
Verifiable Rewards and GRPO in RL
The full RL nanodegree, covered with implementation.

Part 10 of the Reinforcement Learning course is available now.
It covers GRPO, the algorithm behind DeepSeek-R1, and a growing number of reasoning models. It picks up exactly where the RLHF chapter left off and asks, what if you do not need a learned reward model or a critic at all?
You can read Part 10 of the course here →
It covers:

Using verifiers instead of learned reward models
Designing reward functions for verifiable tasks
Why the critic becomes optional with cheap rewards
The GRPO algorithm and group-relative advantages
How PPO, DPO, and GRPO compare
Trade-offs, including length bias and scope limits
Hands-on GRPO training on math problems with Unsloth
Everything is covered from scratch, so no RL background is required.
You can read Part 10 of the course here →
Why care?
DeepSeek-R1 demonstrated a tangible shift in post-training.
A model trained with GRPO and verifiable rewards developed strong reasoning capabilities, including chain-of-thought behavior that emerged purely from the RL process, without any supervised demonstrations of reasoning.
The four-model RLHF setup from the previous chapter (policy, reference, reward model, critic) collapsed to just two.

The memory cost of running four large models simultaneously was one of the biggest barriers to doing RLHF at scale. GRPO removed two of them.
It also matters conceptually. For any task where correctness is checkable (math, code, formal logic), a verifier gives an exact, unhackable signal.
The reward is grounded in fact, not in a model’s approximation of human judgment, leading to far better training.
This chapter covers the full picture, from the reward design to the GRPO objective, to a hands-on training run where you fine-tune a model to solve math problems using verifiable rewards.
Here’s what we have covered so far:
Just like the MLOps course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
👉 Over to you: What topics would you like us to cover in this RL series?
Standard KG vs Zep’s temporal KG
When you employ a knowledge graph to serve as an agent’s memory layer, an LLM handles the extraction. It reads conversations and decides what entities to create, what relationships to track, and how to label everything.
Without any specific guidance, it labels everything generically.
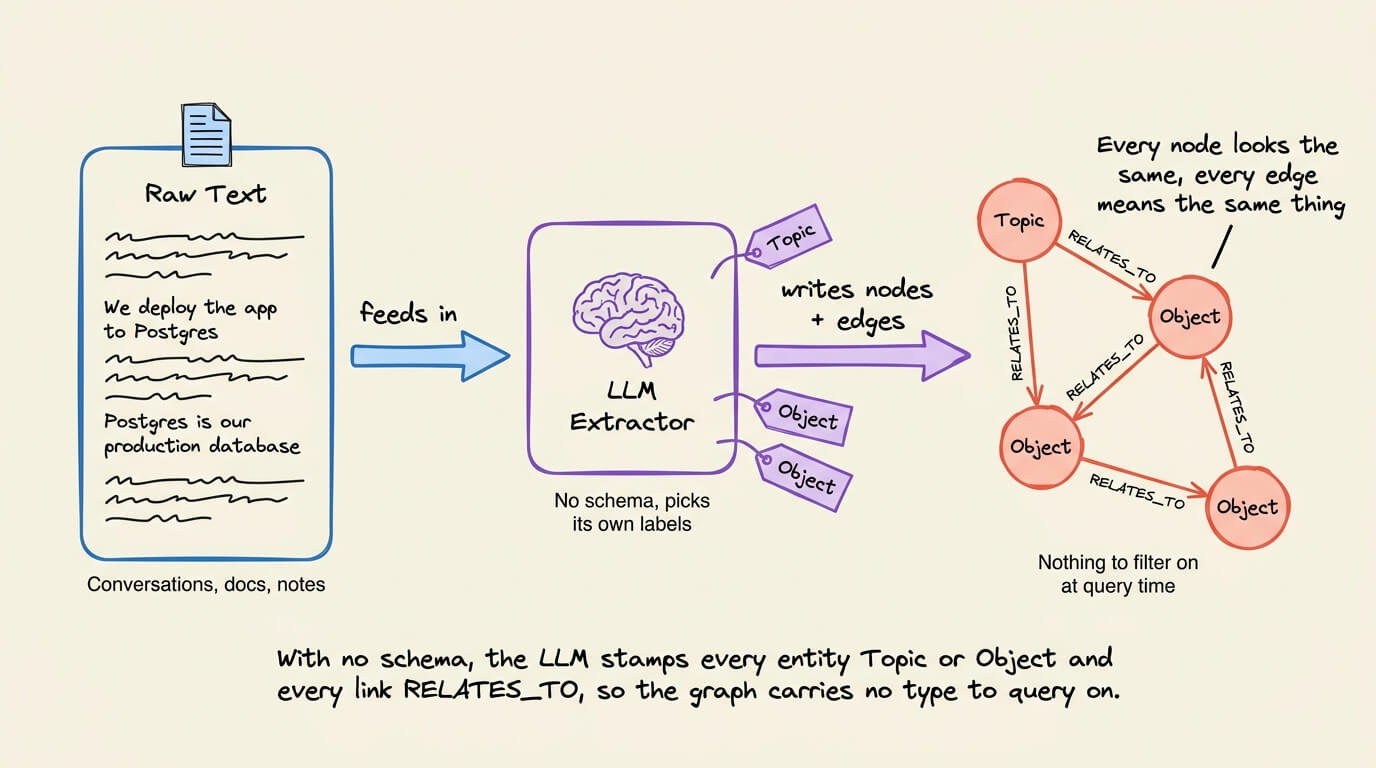
Project becomes a
Topic.Database becomes an
Object.The deployment tool becomes another
Object.Every relationship between them gets the same
RELATES_TOtag.
While the graph stores the right data, every node looks the same, and every edge means the same thing. So when the agent queries it, it starts looking like a similarity search across undifferentiated nodes.
Not only that, but facts change as well with time.
A user could switch tech stacks.
A customer could upgrade their plan.
A project could go from active to completed.
The old facts don’t leave the graph but rather sit there with the same weight as the current one, and the naive retrieval has no way to tell which version is true right now.
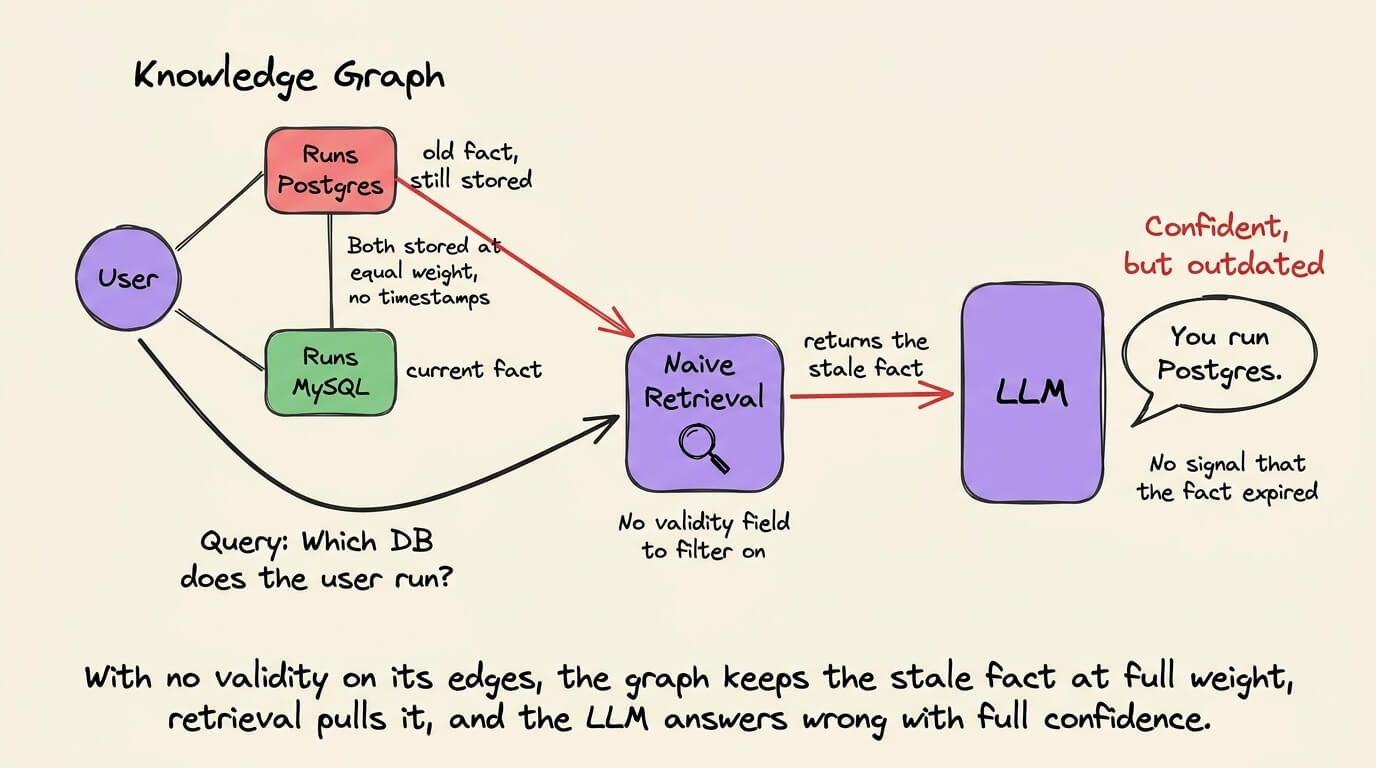
So the agent serves stale context with full confidence.
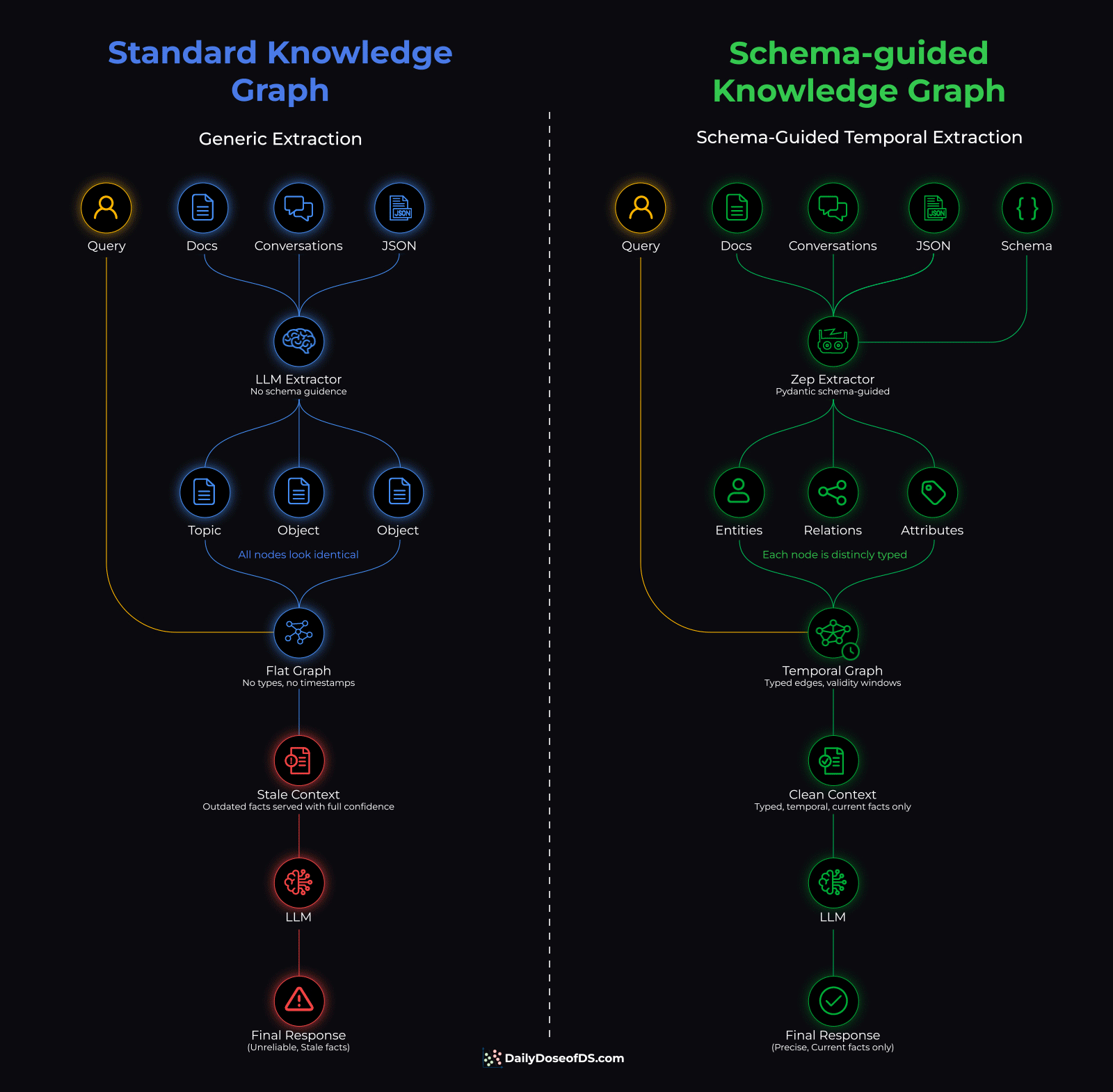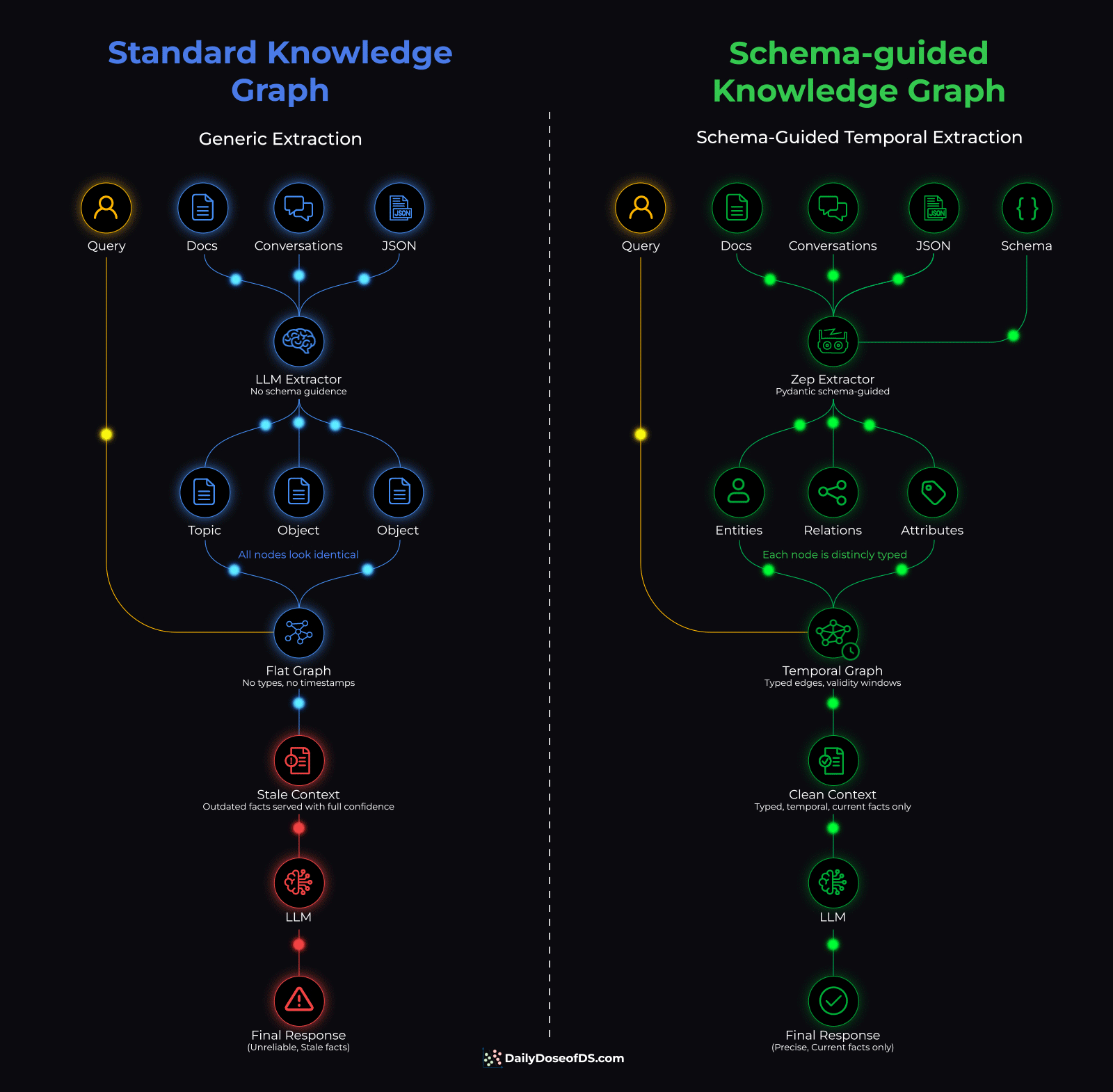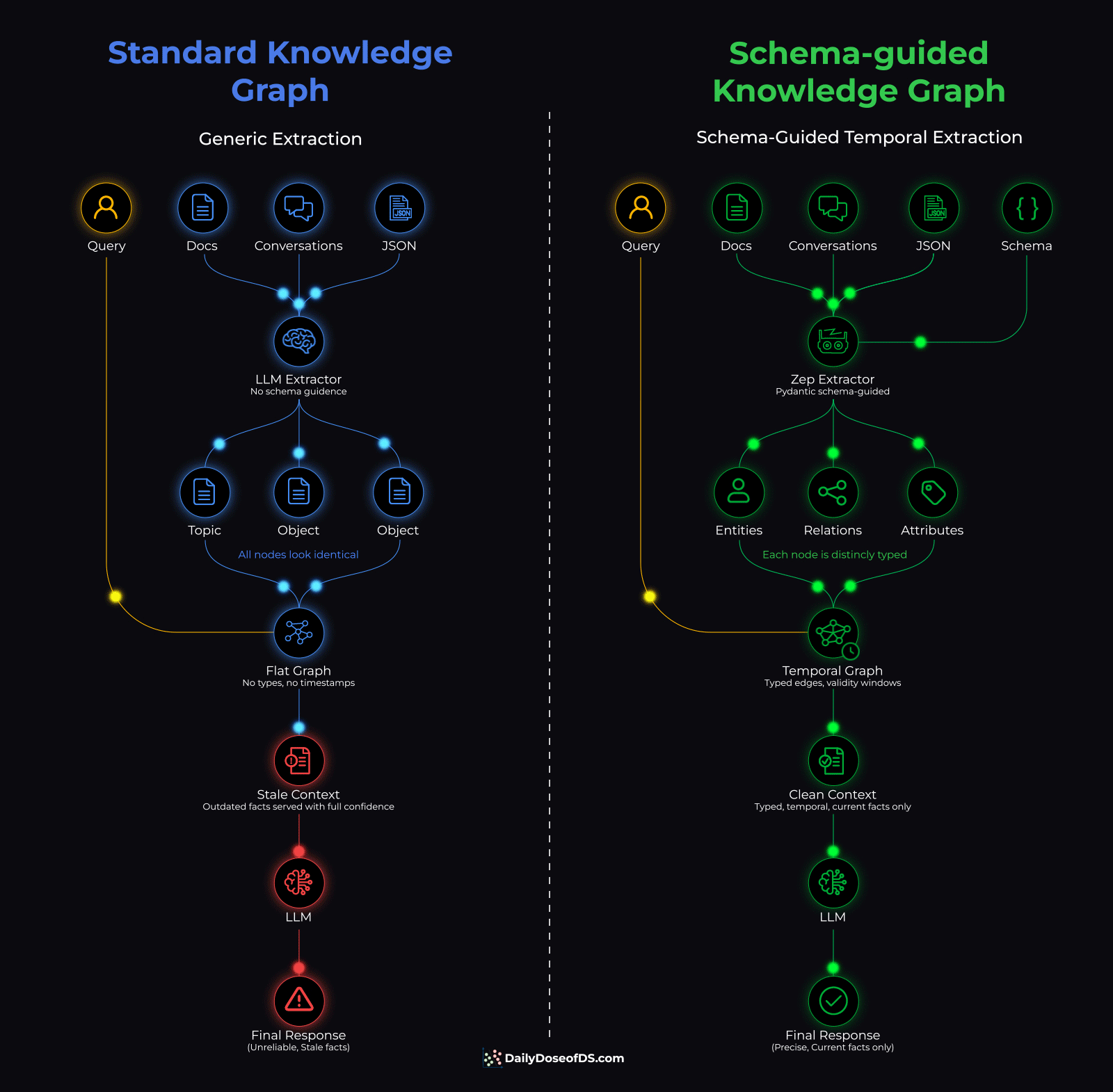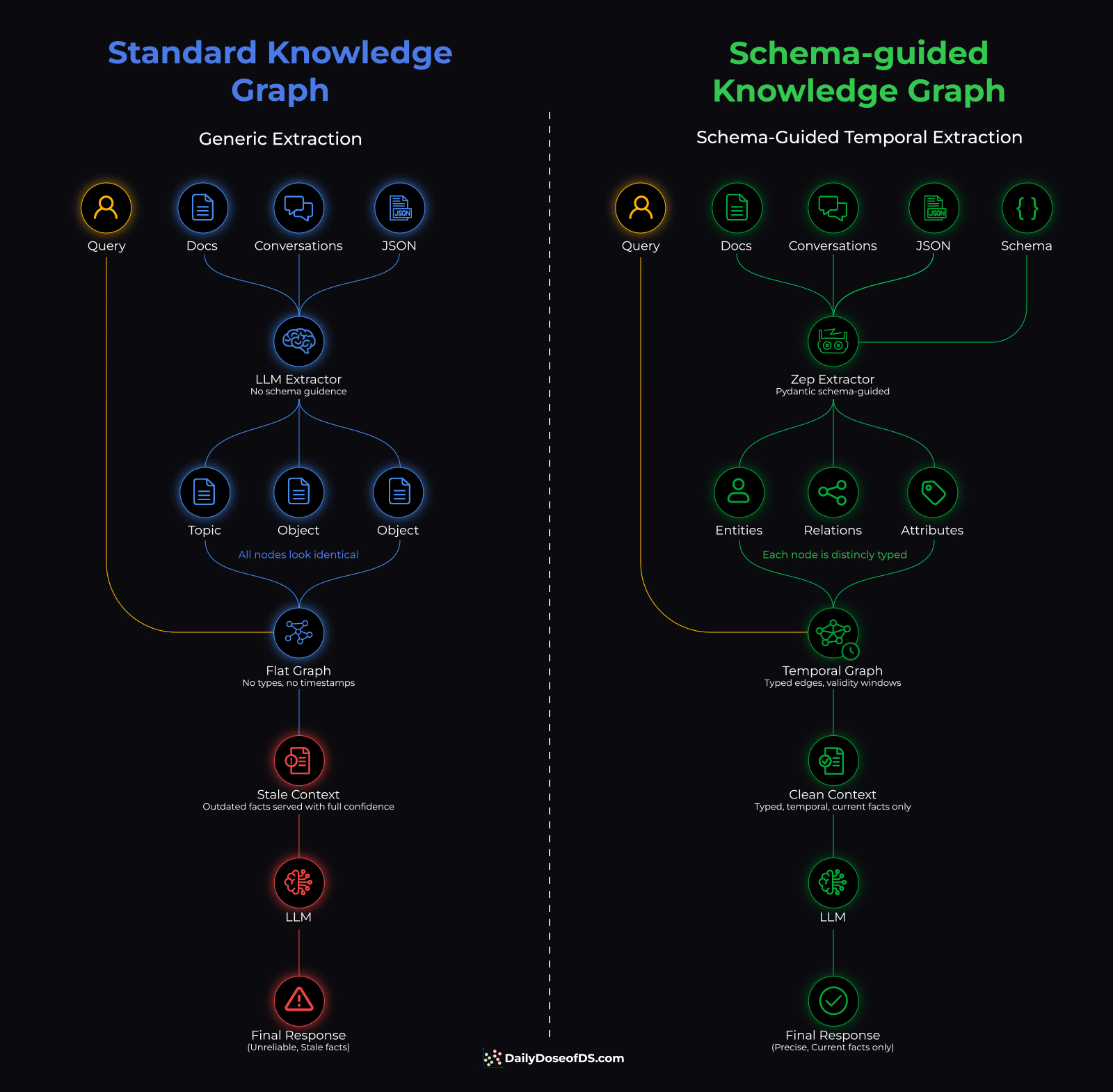
Zep Graphiti (open-source with 28k+ stars) solves both problems at once:
Start by defining the memory schema in Pydantic (entity types, edge types, attributes)
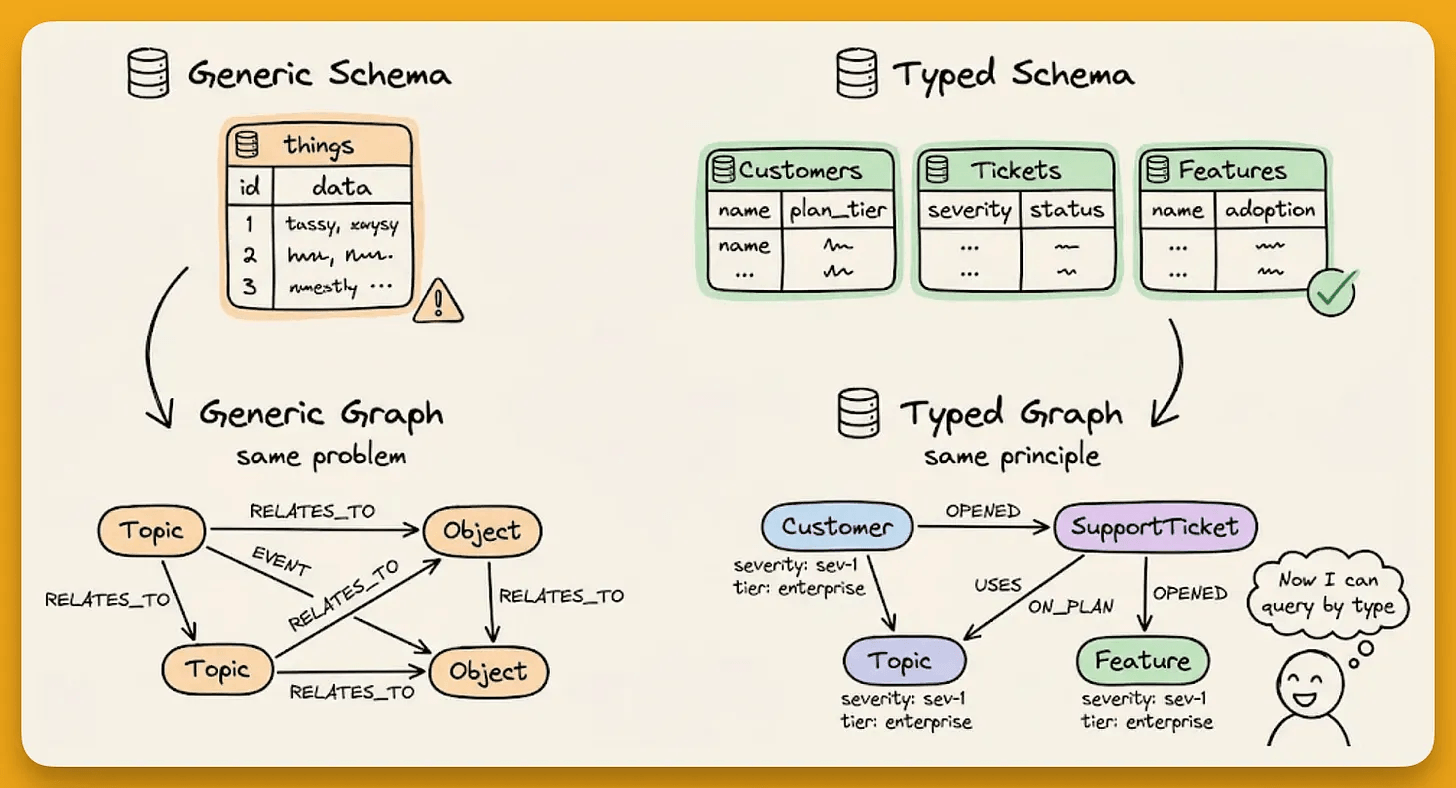
The extraction model extracts and creates a graph against these specified types, so every node gets a specific type and every edge carries structured attributes.
Contradiction detection invalidates outdated facts instead of keeping both
Temporal annotations track when each fact was true and when it stopped being true.
Once this is ready, then at query time, retrieval filters by temporal validity before similarity search. Also, every fact that reaches the agent is typed, current, and structured.
The diagram below shows the full pipeline comparing a standard knowledge graph and a schema-guided knowledge graph side by side:
If you want to see this in practice, we covered it here with code →
And here’s the Zep Graphiti open-source GitHub repo →
(don’t forget to star it ⭐️)
Good day!