persistence, or scale.
Vector databases exist precisely for this transition.
What makes Milvus stand out is how it handles scale and data diversity.
Billions of vectors, horizontal scaling, and specialized indexes for different data types, like geographical data like latitude and longitude, gets its own optimized index, not a generic one-size-fits-all approach.
It’s 100% open-source (41k+ stars), and you can self-host the entire thing or use their cloud offering directly.
Thanks for reading!