
Visualising The Impact Of Regularisation Parameter
Intuitive explanation to regularisation.

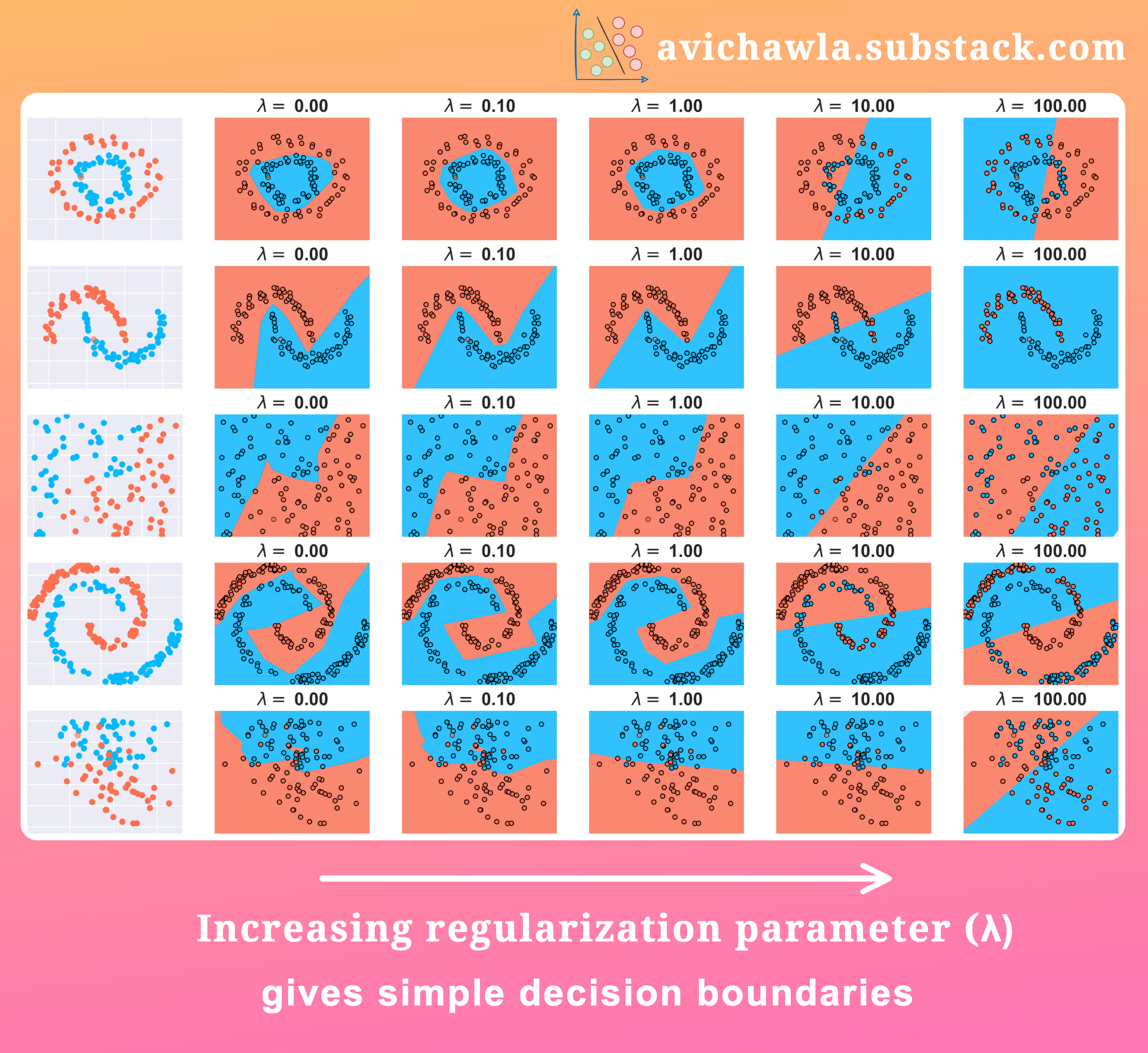
Regularization is commonly used to prevent overfitting. The above visual depicts the decision boundary obtained on various datasets by varying the regularization parameter.
As shown, increasing the parameter results in a decision boundary with fewer curvatures. Similarly, decreasing the parameter produces a more complicated decision boundary.
But have you ever wondered what goes on behind the scenes? Why does increasing the parameter force simpler decision boundaries?
To understand that, consider the cost function equation below (this is for regression though, but the idea stays the same for classification).
It is clear that the cost increases linearly with the parameter λ.

Now, if the parameter is too high, the penalty becomes higher too. Thus, to minimize its impact on the overall cost function, the network is forced to approach weights that are closer to zero.
This becomes evident if we print the final weights for one of the models, say one at the bottom right (last dataset, last model).

Having smaller weights effectively nullifies many neurons, producing a much simpler network. This prevents many complex transformations, that could have happened otherwise.
To understand more, I would highly recommend watching this video by Andrew Ng.
👉 Read what others are saying about this post on LinkedIn.
👉 Tell me you liked this post by leaving a heart react ❤️.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
Avi, I like your posts. I'm recommending my readers check your site out. Keep it up.